本站总访问量次
工具
作者:leftover
字数统计:16.5k 字
阅读时长:88 分钟
jps 查看所有的 Java 进程
jstack [pid] 查看某个 Java 进程当前时刻的线程信息
jconsole 可以查看 Java 运行时的内存,线程等情况
jcstress压力测试工具
javap -v xxx.class 命令:将某个 class 编译成字节码文件
jclasslib Bytecode Viewer插件可以用来查看类的字节码
并发和并行
并发是指多个任务交替执行。
并行是指多个任务同时进行
若系统中只有一个 cpu,那么在使用多线程时,那么真实系统环境下不能并行,只能通过切换时间片的方式交替进行,而成为并发执行任务 。只有多核 cpu 才能并行执行任务
线程上下文切换
导致现场上下文切换的原因:
- 线程 cpu 时间片用完
- 垃圾回收
- 有更高优先级的线程需要运行
- 线程自己调用了 sleep、yield、wait、join、park、synchronized、lock 等方法
上下文切换会导致用户态与内核态的切换,因此线程不是越多越好,频繁的上下文切换会影响性能
线程常见的方法
start vs run
start 方法,会判断一个线程是否是
NEW状态,若不是则说明线程已经 start 过,抛出异常(start 方法只能调用一次)
若是,则创建线程,在新的线程中调用 run 方法
调用 start 方法之后,线程会进入
RUNNABLE状态run 方法不会启动一个新线程,哪个线程调用了此方法就在哪个线程中执行。
若在构造 Thread 对象时传递了 Runnable 参数,则调用此方法会执行 Runnable 中的 run 方法,否则不会执行任何操作直接 return;
可以创建 Thread 的子类来重写此方法
sleep vs yield
sleep
- 调用 sleep 方法之后,当前线程会从
Running进入TIMED_WAITING状态 - 其他线程可以使用
interrupt方法打断正在睡眠的线程,这时候 sleep 方法会抛出InterruptedException异常,执行 catch 中的代码 - 建议使用
TimeUnit的 sleep 代替 Thread 的 sleep 来获得更好的可读性
java
TimeUnit.SECONDS.sleep(2);- 睡眠结束后的线程未必会立刻得到执行
java
@Slf4j
public class Sleep_yield {
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
try {
// Thread.sleep(2000);
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
log.info("wake up");
}
System.out.println(11);
}
}, "t1");
thread.start();
Thread.sleep(500);
// TIMED_WAITING
System.out.println(thread.getState());
log.info("interrupt");
// 打断t1线程
thread.interrupt();
}
}yield
yield有退让,谦让的意思,调用 yeild 方法会让那个当前线程从 Running 进入 Ready 状态,但是,需要注意的是,让出的 CPU 并不是代表当前线程不再运行了,如果在下一次竞争中,又获得了 CPU 时间片当前线程依然会继续运行。另外,让出的时间片只会分配给当前线程相同优先级的线程
sleep vs wait
- sleep 是 Thread 类上面的方法,而 wait 是 Object 类上的方法
- sleep 不需要强制和 synchronized 配合使用,而 wait 需要和 synchronized 一起使用(需要先获取到锁)
- sleep 在睡眠的同时只会释放 cpu,不会释放对象锁;而 wait 在等待的时候会释放 cpu 和对象锁
- 调用之后线程都会进入
WAITING或者TIMED_WAITING状态
park vs wait
- wait,notify,notifyAll 必须配合 synchronized 一起使用,而 park ,unpark 不必
- park、unpark 是以线程为单位来阻塞和唤醒线程,而 notify 只能随机唤醒一个等待线程,notifyAll 是幻想所有的等待线程
- park & unpark 可以先 unpark,而 wait & notify 不能先 notify(先调用 notify 再执行 wait 还是会阻塞)
join
调用 join 方法,若传了时间 N,则主线程最多会等待 N ms(子线程提前结束,则不会继续等待)
若没有传时间,则会一直等到子线程执行完毕之后再往下执行
join 底层是使用的 wait 方法实现的
java
public class Join {
static int num = 0;
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new Runnable() {
@SneakyThrows
@Override
public void run() {
TimeUnit.SECONDS.sleep(1);
num = 10;
}
}, "t1");
thread.start();
// 等待子线程执行完毕
thread.join();
System.out.println(num); // 10
}
}interrupt
- 用来打断线程
如果被打断的线程正在
sleep,wait,join,则会导致被打断的线程抛出InterruptedException,并清除打断标记,interrupted = false如果被打断的是
正在运行的线程,则会设置打断标记,interrupted = true被打断的是
正在park的线程,也会设置打断标记,interrupted = true, 之后这个线程再执行 park 方法则不会阻塞,需要清除打断标记后再执行 park 方法才会阻塞
isInterrupted()方法可以判断是否被打断,
return interruptedinterrupted() 方法返回当前线程的打断标记,并清除打断标记,interrupted =false
两阶段终止(interrupt)
在线程 T1 中如何优雅地终止线程 T2? 这里【优雅】指的是给 T2 一个处理后事的机会(退出前执行一些逻辑)
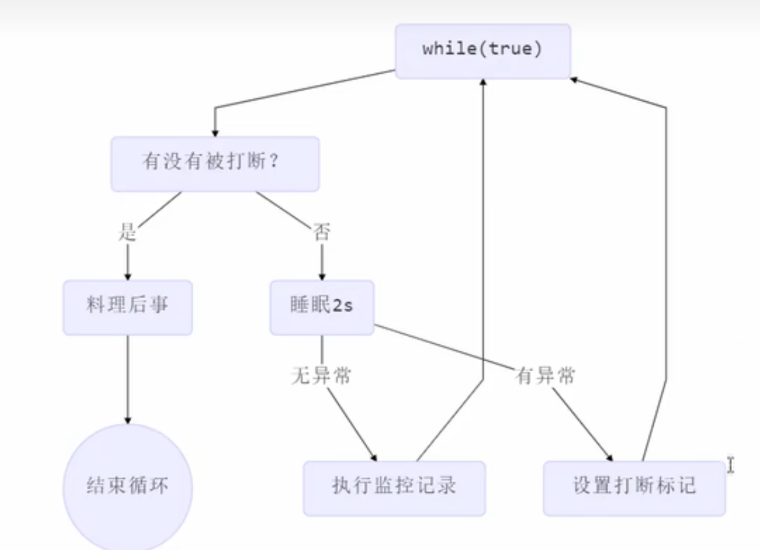
java
@Slf4j
public class Monitor {
private static Thread monitor;
public void stop() {
monitor.interrupt();
monitor.stop();
}
public void beforeExit() {
log.info("处理后事");
}
public void start() throws InterruptedException {
monitor = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
// 只有在监控时被打断了才会退出,睡眠时被打断了不会退出
if (monitor.isInterrupted()) {
beforeExit();
break;
} else {
try {
log.info("监控系统。。。");
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
// 在睡眠期间被打断
e.printStackTrace();
// 清除打断标记
Thread.interrupted();
/**
如果只是想要在退出前运行一些代码的话,也可以这样
即无论是否在睡眠时还是在监控时被打断,都会退出
e.printStackTrace();
beforeExit();
break;
*/
}
}
}
}
});
monitor.start();
TimeUnit.SECONDS.sleep(1);
monitor.interrupt();
}
public static void main(String[] args) throws InterruptedException {
new Monitor().start();
}
}过时的方法
这些方法容易破环同步代码块,造成线程死锁
- stop :停止线程运行 (使用两阶段终止(interrupt)替代)
- suspend: 将线程挂起(使用 wait 替代)
- resume: 恢复线程继续运行(使用 notify 替代)
守护线程
默认情况下,Java 进程需要等待所有线程都运行结束,才会结束。有一种特殊的线程叫守护线程,只要其他非守护线程运行结束了,即使守护线程的代码没有执行完,也会强制结束。
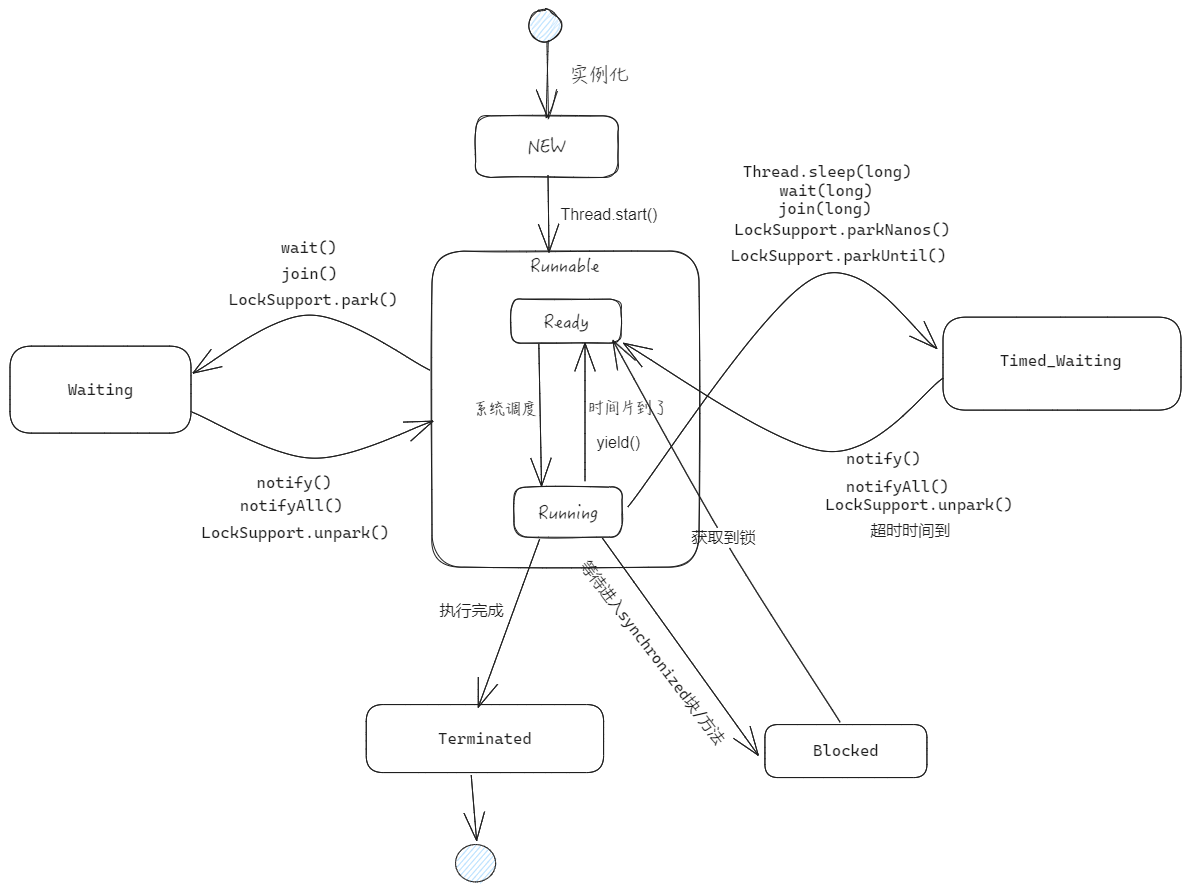
线程的状态
JUC 中使用了一个枚举类定一个线程的状态
- NEW: 线程刚创建。还没调用 start 方法
- RUNNABLE:运行状态。Java 线程将操作系统中的就绪(Ready)和运行(Running)两种状态笼统地称为 Runnable 状态
- WAITING:等待状态。进入该状态表示当前线程需要等待其他线程做出一些特定特作(notify 或者 interrupt)
- TIMED_WAITING: 超时等待状态,该状态不同于 WAITING,它是可以在指定的时间自行返回的
- BLOCK:阻塞状态。当线程出现资源竞争时,即等待获取锁的时候,线程会进入到BLOCKED阻塞状态,当线程获取到了锁,会进入 Runnable 状态(Ready 状态)
- TERMINATED:终止状态。表示当前线程已经执行完毕了
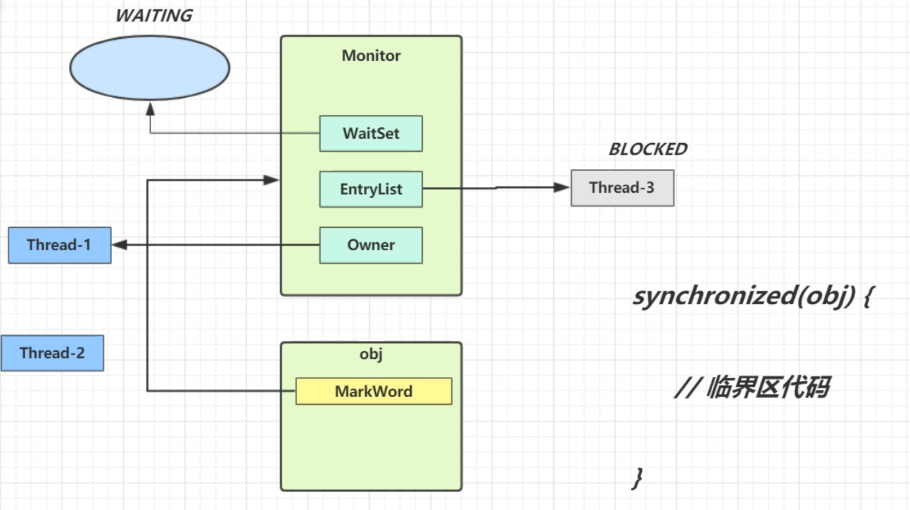
**注意:**当线程进入到 synchronized 方法或者 synchronized 代码块时,线程切换到的是 BLOCKED 状态,而使用 java.util.concurrent.locks 下 lock 进行加锁的时候线程切换的是 WAITING 或者 TIMED_WAITING 状态,因为 lock 会调用 LockSupport 的方法。
synchronized
synchronized 加在方法上
加在成员方法上等价于锁住this
加在 static 方法上等价于锁住类对象
如下面代码所示:
java
class Test {
synchronized void method() {
}
// 等价于
void method() {
synchronized (this) {
}
}
synchronized static void method2() {
}
// 等价于
static void method2() {
synchronized (Test.class) {
}
}synchronized 底层原理


java
public class Synchronized {
public static void main(String[] args) {
synchronized (Synchronized.class) {
System.out.println("hello world");
}
}
}使用 javap -v Synchronized.class 将上述代码编译成 Java 字节码文件如下:
java
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=1
0: ldc #2 //获取lock的引用
2: dup // 复制一份lock
3: astore_1 // 存入 slot 1
4: monitorenter // 获取对象的monitor,将lock对象的markword的前30 bit变为Monitor指针,指向对应的Monitor
5: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
8: ldc #4 // String hello world
10: invokevirtual #5 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
13: aload_1 // 加载lock的引用
14: monitorexit // 将lock对象MarkWord重置,唤醒EntryList
15: goto 23
// 若抛出了异常,则会执行到这里
18: astore_2 //将异常的变量e 存入 slot2
19: aload_1 // 加载lock的引用
20: monitorexit // 将lock对象MarkWord重置,唤醒EntryList
21: aload_2 //加载异常变量e
22: athrow // throw e
23: return
Exception table:
from to target type
5 15 18 any
18 21 18 any大致的流程如下:
在进入到 synchronized 同步块中,需要通过 monitorenter 指令获取到对象的 monitor(也通常称之为对象锁)后才能往下进行执行,在处理完对应的方法内部逻辑之后通过 monitorexit 指令来释放所持有的 monitor,以供其他并发实体进行获取(synchronized 是非公平锁,即 EntryList 中的线程会一起竞争这把锁)。代码后续执行到第 15 行 goto 语句进而继续到第 23 行 return 指令,方法成功执行退出。另外当方法异常的情况下,如果 monitor 不进行释放,对其他阻塞对待的并发实体来说就一直没有机会获取到了,系统会形成死锁状态很显然这样是不合理。
因此针对异常的情况,会执行到第 20 行指令通过 monitorexit 释放 monitor 锁,进一步通过第 22 行字节码 athrow 抛出对应的异常。从字节码指令分析也可以看出在使用 synchronized 是具备隐式加锁和释放锁的操作便利性的,并且针对异常情况也做了释放锁的处理。
每个对象都存在一个与之关联的 monitor,线程对 monitor 持有的方式以及持有时机决定了 synchronized 的锁状态以及 synchronized 的状态升级方式。
轻量级锁
轻量级锁的优化在于:
在个多线程不在同一时间使用锁,即没有竞争的情况下,使用轻量级锁相比重量级锁来说就是优化
线程在执行同步块之前,JVM 会先在当前线程的栈桢中创建用于存储锁记录的空间,然后线程尝试用 cas 替换 Object 的 Mark Word 为指向锁记录的指针(锁记录的地址),将 Mark Word 的值存入锁记录
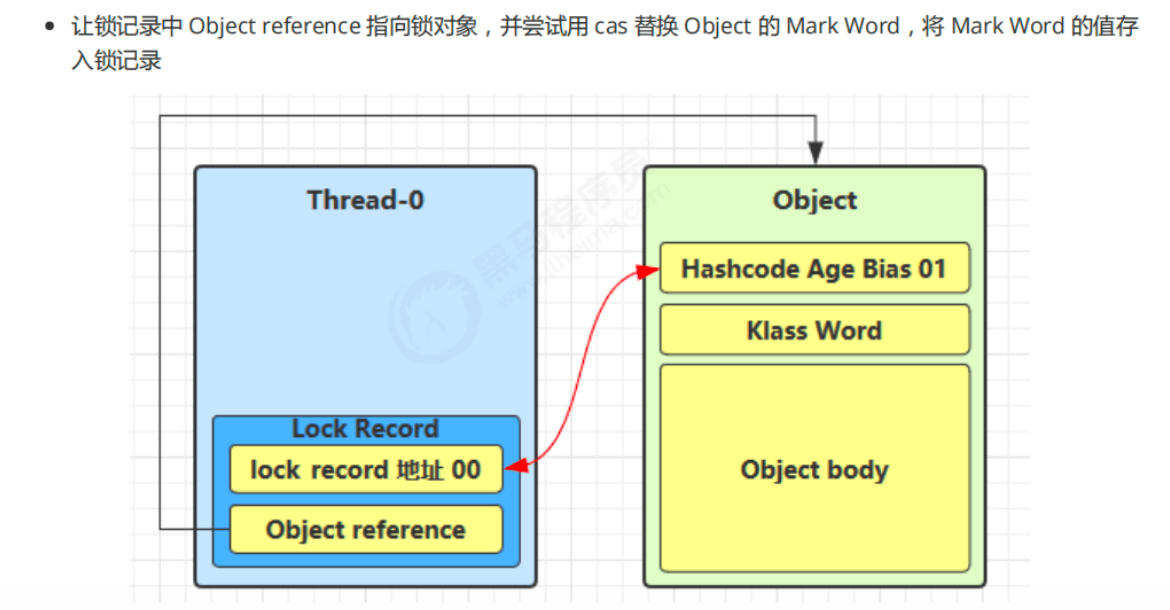
如果 CAS 失败,有两种情况
如果是其它线程已经持有了该 Object 的轻量级锁,这时表明有竞争,进入锁膨胀过程(升级为重量级锁)
如果是自己执行了 synchronized 锁重入,那么再添加一条 Lock Record 作为重入的计数
后面会用偏向锁来优化锁重入的这种情况
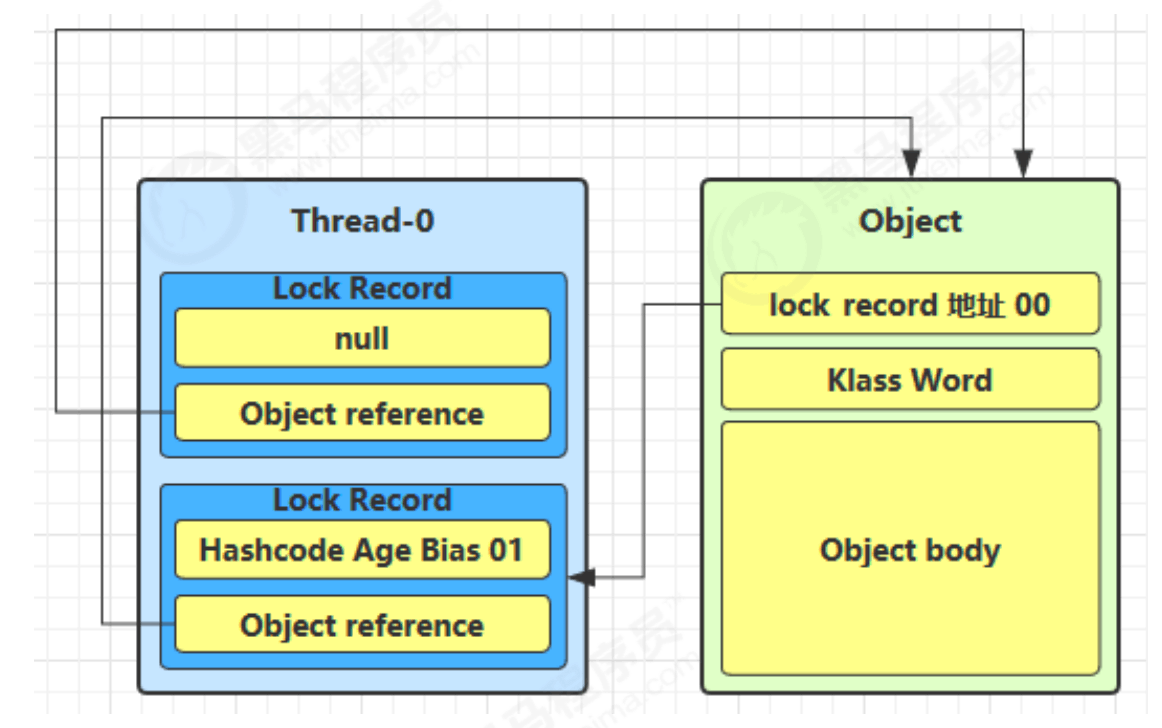
当退出 synchronized 代码块(解锁时)如果有取值
为 null的锁记录,表示有重入,这时重置锁记录,表示重入计数减一当退出 synchronized 代码块(解锁时)锁记录的值
不为 null,这时使用 cas 将 Mark Word 的值恢复给对象头成功,则解锁成功
失败,说明轻量级锁已经升级为重量级锁,进入重量级锁解锁流程
重量级锁
重量级锁的流程
线程 1 获取了 object 的轻量级锁,线程 2 还想获取锁,这时候该对象已经被线程 1 加了轻量级锁了,这时候就会进行锁膨胀,将轻量级锁升级为重量级锁,
这时 线程 2 加轻量级锁失败,进入锁膨胀流程
即为 object 对象申请 Monitor 锁,让 object 的 mark word 指向重量级锁地址
然后自己进入 Monitor 的 EntryList
线程 1 如果执行完了同步代码块,会使用 CAS 尝试释放轻量级锁,但此时已经升级为了重量级锁,CAS 失败,需要走重量级锁的释放流程,即按照 Monitor 地址找到 Monitor 对象,设置 Owner 为 null,唤醒 EntryList 中 BLOCKED 状态的线程
重量级锁的自适应自旋优化
即当锁为重量级锁时,若获取锁失败,会多次尝试获取锁(次数不确定)。
- 如果当前线程自旋成功(即这时候持锁线程已经退出了同步块,释放了锁),这时当前线程就可以避免阻塞。
- 若自旋失败,则进入阻塞队列
注意:
自旋会占用 CPU 时间,单核 CPU 自旋就是浪费,多核 CPU 自旋才能发挥优势。
在 Java 6 之后自旋是自适应的,比如对象刚刚的一次自旋操作成功过,那么认为这次自旋成功的可能性会高,就多自旋几次;反之,就少自旋甚至不自旋,总之,比较智能。
Java 7 之后不能控制是否开启自旋功能
偏向锁
HotSpot 的作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。使用轻量级锁时,同一个线程获取锁时(多次重入),每次重入仍然需要执行 CAS 操作。
为了减少同一线程多次重入时的 CAS 的次数,Java 6 中引入了偏向锁来做进一步优化:当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储持有偏向锁的线程 ID,以后该线程在进入和退出同步块时不需要进行 CAS 操作来加锁和解锁,只需简单地测试一下对象头的 Mark Word 里是否存储着指向当前线程的偏向锁。如果测试成功,表示线程已经获得了锁。如果测试失败,则需要再测试一下 Mark Word 中偏向锁的标识是否设置成 1(表示当前是偏向锁):如果没有设置,则使用 CAS 竞争锁(使用轻量级锁);如果设置了,则尝试使用 CAS 将对象头的偏向锁指向当前线程(设置 mark word ,使用偏向锁)
下图是偏向锁的对象头的 mark word 结构(32 位 JVM)

一个对象创建时:
如果开启了偏向锁(默认开启),那么对象创建后,markword 值为 0x05 即最后 3 位为 101,这时它的 thread、epoch、age 都为 0
偏向锁是默认是延迟的,不会在程序启动时立即生效,如果想避免延迟,可以加 VM 参数 -XX:BiasedLockingStartupDelay=0 来禁用延迟
如果你确定应用程序里所有的锁通常情况下处于竞争状态,可以通过 JVM 参数关闭偏向锁:-XX:UseBiasedLocking=false
**注意:**调用了对象的 hashCode,但偏向锁的对象 MarkWord 中存储的是线程 id,如果调用 hashCode 会导致偏向锁被撤销
轻量级锁会在锁记录中记录 hashCode
重量级锁会在 Monitor 中记录 hashCode
偏向锁的批量重偏向
当某个类的对象撤销偏向锁的次数超过 20 次(默认 20),JVM 会觉得是不是偏向错了,因此下次获取锁的时候不会撤销偏向锁,而是直接通过 CAS 操作将其mark word的线程 ID 改成当前线程 ID,这也算是一定程度的优化,毕竟没升级锁
偏向锁的批量撤销
当某个类的对象撤销偏向锁的次数超过 40 次(默认 40),jvm 会觉得自己确实偏向错了,根本就不该偏向。因此整个类的所有对象都会变为不可偏向,新建的对象也是,之后对于该 class 的锁,直接走轻量级锁的逻辑
锁膨胀和锁消除
TODO:
整体的流程
T2 线程先判断 object 的锁的状态
若为无锁状态,则直接获取到偏向锁
若为偏向锁,则看一下对象头的 Mark Word 里是否存储的线程 ID 是否是自己的线程 ID,
- 若是,则表示锁重入,获取到锁
- 若不是则尝试使用 CAS 竞争锁,获取失败后,此时会将偏向锁升级为轻量级锁
这里也不一定会升级,请看上面的偏向锁的批量重偏向和批量撤销
若为轻量级锁,则尝试使用 CAS 获取锁,看一下是否获取成功,如果 CAS 失败,有两种情况
如果是自己执行了 synchronized 锁重入,那么再添加一条 Lock Record 作为重入的计数
如果是其它线程已经持有了该 Object 的轻量级锁,这时表明有竞争,进入锁膨胀过程(升级为重量级锁)
即为 object 对象申请 Monitor 锁,让 object 的 mark word 指向重量级锁地址
然后 T2 线程进入 Monitor 的 EntryList,等待被唤醒
若为重量级锁,尝试获取 monitor,若失败,由于重量级锁有自适应自旋,因此会多次尝试获取锁,若都失败则将该线程放入 EntryList,线程进入 BLOCK 状态
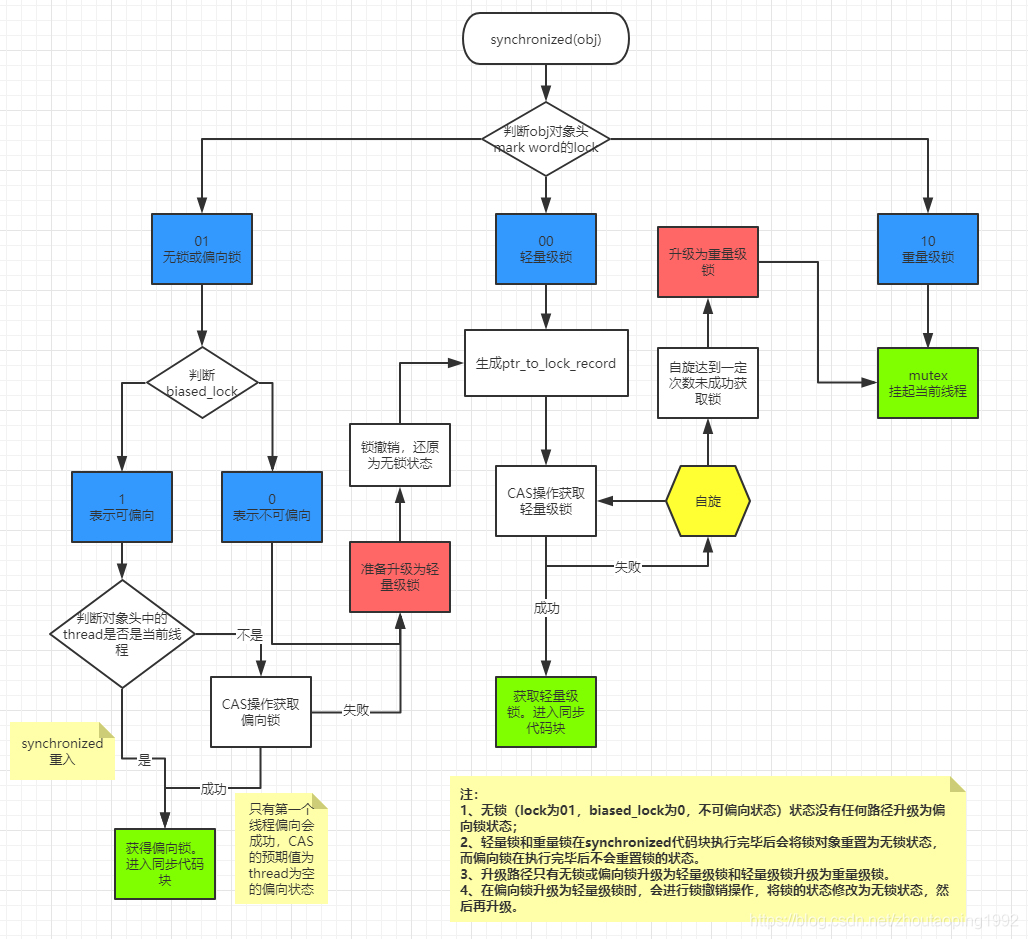
⚠️:轻量级锁没有自旋,重量级锁才有
为什么 JDK15 要废弃偏向锁
- 偏向锁的引入导致代码很复杂,给 HotSpot 虚拟机中锁相关部分与其他组件之间的交互也带来了复杂性。这种复杂性使得理解代码的各个部分变得困难,并且阻碍了在同步子系统内进行重大设计更改。因此,废弃偏向锁有助于减少复杂性,使代码更容易维护和改进。
- 在过去,Java 应用通常使用的都是 HashTable、Vector 等比较老的集合库,这类集合库大量使用了 synchronized 来保证线程安全。然而过去能够从偏向锁中获得的性能提升在当今的应用中不再明显。在单线程场景中,许多现代应用程序可以使用不需要同步的集合类(HashMap,ArrayList);在多线程场景中,使用更高性能的并发数据结构(如 ConcurrentHashMap、CopyOnWriteArrayList 等),而不再频繁地执行无争用的同步(synchronized)操作。
reference: JEP 374: Deprecate and Disable Biased Locking
wait 和 notify
- obj.wait() :让进入 object monitor 的线程到 waitSet 中等待,会释放 cpu 和锁,并且线程到状态变为
WAITING - obj.wait(long):和 obj.wait()一样,不同的是:线程到状态变为
TIMED_WAITING - obj.notify() :唤醒一个 object monitor 上正在 waitSet 等待的线程
- obj.notifyAll() :唤醒所有 object monitor 上正在 waitSet 等待的线程
他们都是线程之间协作的手段,都属于 Object 对象的方法,必须获得此对象的锁,才能调用这几个方法
使用 wait 和 notify 的正确姿势

AQS
AQS 全称 AbstractQueuedSynchronizer (抽象队列同步器),AQS 是一个用来构建锁和同步器的框架,使用 AQS 能简单且高效地构造出应用广泛的同步器。AQS 是基于模版设计模式的,内部维护了一套阻塞队列的逻辑,而开发者只需要关注加锁和释放锁的逻辑即可,不需要管理阻塞队列的逻辑。
特点:
用 state 属性来表示资源的状态(分独占模式和共享模式),子类需要定义如何维护这个状态,控制如何获取锁和释放锁
- getState - 获取 state 状态
- setState - 设置 state 状态
- compareAndSetState - cas 机制设置 state 状态
独占模式是只有一个线程能够访问资源,而共享模式可以允许多个线程访问资源(例如 readLock , Semaphore)
提供了基于 FIFO 的等待队列,类似于 Monitor 的 EntryList
条件变量来实现等待、唤醒机制,支持多个条件变量,类似于 Monitor 的 WaitSet
AQS 的设计是基于模板方法模式的 ,需要子类实现以下方法:
isHeldExclusively():该线程是否正在独占资源。只有用到 condition 才需要去实现它。tryAcquire(int):独占方式。尝试获取资源,成功则返回 true,失败则返回 false。tryRelease(int):独占方式。尝试释放资源,成功则返回 true,失败则返回 false。tryAcquireShared(int):共享方式。尝试获取资源。负数表示失败;0 表示成功,但没有剩余可用资源;正数表示成功,表示剩余资源的数量tryReleaseShared(int):共享方式。尝试释放资源,如果释放后允许唤醒后续等待结点返回 true,否则返回 false。
这 5 个方法都是 protected 的,直接抛出异常
java
protected boolean tryAcquire(int arg) {
throw new UnsupportedOperationException();
}这里不使用抽象方法的目的是:避免强迫子类中把所有的抽象方法都实现一遍,减少无用功,这样子类只需要实现自己关心的抽象方法即可,例如 Semaphore 中的同步器只需要实现 tryAcquireShared 和 tryReleaseShared ,而不需要实现其他方法
模板方法模式(Template Method Pattern)是一种行为设计模式,它定义了一个操作中的算法骨架,而将一些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下,重新定义算法的某些步骤。
ReentrantLock
相对于 synchronized ,ReentrantLock 具备以下特点:
和 synchronized 一样,都支持可重入
可中断,可以调用这个方法
lock.lockInterruptibly()获取可以被打断的锁,之后其他线程可以调用t1.interrupt()打断这个线程可以设置超时时间
- 可以使用
lock.tryLock()方法获取锁,可以设置超时时间,在超时时间内获取到锁了返回 true,否则返回 false(可以做一些其他的逻辑)
- 可以使用
有公平锁和非公平锁两种锁(默认非公平锁),synchronized 只有非公平锁
支持多个条件变量
synchronized 只有一个条件变量,调用了 wait 方法的线程都会进入
waitSet中ReentrantLock 可以设置多个条件变量,可以调用 xxxcondition.await() 方法 让线程进入不同的等待队列,再调用 xxxcondition.signal() / signalAll() 唤醒某个等待队列中的 一个/全部 线程
和 synchronized 一样,调用 awiat 方法时,必须获取到了锁,否则会抛出异常
原理
可重入的原理
获取锁:先判断一下 state 的值,为 0 的话就是当前线程没获取到锁,那么就尝试获取锁 ; 不为 0,则判定是不是当前线程获取的锁,若是则重入,state+1
释放锁:c = state-1 , 判断 c 是否为 0, 为 0 则释放锁,否则表示重入还没有结束
java
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}java
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}公平锁和非公平锁的原理
公平锁:锁的获取顺序就应该符合请求上的绝对时间顺序,满足 FIFO
非公平锁: 则不满足 FIFO 的特性 ,刚释放锁的线程可能再次获取到锁
上面的是非公平锁 获取锁的 源码, 下面这个是公平锁的版本
主要区别在于获取锁时会不会先判断阻塞队列中是否有元素,若有元素,则表示有别的线程更早请求锁,那么当前线程就不会尝试获取锁 ,会进入阻塞队列; 若没有元素,则当前线程当时获取锁
java
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}公平锁和非公平锁的区别
公平锁每次获取到锁为同步队列中的第一个节点,保证请求资源时间上的绝对顺序,而非公平锁有可能刚释放锁的线程下次继续获取该锁,则有可能导致其他线程永远无法获取到锁,造成“饥饿”现象。
公平锁为了保证时间上的绝对顺序,需要频繁的上下文切换,而非公平锁会降低一定的上下文切换,降低性能开销。而非公平锁允许一个线程在释放锁后立即重新获得锁,而不必等待其他线程。这减少了线程在队列中等待的时间,从而减少了上下文切换。保证了系统更大的吞吐量。
ReentrantReadWriteLock
读写锁:可以多个线程同时读,提高并发度,这个锁适用于读多写少的情况(例如缓存)
对于读写锁,state 的高 16 位存储读锁被获取的次数 ,state 的低 16 位存储写锁被获取的次数(只能有一个线程获得写锁)
notice:
- 读锁不支持条件变量,写锁支持
- 重入时升级不支持:即持有读锁的情况下去获取写锁,会导致获取写锁永久等(这种情况要先解除读锁,再申请写锁)
- 重入时降级支持:即持有写锁的情况下去获取读锁
获取写锁
java
protected final boolean tryAcquire(int acquires) {
Thread current = Thread.currentThread();
int c = getState();
int w = exclusiveCount(c);
// 有线程获取了锁
if (c != 0) {
// (Note: if c != 0 and w == 0 then shared count != 0)
// 如果获取的是读锁 || 获取的是写锁但是不是当前线程获取的
if (w == 0 || current != getExclusiveOwnerThread())
return false;
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// 当前线程获取的写锁,重入
setState(c + acquires);
return true;
}
// writerShouldBlock是对于公平锁和非公平锁的实现
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires))
return false;
setExclusiveOwnerThread(current);
return true;
}释放写锁
释放写锁的过程和 ReentrantLock 很类似,就是先 state-1, 判断值是否为 0,为 0 则释放锁,否则就是重入次数-1,不释放锁
java
protected final boolean tryRelease(int releases) {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
int nextc = getState() - releases;
boolean free = exclusiveCount(nextc) == 0;
if (free)
setExclusiveOwnerThread(null);
setState(nextc);
return free;
}获取读锁
java
protected final int tryAcquireShared(int unused) {
Thread current = Thread.currentThread();
int c = getState();
//1. 如果写锁已经被获取并且获取写锁的线程不是当前线程的话,当前
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return -1;
int r = sharedCount(c);
if (!readerShouldBlock() &&
r < MAX_COUNT &&
//2. 获取读锁,state的高16位+1(无论是否是重入,高16位都会+1,释放锁的时候也类似)
compareAndSetState(c, c + SHARED_UNIT)) {
// 采用 HoldCounter 来存储每个线程对应的重入次数,HoldCounter存储在readHolds中
if (r == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
}
return 1;
}
// 如果CAS失败或者已经获取读锁的线程再次获取读锁时在 fullTryAcquireShared 中处理
return fullTryAcquireShared(current);
}读锁的释放
java
protected final boolean tryReleaseShared(int unused) {
Thread current = Thread.currentThread();
// 处理重入的次数
if (firstReader == current) {
// assert firstReaderHoldCount > 0;
if (firstReaderHoldCount == 1)
firstReader = null;
else
firstReaderHoldCount--;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
rh = readHolds.get();
int count = rh.count;
if (count <= 1) {
readHolds.remove();
if (count <= 0)
throw unmatchedUnlockException();
}
--rh.count;
}
// CAS释放锁
for (;;) {
int c = getState();
int nextc = c - SHARED_UNIT;
if (compareAndSetState(c, nextc))
// 如果 nextc = 0 说明此时没有线程持有读锁了,可以将读锁释放
return nextc == 0;
}
}StampedLock
StampedLock 是读写锁的一种改进版本,ReentrantReadWriteLock 中使用的是悲观读和悲观写 ,即读和写之前要先获取锁
而 StampedLock 引入了一种乐观读的优化方案,即直接读取数据(不加锁),之后再判断一下数据是否被修改了,如何被修改了就升级为悲观读,重新读取数据
StampedLock 是不可重入的锁,且不支持 Condition
java
public static void read() throws InterruptedException {
long stamp = lock.tryOptimisticRead();
log.info("尝试乐观读{}", stamp);
log.info("读数据");
Thread.sleep(1000);
if (lock.validate(stamp)) {
log.info("读取成功");
return;
} else {
// 升级为悲观读
long newStamp = lock.readLock();
try {
log.info("new stamp {}", newStamp);
log.info("读new 数据");
} finally {
lock.unlockRead(newStamp);
}
}
}重排序
重排序概述
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新调整语句的执行顺序。
- 指令级并行的重排序。现代 cpu 采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,cpu 可以改变语句对应机器指令的执行顺序;
- 内存系统的重排序。由于 cpu 使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行的。
1 属于编译器重排序,而 2 和 3 统称为 cpu 重排序。这些重排序会导致线程安全的问题,一个很经典的例子就是 DCL 问题。针对编译器重排序,JMM 的编译器重排序规则会禁止一些特定类型的编译器重排序;针对处理器重排序,编译器在生成指令序列的时候会通过插入内存屏障指令来禁止某些特殊的处理器重排序(volatile 的底层原理就是插入内存屏障来防止重排序)
as-if-serial 原则
不管怎么重排序(编译器和处理器为了提供并行度),(单线程)程序的执行结果不能被改变。
DCL(double-checked-locking)问题
单例模式算是比较常见的设计模式之一了,而双重检查单例 是一种比较常见的单例模式的实现之一
java
class Singleton {
private volatile Singleton instance = null;
public Singleton getInstance() {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
return instance;
}
}看上面这段代码,这段代码中使用 synchronized 来保证线程安全,但这样也有一个缺点,就是当 instance 已经不为 null 之后,每次调用 getInstance 方法都会需要获取锁,大家都知道,这是一种比较耗时的操作,因此我们可以在 synchronized 前面加一层判断,这就是所谓 double-checked
java
class Singleton {
private volatile Singleton instance = null;
public Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}这是 getInstance 方法的字节码
java
0 aload_0
1 getfield #3 <leftover/DCL$Singleton.instance : Lleftover/DCL$Singleton;>
4 ifnonnull 44 (+40)
7 ldc #4 <leftover/DCL$Singleton>
9 dup
10 astore_1
11 monitorenter
12 aload_0
13 getfield #3 <leftover/DCL$Singleton.instance : Lleftover/DCL$Singleton;>
16 ifnonnull 34 (+18)
19 aload_0
20 new #4 <leftover/DCL$Singleton>
23 dup
24 aload_0
25 getfield #1 <leftover/DCL$Singleton.this$0 : Lleftover/DCL;>
28 invokespecial #5 <leftover/DCL$Singleton.<init> : (Lleftover/DCL;)V>
31 putfield #3 <leftover/DCL$Singleton.instance : Lleftover/DCL$Singleton;>
34 aload_1
35 monitorexit
36 goto 44 (+8)
39 astore_2
40 aload_1
41 monitorexit
42 aload_2
43 athrow
44 aload_0
45 getfield #3 <leftover/DCL$Singleton.instance : Lleftover/DCL$Singleton;>
48 areturn对应instance = new Singleton();的字节码大致如下:
java
20 new #4 <leftover/DCL$Singleton> // new 一个对象
23 dup // 将引用复制一份
28 invokespecial #5 <leftover/DCL$Singleton.<init> : (Lleftover/DCL;)V> // 执行构造函数
31 putfield #3 <leftover/DCL$Singleton.instance : Lleftover/DCL$Singleton;> //将对象引用复制给instance变量可以看出这个语句对应好多条指令,因此这里有指令重排序的风险,第 28 行和第 31 行是可能指令重排序的(单线程下这两条指令调换顺序不会有影响),因此可能先执行 31 行再执行 28 行
我们假设发生了重排序,执行顺序变为了这样,当 t1 线程执行了 31 行时,此时将对象复制给了 instance,因此这时候 instance 不为 null,但是此时还没执行构造函数
假设此时切换到 t2 线程,首先判断 instance 是否为 null,此时已经不为 null 了,这时候会直接 return,所以这时候 return 的就是一个还没初始化完毕的对象
java
20 new #4 <leftover/DCL$Singleton>
23 dup
31 putfield #3 <leftover/DCL$Singleton.instance : Lleftover/DCL$Singleton;>
28 invokespecial #5 <leftover/DCL$Singleton.<init> : (Lleftover/DCL;)V>这就是指令重排序导致的 DCL 问题
**解决办法:**给 instance 变量加上 volatile关键字即可防止重排序
volatile
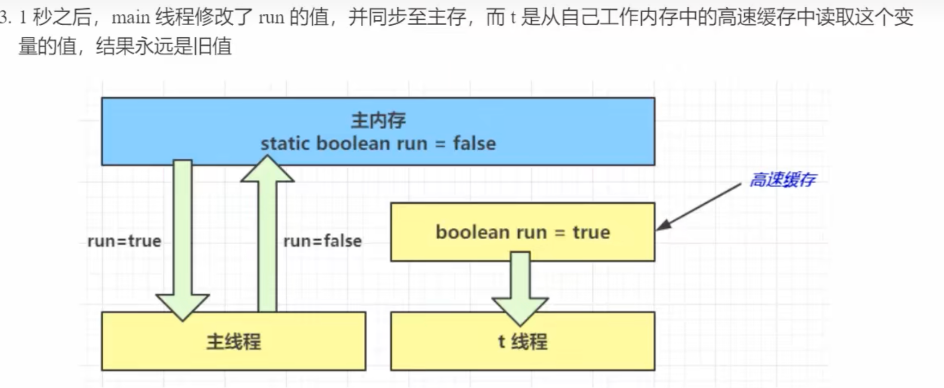
volatile 翻译为易变的,可以修饰 静态成员变量/成员变量 ,顾名思义,该关键字的作用为标记这个变量为易变的,这样就可以避免线程从自己的工作缓存中查找变量的值,必须每次去主存中获取它的值。这样每个线程都从主存中取这个变量的值,因此当一个线程修改了这个变量的值,其他线程就能立刻“看得见” ,所谓可见性。
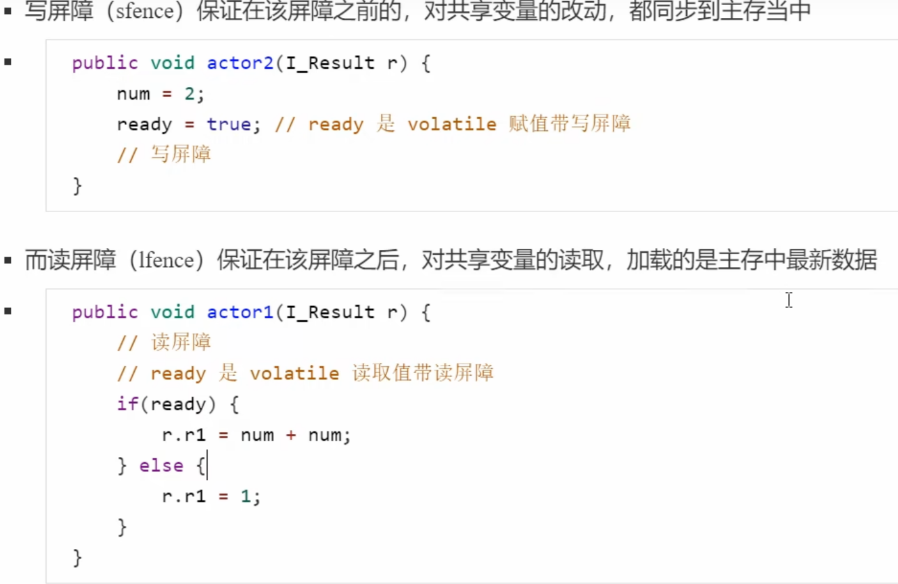
synchronized 语句块即可以保证代码块的原子性,也同时保证代码块内变量的可见性,但缺点是 synchronized 是属于重量级操作,性能相对更低
volatile 的底层实现原理是内存屏障(Memory Barrier)
- 对 volatile 变量的
写指令后会加入写屏障 - 对 volatile 变量的
读指令前会加入读屏障
- 对 volatile 变量的
可见性问题以及如何保证可见性?
每个线程都有属于自己的工作内存,并且会把位于主存中的共享变量拷贝到自己的工作内存,之后的读写操作均使用位于工作内存的变量副本,并在某个时刻将工作内存的变量副本写回到主存中去。
因此这就是缓存优化导致的可见性问题,一个线程对共享变量的修改,另外一个线程不能够立刻看到
有序性问题以及如何保证有序性?
为了提高性能,编译器和处理器常常会对指令进行重排序。在单线程环境下重排序不会有什么问题,但在多线程环境下,这种操作会影响多线程的执行顺序,从而导致错误

happens-before 规则
happens-before 规定了对共享变量的写操作对其它线程的读操作可见,抛开以下 happens-before 规则,JMM 并不能保证一个线程对共享变量的写,对于其它线程对该共享变量的读可见
程序次序规则(Program Order Rule):在一个线程内,按照控制流顺序,书写在前面的操作先行发生于书写在后面的操作。
管程锁定规则(Monitor Lock Rule): 线程解锁 m 之前对变量的写,对于接下来对 m 加锁的其它线程对该变量的读可见 (即 synchronized 可以保证可见性)
java
static int x;
static Object m = new Object();
new Thread(()->{
synchronized(m) {
x = 10;
}
},"t1").start();
new Thread(()->{
synchronized(m) {
System.out.println(x);
}
},"t2").start();- volatile 变量规则(Volatile Variable Rule):线程对 volatile 变量的写,对接下来其它线程对该变量的读可见 (即 volatile 可以保证可见性)
java
volatile static int x;
new Thread(()->{
x = 10;
},"t1").start();
new Thread(()->{
System.out.println(x);
},"t2").start();线程启动规则(Thread Start Rule):线程 start 前对变量的写,对该线程开始后对该变量的读可见
这个例子中 updater 线程修改了 stop,但是对 getter 线程不可见,因此 getter 线程不会输出
getter stopped.",将getter.start();语句放到stop = true;的后面,即可得到正确结果javapackage leftover; import lombok.extern.slf4j.Slf4j; @Slf4j public class happens_before { private static boolean stop = false; public static void main(String[] args) { Thread getter = new Thread(new Runnable() { @Override public void run() { while (true) { if (stop) { System.out.println("getter stopped."); break; } } } }, "getter"); Thread updater = new Thread(new Runnable() { @Override public void run() { getter.start(); try { Thread.sleep(1000); } catch (InterruptedException e) { throw new RuntimeException(e); } stop = true; System.out.println("updater set stop true."); while (true) { } } }); updater.start(); } }线程终止规则:线程结束前对变量的写,对其它线程得知它结束后的读可见(比如其它线程调用 t1.isAlive() 或 t1.join()等待
它结束)
java
public class happens_before {
static int x;
static Object m = new Object();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
x = 10;
}, "t1");
t1.start();
t1.join();
// or
// while (t1.isAlive()) {
// Thread.yield();
// }
// 调用了join 或者 isAlive方法判断他是否结束,则读可见 printf 10 ,否则 printf 0
System.out.println(x);
}
}- 线程中断规则:对线程 interrupted()方法的调用 先行于 被中断线程的代码检测到中断时间的发生。
java
public class happens_before {
static int x;
public static void main(String[] args) throws InterruptedException {
Thread t2 = new Thread(() -> {
while (true) {
if (Thread.currentThread().isInterrupted()) {
System.out.println(x); // 10
break;
}
}
}, "t2");
t2.start();
new Thread(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
x = 10;
t2.interrupt();
}, "t1").start();
}
}对象终结规则(Finalizer Rule) :一个对象的初始化完成(构造函数结束)先行发生于它的 finalize()方法的开始
java@Slf4j public class happens_before { private static boolean stop = false; public static void main(String[] args) { Test test = new Test(); //test设置为null以后就可以回收了 test = null; while (true) { //促使垃圾回收 byte[] bytes = new byte[1024 * 1024]; } } static class Test { public Test() { stop = true; System.out.println("set stop true in constructor"); } @Override protected void finalize() throws Throwable { if (stop) { System.out.println("stop true in finalize, threadName " + Thread.currentThread().getName()); } else { System.out.println("stop false in finalize, threadName " + Thread.currentThread().getName()); } } } }传递性(Transitivity):如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,那就可以得出操作 A 先行发生于操作 C 的结论。
巨人的肩膀:Happens-Before 原则深入解读
final 的底层原理
TODO:
原子类
CAS
什么是 CAS?
CAS 全称 Compare And Swap (比较并交换), CAS 使用的是一种乐观锁的思想,每次线程操作时都认为自己可以成功执行,但当多个线程同时使用 CAS 操作一个变量时,只有一个会成功执行并成功更新,其他线程均会失败,但是失败的线程不会被挂起,会被告知没有 swap 成功,线程可以继续重试,也可以放弃操作。
CAS 方法有 3 个参数(expect,offset,update)-> 旧的值,旧值对应的内存地址,新值 ;当 swap 之前会取出对应内存中的值进行判断,是否与旧的值一致,若一致,则替换成功;若不是,则不替换
底层原理
其实 CAS 的底层是 lock cmpxchg 指令(X86 架构),CMPXCHG 是“Compare and Exchange”的缩写,是原子指令,在单核 CPU 和多核 CPU 下都能够保证【比较-交换】的原子性
在多核状态下,某个核执行到带 lock 的指令时,CPU 会让总线锁住,当这个核把此指令执行完毕,再开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子的。
CAS 的特点
因为 CAS 不会上锁,因此不会发生死锁
结合 CAS 和 volatile 可以实现无锁并发,适用于线程数少,多核 CPU 的场景
CAS 操作通常会在失败时自旋重试,而不是阻塞线程。自旋操作在大多数情况下能更快地完成,因为避免了线程的上下文切换。
线程要想一直保持运行,需要额外 CPU 的支持,若 CPU 少,那么线程还是会因为没有分到时间片而进入 Runnable(Ready)状态,从而导致上下文切换,会产生比较大的开销
如果线程数比较多,会经常出现 CAS 失败的情况,这样自旋的次数就会增多
CAS 使用的是乐观锁的思想,大多数情况下可以直接成功
综上: CAS+ volatile 实现无锁并发,适用于并发度不是特别高,多核 CPU 的场景
CAS 的三大问题
TODO:
ABA 问题
长时间自旋
多个共享变量的原子操作
线程池
线程池状态
ThreadPoolExecutor 使用整型的原子变量 ctl 来存储线程池的状态和线程数量。 int 的高 3 位表示线程状态,低 29 位表示线程数量
目的是将线程状态和线程个数合二为一,这样就可以使用一次 CAS 操作进行赋值
java
// c为旧值,ctlOf返回的结果为新值
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))))| 状态名 | 高 3 位 | 接收新任务 | 处理阻塞队列的任务 | 说明 |
|---|---|---|---|---|
| RUNNING | 111 | Y | Y | |
| SHUTDOWN | 000 | N | Y | 调用线程池的 shutdown 方法会进入 shutdown 状态,不会接收新任务,但是会处理阻塞队列剩余任务 |
| STOP | 001 | N | N | 调用线程池的 shutDownNow 方法会进入 stop 状态,会中断正在执行的任务,并且抛弃阻塞队列中的任务 |
| TIDYING | 010 | - | - | 任务全部执行完毕,活动线程为 0,即将进入终结 |
| TERMINATED | 011 | - | - | 终结状态 |
线程池的参数
java
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)- corePoolSize: 核心线程数量(最多保留的线程数)
- maximumPoolSize: 最大的线程数量(核心线程数量+救急线程数量 <=最大线程数量)
救急线程:当阻塞队列满的时候,此时还有任务进来,但是阻塞队列装不下了,若可以创建救急线程(核心线程数量+救急线程数量 <=最大线程数量),则会创建救急线程来处理新的任务
- keepAliveTime: 救急线程的生存时间
- TimeUnit: 时间单位
当救急线程没有任务处理时,过了给定的时间则会自动终结
- workQueue: 阻塞队列,用来存放任务
- threadFactory: 线程工厂,可以自定义创建的线程的逻辑(例如添加日志记录,给线程取名字)
- handler:拒绝策略
拒绝策略
若线程数量到达 maximumPoolSize 仍有任务到达,此时会执行拒绝策略。jdk 默认提供了 4 种拒绝策略
AbortPolicy 让调用者抛出
RejectedExecutionException异常 (默认的策略)CallerRunsPolicy: 让调用者运行任务
DiscardPolicy: 放弃本次任务
DiscardOldestPolicy: 放弃阻塞队列中最早的任务,本任务取而代之

线程池工具类(Executors)
newFixedThreadPool
- 创建固定大小的线程池,即核心线程数 = 最大线程数
- 阻塞队列是无界的,可以放任意数量的任务
适用于任务量已知,相对耗时的任务
newCachedThreadPool
java
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}- 核心线程数为 0,最大线程数为
Integer.MAX_VALUE - 救急线程的存活时间为 1min
- 队列采用了 SynchronousQueue 实现特点是,它没有容量,没有线程来取是放不进去的
整个线程池表现为线程数会根据任务量不断增长,没有上限,当任务执行完毕,空闲 1 分钟后释放线程。 适合任务数比较密集,但每个任务执行时间较短的情况
newSingleThreadExecutor
java
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}- 核心线程数 = 最大线程数 =1
- 阻塞队列无上限
- 这里使用了装饰器模式,return 的线程池对象不能修改线程数量
和自己使用单个线程的区别:自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任何补救措施,而线程池还会新建一个线程,保证池的正常工作
适用于希望多个任务排队执行。线程数固定为 1,任务数多于 1 时,会放入无界队列排队。任务执行完毕,这唯一的线程也不会被释放
newScheduledThreadPool
java
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}- jdk 中提供了 Timer 对象来进行定时任务调度,但是所有的任务都是由一个线程串行执行的,只有前面任务的执行完了才能执行后面的任务,若任务执行过程中出现了异常没有被捕获,则整个程序会终止,因此这个类不是很适合用来做定时任务
newScheduledThreadPool 是定时任务调度的线程池,用来执行定时任务。
- 可以指定核心线程数 , 最大线程数为
Integer.MAX_VALUE - 救急线程的存活时间为 0,即执行完任务立刻杀死救急线程
- 使用的是无上限的延时队列
- 任务执行过程中出现了没有捕获的异常也不会终止应用程序(和 Timer 的区别)
java
// 每周四执行一次定时任务
public void testScheduledThreadPool() {
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(2);
// 一周的ms数
long period = 1000 * 60 * 60 * 24 * 7;
LocalDateTime now = LocalDateTime.now();
LocalDateTime time = now.withHour(18).withMinute(0).withSecond(0).withNano(0).with(DayOfWeek.THURSDAY);
if (now.isAfter(time)) {
time = time.plusWeeks(1);
}
// 当前到最近的周四的ms数
long initialDelay = Duration.between(now, time).toMillis();
scheduledThreadPool.scheduleAtFixedRate(() -> log.info("11"), initialDelay, period, TimeUnit.MILLISECONDS);
}newSingleThreadScheduledExecutor
java
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}- 和 newScheduledThreadPool 类似,也是用来执行定时任务的,区别就是这个的核心线程只有 1 个, 最大线程数都是
Integer.MAX_VALUE - 使用了装饰器模式,return 的线程池对象不能调用 api 来设置线程池的线程数量
newWorkStealingPool
java
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}名为任务窃取线程池, 底层使用的是 ForkJoinPool ,默认会创建一个和自己 cpu 核数相同的 ForkJoinPool
详情请看 fork and join
如何处理线程池执行任务的过程中出现的异常
若线程池中的线程在执行任务的过程中出现了异常是不会终止应用程序的运行的,但是这样的话,你自己也不清楚任务执行过程中是否出现了异常
- 可以在任务执行过程中自己捕获异常,对异常进行处理(记录日志……)
- 使用 Future , futhure 调用 get 时, 若任务出现了异常,则 get 方法会抛出异常,之后可以对异常做处理
java
ExecutorService pool = Executors.newFixedThreadPool(1);
Future<Boolean> f = pool.submit(() -> {
log.debug("task1");
int i = 1 / 0;
return true;
});
log.debug("result:{}", f.get());
/*
17:33:42.025 [pool-1-thread-1] DEBUG leftover.线程池工具类 - task1
Exception in thread "main" java.util.concurrent.ExecutionException: java.lang.ArithmeticException: / by zero
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at leftover.线程池工具类.main(线程池工具类.java:44)
Caused by: java.lang.ArithmeticException: / by zero
at leftover.线程池工具类.lambda$main$0(线程池工具类.java:41)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
/*线程池的一些方法
- submit: 传入一个 Callable 对象,return 一个 Futhure 对象,可以使用这个 futhure 对象获得返回值的结果
- invokeAll: 传入一个 Callable 的集合(可以给定超时时间,超时没有执行完毕的任务会被取消,抛出
CancellationException),返回一个 Futhure 集合 \ - invokeAny: 和 invokeAll 类似, 但是它返回的是第一个执行完毕的结果
java
String result = executorService.invokeAny(tasks);
log.info("{}", result);shutdown: 线程池状态变为 SHUTDOWN 不会接收新任务,但会执行完已经提交的任务(该方法不会阻塞调用线程的执行)
若想在 shutdown 之后做一些事情,可以调用 awaitTermination 等待一段时间
javaexecutorService.shutdown(); executorService.awaitTermination(2,TimeUnit.SECONDS); // do other也可以使用一个类继承线程池
ThreadPoolExecutor,重写 onShutdown 方法shutdownNow: 线程池状态变为 STOP, 不会接收新的任务 ,用 interrupt 的方式中断正在执行的任务,将阻塞队列中的任务返回
线程池的线程数量的设置
过小会导致程序不能充分地利用系统资源、容易导致饥饿
过大会导致更多的线程上下文切换,占用更多内存
最好为一类任务创建一个线程池,这样可以提高线程池的利用率

tomcat 的线程池
Tomcat 线程池扩展了 ThreadPoolExecutor,行为稍有不同
如果总线程数达到 maximumPoolSize
- 这时不会立刻抛 RejectedExecutionException 异常
- 而是再次尝试将任务放入队列,如果还失败,才抛出 RejectedExecutionException 异常
创建核心线程和救急线程的行为也稍有不同

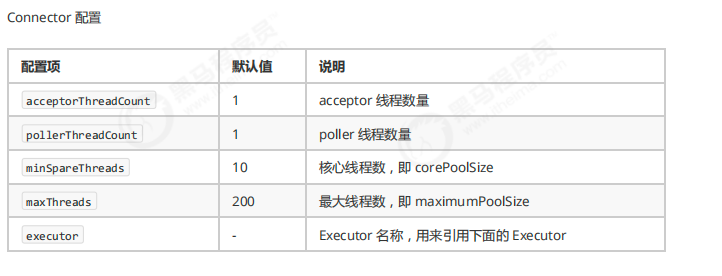
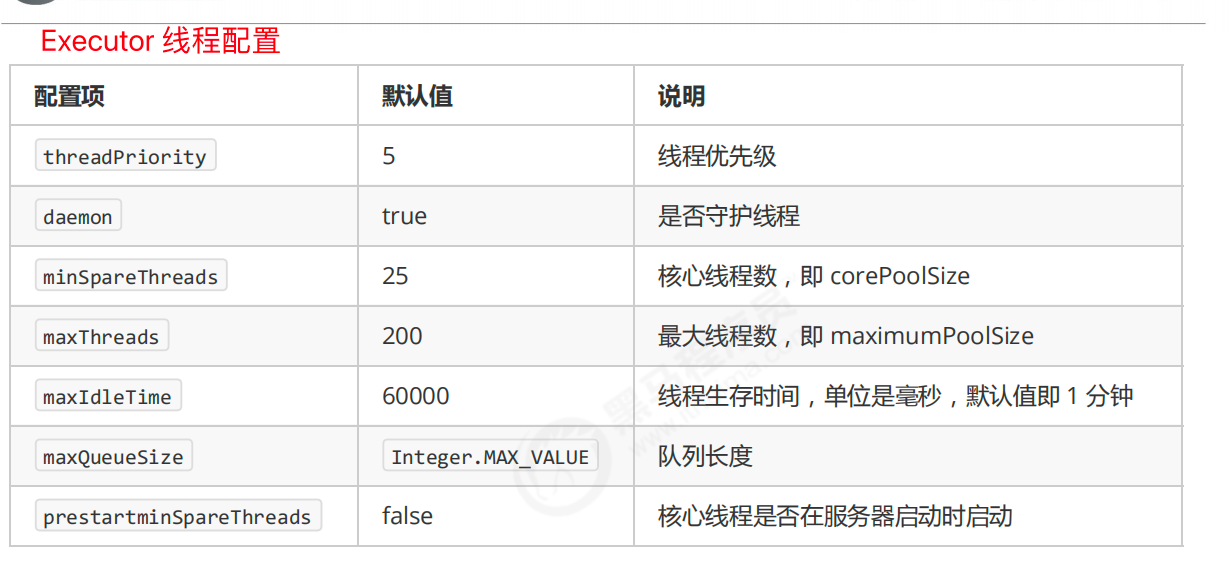
线程池的整体流程
先看当前线程数是否达到了给定的核心线程数,若没达到,则创建一个核心线程来执行任务 ,若达到了,则将任务添加进阻塞队列,核心线程从阻塞队列中取任务。
若阻塞队列已经满了,若当前线程的个数< 最大线程数,则创建非核心线程执行到来的任务,否则执行拒绝策略
线程池的原理
TODO:
fork-and-join
Fork/Join 是 JDK 1.7 加入的新的线程池实现,它体现的是一种分治思想,适用于能够进行任务拆分的 cpu 密集型运算
提交给 Fork/Join 线程池的任务需要继承 RecursiveTask(有返回值)或 RecursiveAction(没有返回值)
fork 方法用于异步执行一个子任务,而 join 方法通过阻塞当前线程来等待子任务的执行结果。
ForkJoinPool 默认会创建与 cpu 核心数大小相同的线程池
ForkJoinPool 中有一个成员变量 WorkQueue[] workQueues ,每一个线程都有一个任务队列,当自己的任务队列中没有任务的时候,它可以从其他工作线程的任务队列中"窃取"任务。这样所有的工作线程都能保持忙碌的状态,能够充分发挥多核 cpu 的特点
java
@Slf4j
public class forkAndJoin {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建fork join的线程池
ForkJoinPool forkJoinPool = new ForkJoinPool(4);
ForkJoinTask<Integer> taskResult = forkJoinPool.submit(new MyAddTask(1, 100));
log.info("{}", taskResult.get()); // 5050
Integer result = forkJoinPool.invoke(new MyAddTask(1, 100));
log.info("{}", result); // 5050
}
@ToString
static class MyAddTask extends RecursiveTask<Integer> {
private int begin;
private int end;
public MyAddTask(int begin, int end) {
this.begin = begin;
this.end = end;
}
@Override
protected Integer compute() {
if (begin == end) {
return begin;
} else if (end - begin == 1) {
return end + begin;
} else {
int mid = (begin + end) / 2;
// 将start - end 的相加拆分成2个任务, start-mid ,mid+1 -end
MyAddTask addTask1 = new MyAddTask(begin, mid);
addTask1.fork();
MyAddTask addTask2 = new MyAddTask(mid + 1, end);
addTask2.fork();
// 得到两个任务相加的结果
return addTask1.join() + addTask2.join();
}
}
}
}stream 的并行流其实也是使用了 fork and join 的实现方式,会将任务进行拆分,最后合并,从下面的例子中就可以看出
java
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
listOfNumbers.parallelStream().forEach(number ->
System.out.println(number + " " + Thread.currentThread().getName())
);
/*
3 main
4 ForkJoinPool.commonPool-worker-1
2 ForkJoinPool.commonPool-worker-2
1 ForkJoinPool.commonPool-worker-1
*/对于下面这个例子,我们想要求数组的元素的和+5 ,使用串行流可以很容易得到结果,但是如果使用并行流,由于他会将任务进行拆分,每个线程在进行任务计算时都会加 5,因此会得到错误的结果(实际结果可能因公共 fork-join 池中使用的线程数而有所不同)
java
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
int sum = listOfNumbers.parallelStream().reduce(5, Integer::sum);为了修复这个问题,我们可以这样。 因此,我们需要谨慎考虑哪些操作可以并行运行。
java
List<Integer> list = Arrays.asList(1, 2, 3, 4);
Integer result1 = list.parallelStream().reduce(0, Integer::sum) + 5;
System.out.println(result1);Semaphore
应用
- Semaphore: 信号量 ,可以用来做限流器(单机版),在访问高峰期时,让请求线程阻塞,高峰期过去再释放许可,并且仅是限制线程数,而不是限制资源数
- 实现数据库连接池
Exchanger
Exchanger 是一个用于线程间协作的工具类,用于两个线程间交换数据。它提供了一个交换的同步点,在这个同步点两个线程能够交换数据。具体交换数据是通过 exchange 方法来实现的,如果一个线程先执行 exchange 方法,那么它会同步等待另一个线程也执行 exchange 方法,这个时候两个线程就都达到了同步点,两个线程就可以交换数据。
java
@Slf4j
public class exchanger {
public static void main(String[] args) {
Exchanger<Integer> exchanger = new Exchanger<>();
new Thread(new Runnable() {
@Override
public void run() {
int a = 2;
log.info("线程1开始交换数据");
try {
Integer b = exchanger.exchange(a);
log.info("交换成功,现在的数据为{},线程1做其他的处理", b);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}, "t1").start();
new Thread(new Runnable() {
@Override
public void run() {
int a = 10;
log.info("线程2开始交换数据");
try {
Integer b = exchanger.exchange(a);
log.info("交换成功,现在的数据为{},线程2做其他的处理", b);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}, "t1").start();
}
}CountDownLatch VS CyclicBarrier
CountDownLatch
CountDownLatch 用来进行线程同步协作,等待所有线程完成任务之后再执行逻辑
⚠️ notice: 使用 CountDownLatch 时最好将 latch.countDown() 放在 finally 中运行,防止出现了异常导致没有执行 latch.countDown() ,或者 await 的时候指定一个超时时间,以防止某些线程没有调用 latch.countDown() 导致死等
为什么不使用 join?
- CountDownLatch 使用起来更灵活, 使用 join 时需要获取到线程的引用,但是我们项目中大多数使用的是线程池,获取不到线程的引用,因此使用线程池的话不能使用 join
java
@Slf4j
public class countDownLatch {
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(3);
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 3; i++) {
int temp = i;
executorService.execute(new Runnable() {
@Override
public void run() {
try {
log.info("running");
Thread.sleep(1000 + 500 * temp);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
latch.countDown();
}
}
});
}
log.info("waiting");
latch.await(3, TimeUnit.SECONDS);
log.info("游戏开始");
}
}CyclicBarrier
CyclicBarrier: 循环栏栅, 用来进行线程之间的协作,当每个线程执行到某个需要“同步”的时刻调用 await()方法进行等待,当等待的线程数满足计数个数时,会停止等待,继续执行,也可以在构造函数中传入一个 Runnable 对象, 当等待的线程数满足计数个数时,会执行 Runnable 对象的 run 方法
java
@Slf4j
public class cyclicBarrier {
public static void main(String[] args) {
CyclicBarrier cyclicBarrier = new CyclicBarrier(5,
// 当
new Runnable() {
@Override
public void run() {
log.info("所有选手准备完成");
}
});
for (int i = 0; i < 5; i++) {
int temp = i;
new Thread(new Runnable() {
@SneakyThrows
@Override
public void run() {
Thread.sleep(1000);
log.info("选手{}准备完成", temp);
cyclicBarrier.await();
}
}, "t" + i).start();
}
}
}CountDownLatch 和 CyclicBarrier 的区别
二者用来进行线程同步协作的类,但是二者的侧重点不同,CountDownLatch 倾向于某个线程等待其他线程执行完毕,这个线程再继续执行;而 CyclicBarrier 一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行
调用 CountDownLatch 的 countDown 方法后,当前线程并不会阻塞,会继续往下执行;而调用 CyclicBarrier 的 await 方法,会阻塞当前线程,直到 CyclicBarrier 指定的线程全部都到达了指定点的时候,才能继续往下执行
CountDownLatch 是不能复用的,即当减为了 0 之后就不能再使用了。而 CyclicBarrier 是可以复用的(即这一组线程都达到指定点之后全部继续运行,之后其他线程或者这些线程还是可以继续调用 await,来等待到另一个临界点)
CompletableFuture
创建异步任务
- CompletableFuture.runAsync() 创建一个没有返回值的异步任务
- CompletableFuture.supplyAsync() 创建一个有返回值的异步任务
若没有传入线程池,默认使用 ForkJoinPool.commonPool() 作为线程池(里面的线程是守护线程)
常用 api
获取结果
get:获取返回的结果,需要在编译的时候处理异常
getNow(T valueIfAbsent): 和 get 类似,如果已经完成了,则返回计算的结果,否则返回所给的值;不需要在编译的时候处理异常,运行时若出现了异常则抛出异常
join:和 get 类似,获取返回的结果。but 不需要在编译的时候处理异常,运行时若出现了异常则抛出异常
complete(T value): 若此时没有完成,则使用所给的值返回
completeExceptionally(Throwable ex): 若此时还没完成,则抛出一个所给的异常
任务异步回调
thenApply/thenApplyAsync :第一个任务执行完成后,执行第二个回调方法任务,会将第一个任务的执行结果,作为入参,传递到回调方法中,并且回调方法是有返回值的。
java
CompletableFuture<Integer> completableFuture = CompletableFuture.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
return 11;
}
}).thenApply(new Function<Integer, Integer>() {
@Override
public Integer apply(Integer value) {
log.info("{}", value); //11
return value + 9;
}
});
System.out.println(completableFuture.join()); // 20thenApply/thenApplyAsync 的区别:
- 调用 thenRun 方法时,和上一个任务共用同一个线程池。
- 调用 thenRunAsync 方法时,则使用的是 ForkJoin 线程池
java
private static final Executor asyncPool = useCommonPool ?
ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();
public CompletableFuture<Void> thenRun(Runnable action) {
return uniRunStage(null, action);
}
public CompletableFuture<Void> thenRunAsync(Runnable action) {
return uniRunStage(asyncPool, action);
}thenAccept / thenAcceptAsync: 和 thenApply 类似, but thenAccept 的回调函数将上一个任务的执行结果作为入参,没有返回值
thenRun / thenRunAsync: 和 thenApply 类似,但是 thenRun 的参数是传入一个 Runnable 对象,没有返回值
多个任务组合处理
thenCombine / thenAcceptBoth / runAfterBoth 都表示:将两个 CompletableFuture 组合起来,只有这两个都正常执行完了,才会执行某个任务。
区别在于:
- thenCombine:会将两个任务的执行结果作为方法入参,传递到指定方法中,且有返回值
- thenAcceptBoth: 会将两个任务的执行结果作为方法入参,传递到指定方法中,且无返回值
- runAfterBoth 不会把执行结果当做方法入参,且没有返回值。
applyToEither / acceptEither / runAfterEither 都表示:将两个 CompletableFuture 组合起来,只要其中一个执行完了,就会执行某个任务。
区别在于:
- applyToEither:会将已经执行完成的任务,作为方法入参,传递到指定方法中,且有返回值
- acceptEither: 会将已经执行完成的任务,作为方法入参,传递到指定方法中,且无返回值
- runAfterEither: 不会把执行结果当做方法入参,且没有返回值。
allOf: 所有任务都执行完成后,返回一个 CompletableFuture 。如果任意一个任务异常,allOf 的 CompletableFuture,执行 get 方法,会抛出异常
anyOf: 任意一个任务执行完,返回一个 CompletableFuture。如果执行的任务异常,anyOf 的 CompletableFuture,执行 get 方法,会抛出异常
thenCompose: thenCompose 方法在 CompletableFuture 中用于组合两个异步操作。它允许你在第一个 CompletableFuture 完成后,使用其结果启动另一个异步操作,并返回一个新的 CompletableFuture. 相比于 thenApply 等 api ,thenCompose 相对灵活很多。
ConcurrentHashMap
线程安全的集合类
- 遗留的线程安全的集合类,内部都使用了
synchronized来保证线程安全 ,例如 HashTable 、Vector - 将线程不安全的集合类变为线程安全的集合类,调用 Collections.synchronizedMap() 、Collections.synchronizedList() 等方法
- JUC 包下的集合类
JDK1.8
java
// hash表
transient volatile Node<K,V>[] table;
// 整个table就是一个Node数组
static class Node<K,V> implements Map.Entry<K,V> {}
// 扩容时的新hash 表, 只有在扩容时不为null
private transient volatile Node<K,V>[] nextTable;
/*
用来做扩容控制的字段
-1 表示table 正在初始化
-(1+ 扩容线程数 )表示table 正在扩容
当table为null时, sizeCtl 为初始化table的大小 ,初始化/扩容完成之后, sizeCtl为下一次扩容的阈值
*/
private transient volatile int sizeCtl;
/**
* TreeNodes used at the heads of bins. TreeBins do not hold user
* keys or values, but instead point to list of TreeNodes and
* their root. They also maintain a parasitic read-write lock
* forcing writers (who hold bin lock) to wait for readers (who do
* not) to complete before tree restructuring operations.
*/
// 作为treebin 的头节点, 存储root 和first
static final class TreeBin<K,V> extends Node<K,V> {}
// treebin 的节点, 存储 parent ,left ,right
static final class TreeNode<K,V> extends Node<K,V> {构造函数
主要就是确定 table 初始化的大小
java
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// 确保table的大小>= 并发数
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
// 确定table初始化的大小,2^n
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}Put
java
// onlyIfAbsent为true时 ,只有key不存在时才会put , onlyIfAbsent为false(默认) 时,若key存在,则覆盖value
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 计算hash
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 当table还没初始化时,初始化table
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 找该 hash 值对应的数组下标,得到第一个节点 f,且没有元素,则之间插入
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 使用CAS插入,若插入不成功则进行下一轮循环
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// table正在扩容, 则去帮助别的线程一起扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
// 到这里就是说,f 是该位置的头节点,而且不为空
V oldVal = null;
// 获取数组该位置的头节点的锁(这里锁的是每个链表的头节点)
synchronized (f) {
if (tabAt(tab, i) == f) {
// hash >= 0, 表示是正常的链表
if (fh >= 0) {
// 用于累加,记录链表的长度
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果发现了"相等"的 key,判断是否要进行值覆盖,然后也就可以 break 了
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
//到了链表的末尾,将新的value插入链表的末尾
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// hash<0 ,判断是否是红黑树,使用
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
// 调用红黑树的插值方法插入新节点
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 判断是否要转为红黑色,即链表长度要>=8
if (binCount >= TREEIFY_THRESHOLD)
// 这里和hashMap一样,如果当前数组的长度小于 64,那么会选择进行数组扩容,而不是转换为红黑树
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 元素的个数累加,并且会尝试扩容
addCount(1L, binCount);
return null;
}initTable
java
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// sizeCtl< 0 ,说明正在初始化,则让出cpu的使用权,just spin
if ((sc = sizeCtl) < 0)
Thread.yield();
// 没有初始化,使用CAS将 sizeCtl 改为-1 ,代表抢到了锁
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
// DEFAULT_CAPACITY 默认初始容量是 16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
// 创建table
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
// sizeCtl 为下一次扩容的阈值
sizeCtl = sc;
}
break;
}
}
return tab;
}treeifyBin
java
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
// 当table的长度< 64时,进行扩容,而不是转为红黑树
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
// b为当前链表的头节点
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
if (tabAt(tab, index) == b) {
// 下面就是遍历链表,建立一颗红黑树
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
// 将红黑树设置到数组相应位置中
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}tryPresize
java
// size 传进来已经翻了一番了
private final void tryPresize(int size) {
// c = size *1.5 +1 ,再往上取最近的 2 的 n 次方。
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
// table没有初始化
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
}
}
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
else if (tab == table) {
// 是一个比较大的负数
int rs = resizeStamp(n);
// sc< 0,则表示正在扩容
if (sc < 0) {
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// 尝试帮助扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// 没有在扩容,则使用CAS尝试获取锁
else if (U.compareAndSwapInt(this, SIZECTL, sc,
//rs << RESIZE_STAMP_SHIFT) + 2 是一个负数
(rs << RESIZE_STAMP_SHIFT) + 2))
// 扩容
transfer(tab, null);
}
}
}transfer
此方法支持多线程执行,调用此方法的时候,会保证第一个发起数据迁移的线程,nextTab 参数为 null,之后再调用此方法的时候,nextTab 不会为 null。
阅读源码之前,先要理解并发操作的机制。原数组长度为 n,所以我们有 n 个迁移任务,让每个线程每次负责一个小任务是最简单的,每做完一个任务再检测是否有其他没做完的任务,帮助迁移就可以了,而 Doug Lea 使用了一个 stride,简单理解就是步长,每个线程每次负责迁移其中的一部分,如每次迁移 16 个小任务(多核 cpu 下最小为 16)。所以,我们就需要一个全局的调度者来安排哪个线程执行哪几个任务,这个就是属性 transferIndex 的作用。
第一个发起数据迁移的线程会将 transferIndex 指向原数组最后的位置,然后从后往前的 stride 个任务属于第一个线程,然后将 transferIndex 指向新的位置,再往前的 stride 个任务属于第二个线程,依此类推。当然,这里说的第二个线程不是真的一定指代了第二个线程,也可以是同一个线程。就是把一个很大的迁移任务分成了很多个小的迁移任务
java
// 将元素从旧的table 移动到新的table
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
// stride 在单核下直接等于 n,多核模式下为 n/8/NCPU,最小值是 16
// stride 可以理解为”步长“,有 n 个位置是需要进行迁移的,
// 将这 n 个任务分为多个任务包,每个任务包有 stride 个任务
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE;
// 如果 nextTab 为 null,先进行一次初始化
// 只有第一个调用的线程才为null
if (nextTab == null) { // initiating
try {
// 创建nextTab
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
// transferIndex 用于控制迁移的位置
transferIndex = n;
}
int nextn = nextTab.length;
// ForwardingNode 翻译过来就是正在被迁移的 Node
// 这个构造方法会生成一个Node,key、value 和 next 都为 null, hash 为 MOVED
// 当数组的下标为i的位置的节点迁移完毕之后,会将位置为i的元素设置为 ForwardingNode,来告诉其他线程这个位置已经处理过了
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// advance 指的是做完了一个位置的迁移工作,可以准备做下一个位置的了
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
// i 为索引位置,bound为边界,整体是从后往前遍历的
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
// 这个while循环,让 i 指向了 transferIndex,bound 指向了 transferIndex-stride(即边界)
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
// transferIndex <= 0,说明原数组的所有位置都有相应的线程去处理了
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
// 完成了迁移操作,重新赋值sizeCtl为新的table下一次扩容的阈值
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
// 之前我们说过,sizeCtl 在迁移前会设置为 (rs << RESIZE_STAMP_SHIFT) + 2
// 然后,每有一个线程参与迁移就会将 sizeCtl 加 1,
// 这里使用 CAS 操作对 sizeCtl 进行减 1,代表做完了属于自己的任务
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
// 到这里,说明 (sc - 2) == resizeStamp(n) << RESIZE_STAMP_SHIFT,
// 也就是说,所有的迁移任务都做完了,也就会进入到上面的 if(finishing){} 分支了
finishing = advance = true;
i = n;
}
}
// 如果位置 i 处是空的,没有任何节点,则不需要迁移,那么放入 ForwardingNode ”空节点“
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
//hash== -2 表示已经迁移过了
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
// 对链表的头节点加锁,进行迁移
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
// 进行红黑树的迁移
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// 如果一分为二后,节点数小于等于6,那么将红黑树转换回链表
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,
setTabAt(tab, i, fwd);
// advance 设置为 true,代表该位置已经迁移完毕
advance = true;
}
}
}
}
}
}HashTable 为什么慢?
hashTable 中使用了 synchronized 对 put 等操作进行加锁,并且 synchronized 锁住的是 hashTable, 因此并发度不高,效率很低
JDK1.7
JDK1.7 中采用的是一种分段锁的机制实现的 ConcurrentHashMap , ConcurrentHashMap 在对象中保存了一个 Segment 数组,即将整个 Hash 表划分为多个分段;**而每个 Segment 类似于一个 Hashtable **, 并发操作的时候对每个 Segment 加锁即可,这样相比于 HashTable 就提高了并发度
Segments 数组 大小默认为 16 ,且初始化之后不能变, 执行构造函数的时候就回初始化完成
构造函数
initialCapacity: 整个 hashMap 的容量,实际操作的时候需要平均分给每个 Segment。
loadFactor:负载因子,用于 Segments 扩容
concurrencyLevel: 并发数, 默认为 16 ,并发数要 >= Segment 数组的长度
java
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
// Segment 数组的长度,为2^n
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// initialCapacity 是设置整个 map 初始的大小,
// 这里根据 initialCapacity 计算 Segment 数组中每个位置可以分到的大小
// 最后计算出的cap 就是 每个 Segment 中 entry 的个数
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// 初始化 Segment 数组
// 并创建数组的第一个元素 segment[0]
// 为什么要在这里创建 Segment[0] 呢? 那是因为创建 Segment 的时候会需要用到一些 Segment的元数据 ,例如 entry 的长度, loadFactor,详情请看 ensureSegment方法的源码
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}Put
java
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
// 根据 hash 值找到 Segment 数组中的位置 j ,即找到相应的 Segment
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}ensureSegment
该方法用于创建 Segment
java
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
// 初始化 segment[k] 内部的数组
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))== null) { // recheck
// 创建Segment
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// 使用while 循环 + CAS的方式 来保证只有一个线程会成功初始化 Segment
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}Segment 类内部的 Put 方法
ConcurrentHashMap 中的 put 方法最终也是调用的 Segment 类内部的 put 方法完成对数据的插入
java
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 先尝试加锁,加锁不成功则调用 scanAndLockForPut 方法
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
// 到这里肯定加锁成功了
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// 看是否是相同的元素
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// e ==null ,说明没有hashMap中没有相同的元素
if (node != null)
// ,将新插入的节点设置为头节点(头插法)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// Segment 中的元素数量超过了阈值 ,扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}rehash
java
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;
// 新的阈值
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
// 计算应该放置在新数组中的位置,
// 假设原数组长度为 16,e 在 oldTable[3] 处,那么 idx 只可能是 3 或者是 3 + 16 = 19
int idx = e.hash & sizeMask;
// 这个链表只有一个元素,直接迁移即可
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// e 是链表表头
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// 下面这个 for 循环会找到一个 lastRun 节点,这个节点之后的所有元素是将要放到一起的,
// 即lastRun之后的元素的对应新的 Segment 的数组下标都相同
for (HashEntry<K,V> last = next; last != null; last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// 将lastRun及其之后的节点之间迁移到newTable
newTable[lastIdx] = lastRun;
// 对lastRun之前到节点进行处理,遍历所有的节点,一个一个迁移
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// 将新添加的node 添加进newTable中
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}get
java
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
// 这个hash值对应的 Segment 的下标
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 2. 根据 下标 找到对应的 segment
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 找到segment 内部 entry 数组相应位置的链表,遍历
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
// 存在这个元素
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}BlockingQueue
实现 BlockingQueue 接口的有ArrayBlockingQueue, DelayQueue, LinkedBlockingDeque, LinkedBlockingQueue, LinkedTransferQueue, PriorityBlockingQueue, SynchronousQueue
ArrayBlockingQueue
ArrayBlockingQueue 是一个使用数组实现的有界阻塞队列,ArrayBlockingQueue 一旦创建,容量不能改变。
LinkedBlockingQueue
LinkedBlockingQueue 是用链表实现的有界阻塞队列,同样满足 FIFO 的特性,与 ArrayBlockingQueue 相比起来具有更高的吞吐量,为了防止 LinkedBlockingQueue 容量迅速增,损耗大量内存。通常在创建 LinkedBlockingQueue 对象时,会指定其大小,如果未指定,容量等于 Integer.MAX_VALUE
LinkedBlockingDeque
LinkedBlockingDeque 是基于链表数据结构的有界阻塞双端队列,如果在创建对象时为指定大小时,其默认大小为 Integer.MAX_VALUE。与 LinkedBlockingQueue 相比,主要的不同点在于,LinkedBlockingDeque 具有双端队列的特性。
PriorityBlockingQueue
PriorityBlockingQueue 是一个支持优先级的无界阻塞队列(类似于堆)。基于数组实现的,默认长度为 11,最大长度为 Integer.MAX_VALUE - 8。
默认情况下元素采用自然顺序从小到大排序,也可以通过自定义类实现 compareTo()方法来指定元素排序规则,或者初始化时通过构造器参数 Comparator 来指定排序规则。
SynchronousQueue(同步队列)
SynchronousQueue 每个插入操作必须等待另一个线程进行相应的删除操作,因此,SynchronousQueue 实际上没有存储任何数据元素,因为只有线程在删除数据时,其他线程才能插入数据,同样的,如果当前有线程在插入数据时,线程才能删除数据。
使用场景:
Executors.newCachedThreadPool中使用SynchronousQueue来实现任务的直接交接。传递数据:在两个线程之间直接传递数据,而不需要中间缓存。
LinkedTransferQueue
LinkedTransferQueue 是一个由链表数据结构构成的无界阻塞队列,由于该队列实现了 TransferQueue 接口
和其他阻塞队列的区别是:
transfer(E e):如果有消费者正在等待接收元素,则直接传递元素;否则阻塞直到元素被消费。
tryTransfer(E e):尝试立即传递元素,如果没有消费者等待,则返回 false。
tryTransfer(E e, long timeout, TimeUnit unit):在指定的时间内尝试传递元素,如果超时则返回 false。
DelayQueue(延迟队列)
DelayQueue 是一个无界阻塞队列,用于存储实现了 Delayed 接口的元素 , 队列中的元素只有在其延迟期满后才能被提取.
具体使用可以查看如下的例子:
java
@Slf4j
public class delayQueue {
@SneakyThrows
public static void main(String[] args) {
DelayQueue<DelayedElement> queue = new DelayQueue<>();
DelayedElement element = new DelayedElement(1000, "hello");
ExecutorService executorService = Executors.newFixedThreadPool(3);
executorService.execute(new Runnable() {
@Override
public void run() {
queue.put(element);
log.info("放入元素");
}
});
executorService.execute(new Runnable() {
@Override
public void run() {
DelayedElement e = null;
try {
e = queue.take();
} catch (InterruptedException ex) {
throw new RuntimeException(ex);
}
log.info("取出元素{}", e.getMessage());
}
});
}
@Getter
static class DelayedElement implements Delayed {
private final long delayTime;
private final long expireTime;
private final String message;
public DelayedElement(long delayTime, String message) {
this.delayTime = delayTime;
this.expireTime = delayTime + System.currentTimeMillis();
this.message = message;
}
@Override
public long getDelay(TimeUnit unit) {
long diffTime = unit.convert(expireTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
return diffTime;
}
@Override
public int compareTo(Delayed other) {
return (int) (this.expireTime - ((DelayedElement) other).getExpireTime());
}
}
}CopyOnWriteArrayList / CopyOnWriteArraySet
设计思想
我们都知道 ArrayList 是线程不安全的, 对于它的替代品,我们可以使用 Vector 或者 Collections 的静态方法将 ArrayList 包装成一个线程安全的类,但是他们内部都是使用的 synchronized 来保证线程安全,并发度很低。
在实际应用中,往往都是读多写少的场景,这时候我们很容易想到使用 ReenTrantReadWriteLock , 通过读写分离的思想, 读读之间不会阻塞,可以提升效率
虽然 ReenTrantReadWriteLock 可以保证读读之间不会阻塞 ,但是当线程获取到写锁时,读线程还是会被阻塞。如果我们可以保证读写之间不会被阻塞的话,这样的话可以进一步提升效率
CopyOnWriteArrayList 使用了 COW 的思想,通过写时复制 + 延迟更新 来保证数据的最终一致性,并且读线程一定不会被阻塞。
简单来说就是在更新 list 的时候,先将原 list 复制一份,在新的 list 中更新数据,更新完毕之后替换旧的 list。并发读的时候不需加锁,因为当前的 list 不会添加元素,这样放弃了数据的强一致性提高了效率
java
// array 是 volatile的
private transient volatile Object[] array;get 方法实现
可以看出跟单线程的实现没什么区别
java
public E get(int index) {
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}add 方法实现
java
public boolean add(E e) {
final ReentrantLock lock = this.lock;
// 加锁保证同时只有一个线程写数据
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 将旧的数据复制一份
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 在末尾添加新元素
newElements[len] = e;
// 将旧数组引用指向新的数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}缺点
内存占用问题:因为 CopyOnWrite 的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象,如果 list 比较大,例如 200M ,那么 cow 就会比较浪费内存
数据一致性问题:CopyOnWrite 容器只能保证数据的最终一致性,不能保证数据的实时一致性。
ThreadLocal
顾名思义,ThreadLocal 就是线程的“本地变量”,即每个线程都拥有该变量的一个副本,达到人手一份的目的,这样就可以避免共享资源的竞争,这样就没有线程安全 问题了。这就是一种“空间换时间”的思想,每个线程拥有自己的“共享资源”,虽然内存占用变大了,但由于不需要同步,也就减少了线程可能存在的阻塞问题,从而提高时间上的效率。
ThreadLocal 是如何实现线程资源的隔离
比较容易想到的方法就是把 ThreadLocal 看作一个 Map ,然后每个线程是一个 key ,这样每个线程调用 get 方法获取值的时候,将自己作为 key 去 map 中获取值即可。但是这样的话 ThreadLocal 就成了共享变量,多线程访问 ThreadLocal 时又得保证线程安全。but ThreadLocal 就是用来避免共享资源的竞争,因此这样子设计肯定是不合理的。
jdk1.8 中的设计方案:
每个线程中有一个 map ,key 为 ThreadLocal ,value 为对应的值。这样每个线程就可以根据 ThreadLocal 去对应 map 中找到对应的值
这里的 map 和 hashMap 有点类似
- 同样是使用数组存储元素,数组的长度为 2^n
- 当 entry 的个数达到一定的数量的时候也会进行扩容(容量的 2/3)
- 采用了线性探测再散列的方式解决 hash 冲突 , 而不是使用拉链法
- entry 的 key 是弱引用(下文会讲)
java
// thread 对象中的 map
ThreadLocal.ThreadLocalMap threadLocals = null;
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
/**
* The initial capacity -- MUST be a power of two.
*/
private static final int INITIAL_CAPACITY = 16;
/**
* The table, resized as necessary.
* table.length MUST always be a power of two.
*/
private Entry[] table;
/**
* The number of entries in the table.
*/
private int size = 0;
/**
* The next size value at which to resize.
*/
private int threshold; // Default to 0
}理解 ThreadLocal 中的内存泄漏问题
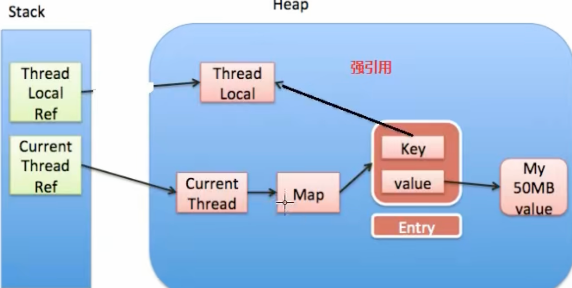
ThreadLocalMap 中的 key 为强引用时
看下面这张内存的引用图
- 若 key 为强引用,当 ThreadLocal 使用完了,置为了 null ,但此时由于 entry 中的 key 还是强引用,导致堆中的 ThreadLocal 对象不能被回收,发生了内存泄漏
- 在没有手动删除这个 entry 以及 线程仍然运行的情况下,有这样一条强引用链 currentThreadRef -> currentThread -> Map -> entry,因此 entry 会内存泄漏
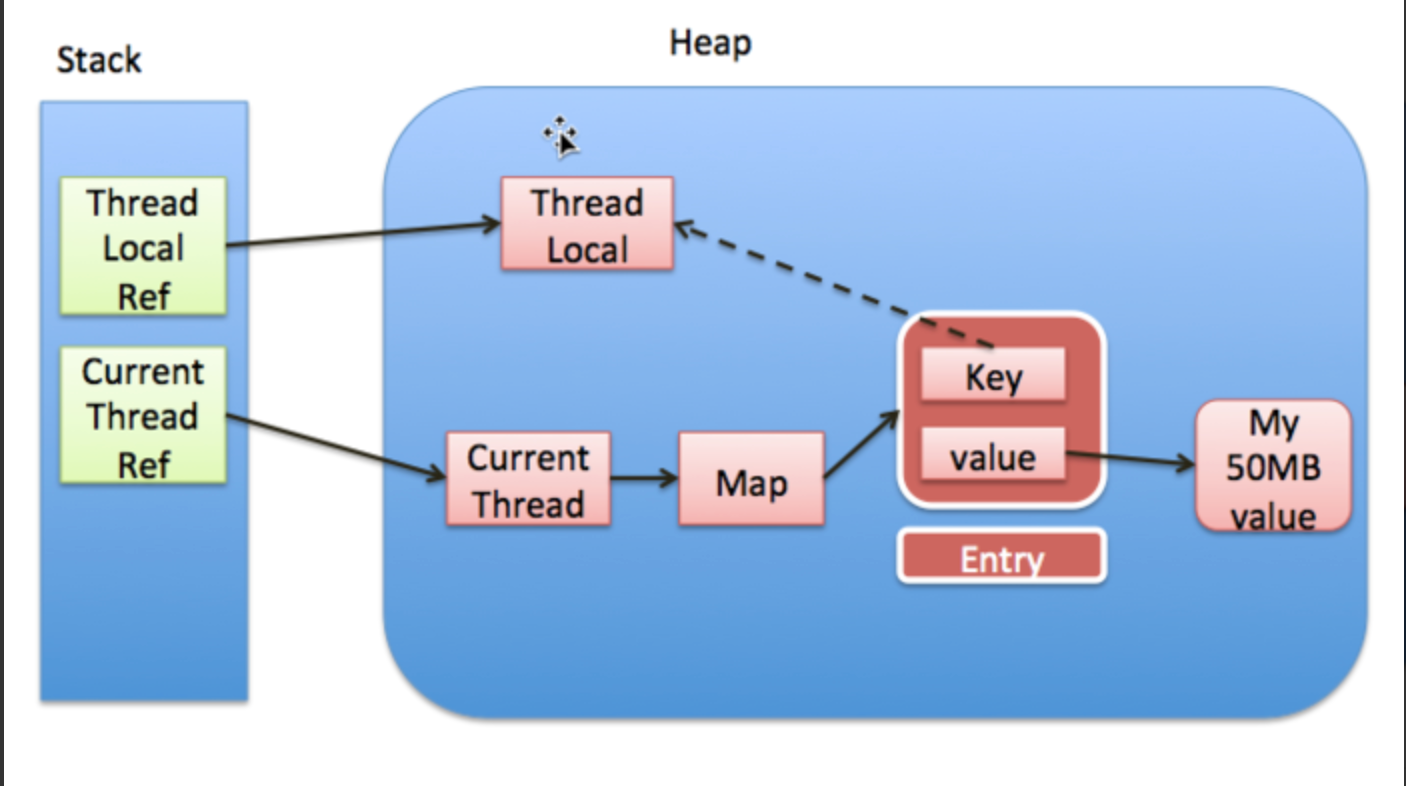
ThreadLocalMap 中的 key 为弱引用时
当 key 为弱引用时,当 ThreadLocal 使用完了,置为了 null ,此时没有任何强引用指向 ThreadLocal ,因此 ThreadLocal 可以被顺利 GC ,此时 entry 中的 key == null
在没有手动删除这个 entry 以及 线程仍然运行的情况下,有这样一条强引用链 currentThreadRef -> currentThread -> Map -> entry,因此 entry 会内存泄漏
因此即使 key 使用了弱引用, 也可能发生内存泄漏
jdk 中为解决内存泄漏做出的努力
为了解决这个内存泄漏的问题,jdk 中在很多地方都做了清理无用的 key 的操作(即清除 key ==null 的 entry)
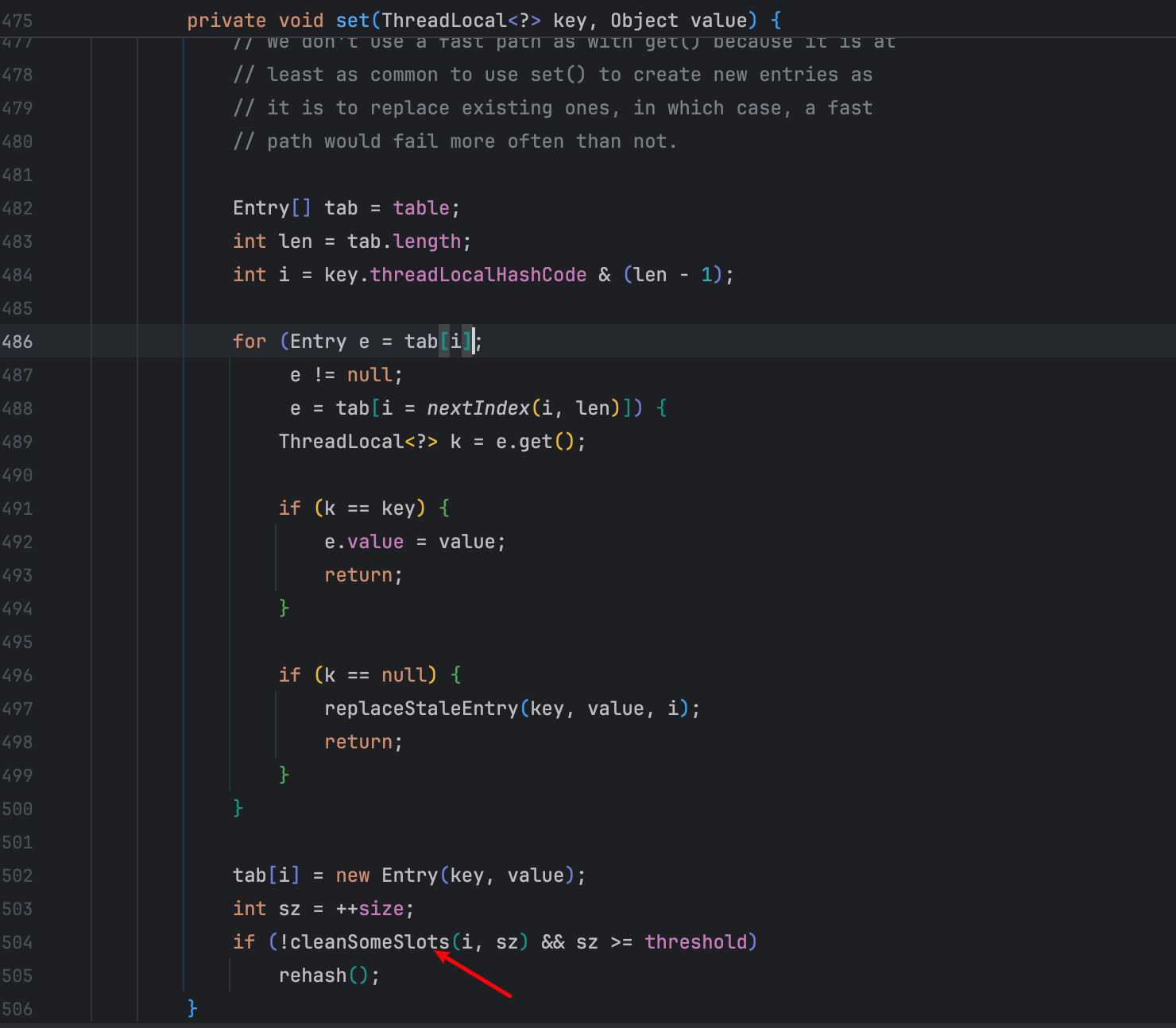
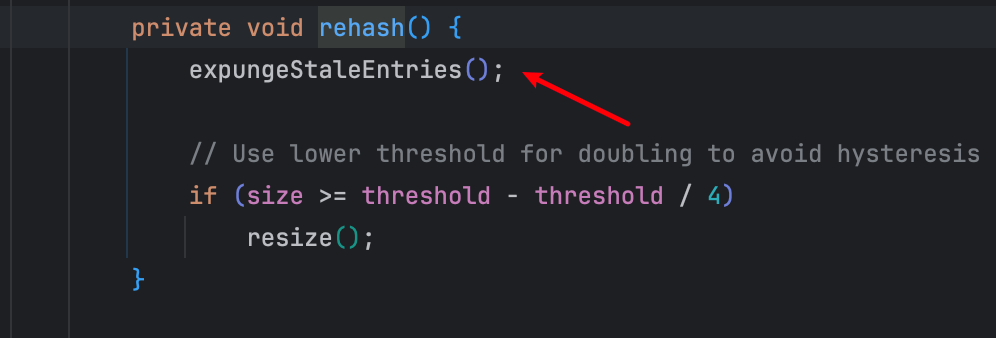
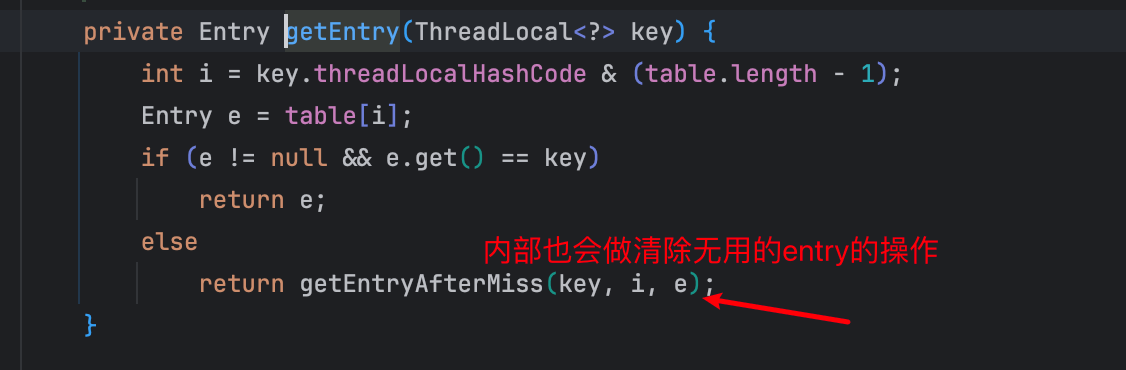
remove 操作
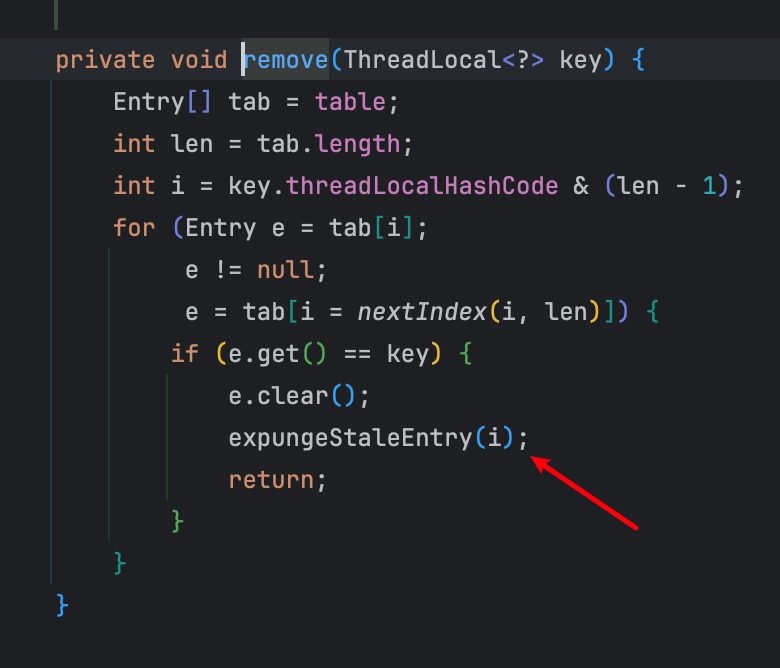
set 操作
rehash 操作
get 操作
总结
从上面的分析可以看出,当 key 使用了弱引用,此时 ThreadLocal 变量不会发生内存泄漏,但是若没有不手动清除不需要的 entry ,还是会导致 entry 发生内存泄漏。这里的清除有两种方法:
- 关闭线程。关闭线程之后线程就被回收了,因此线程中的 map 也就被 GC 了
- 调用 remove 方法。
但是,我们平常在项目中经常是使用线程池,线程不会被销毁,所以这就要求我们开发者养成良好的习惯,使用完了 ThreadLocal 要手动 remove 掉,以防止内存泄漏
ThreadLocal 的使用场景
ThreadLocal 的使用场景非常多,比如说:
- 用于保存用户登录信息,这样在同一个线程中的任何地方都可以获取到登录信息。
- 用于保存数据库连接、Session 对象等,这样在同一个线程中的任何地方都可以获取到数据库连接、Session 对象等。
- 用于保存事务上下文,这样在同一个线程中的任何地方都可以获取到事务上下文。
- 用于保存线程中的变量,这样在同一个线程中的任何地方都可以获取到线程中的变量。
- 在日志记录中,可以使用 ThreadLocal 来存储每个线程的日志上下文信息,例如请求 ID,以便在日志中跟踪特定请求的所有操作。
TransmittableThreadLocal
我们都知道 ThreadLocal 中保存的是当前线程的数据,想象一下有这样一个场景,父线程创建了一个子线程,想要将父线程中 ThreadLocal 的值传递给子线程,这时候如果还是使用 ThreadLocal 的话,子线程就获取不到父线程中 ThreadLocal 中的值,具体可以看下面的代码
java
IntegerThreadLocal threadLocal = new IntegerThreadLocal();
threadLocal.set(100);
new Thread(new Runnable() {
@Override
public void run() {
log.info("{}", threadLocal.get()); // null
}
}, "t1").start();
log.info("{}", threadLocal.get()); // 100基于上面的问题,我们有了 InheritableThreadLocal
InheritableThreadLocal
由于 ThreadLocal 父线程无法传递本地变量到子线程中,于是 JDK 引入了 InheritableThreadLocal 类,该类的首部描述:该类继承了 ThreadLocal 类,用以实现父线程到子线程的值继承;创建子线程时,子线程将接收父线程具有值的所有可继承线程局部变量的初始值。通常子线程的值与父线程相同;子线程的值可以被父线程重写的方法改变。
InheritableThreadLocal 的原理:
Thread 的源码中有这样一个成员属性,类似于 threadLocals ,只不过它的针对是 InheritableThreadLocal ,key 存储的是 InheritableThreadLocal ,value 存储对应的值
java
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;在线程初始化的代码中有这么一行,他会将父线程的 inheritableThreadLocals 变量拷贝到 子线程中,因此这样就实现了父线程到子线程的变量传递
java
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc,
boolean inheritThreadLocals) {
...
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
}测试代码:
下面的测试代码中,父子线程都输出了 100,成功地将父线程的 ThreadLocal 的数据传递给了子线程
java
ThreadLocal<Integer> threadLocal = new InheritableThreadLocal<>();
threadLocal.set(100);
new Thread(new Runnable() {
@Override
public void run() {
log.info("{}", threadLocal.get()); // 100
}
}, "t1").start();
log.info("{}", threadLocal.get()); // 100InheritableThreadLocal 在其他场景存在的问题
从上面的例子中可以看出,只有在线程初始化的时候才会将父线程的 inheritableThreadLocals 复制到子线程,但是在项目中我们经常是使用线程池,因此复用的是线程池中的线程,inheritableThreadLocals 在线程池的场景下就不管用了
TransmittableThreadLocal
TransmittableThreadLocal 就是为了解决在使用线程池的时候需要传递 ThreadLocal 值的问题
xml
<!--引入依赖 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>transmittable-thread-local</artifactId>
<version>2.14.5</version>
</dependency>修饰线程池
java
ThreadLocal<Integer> threadLocal = new TransmittableThreadLocal<>();
// 包装线程池
ExecutorService executorService = TtlExecutors.getTtlExecutorService(Executors.newFixedThreadPool(2));
for (int i = 0; i < 5; i++) {
threadLocal.set(i);
executorService.execute(new Runnable() {
@Override
public void run() {
log.info("{}", threadLocal.get());
}
});
}使用 Java Agent 来修饰 JDK 线程池实现类
这种方式,实现线程池的传递是透明的,业务代码中没有修饰Runnable或是线程池的代码。即可以做到应用代码 无侵入。
- 配置启动参数,点击 Add VM options
- 添加 -javaagent:path/to/transmittable-thread-local-2.x.y.jar
变量的线程安全分析

并发设计模式
两段式终止模式
java
@Slf4j
public class Monitor {
private static Thread monitor;
// 保证可见性
private volatile boolean stop = false;
public void stop() {
stop = true;
monitor.interrupt();
}
public void beforeExit() {
log.info("处理后事");
}
public void start1() throws InterruptedException {
monitor = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
if (stop) {
beforeExit();
return;
}
try {
Thread.sleep(1000);
log.info("执行监控逻辑");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}, "monitor");
monitor.start();
}
public static void main(String[] args) throws InterruptedException {
Monitor monitor = new Monitor();
monitor.start1();
Thread.sleep(1000);
new Thread(new Runnable() {
@Override
public void run() {
monitor.stop();
}
}, "t1").start();
}
}Balking(犹豫)模式
Balking(犹豫)模式用于一个线程发现另一个线程或本线程已经做了某一件相同的事,那么本线程就无需再做了,直接 return;有点类似单例模式
还是这个监视器的例子,为了防止多次调用监视器的 start 方法,我们可以添加一个 starting 变量,使用 synchronized 来防止线程安全的问题
java
@Slf4j
public class Monitor {
private static Thread monitor;
private volatile boolean stop = false;
// 判断是否已经start
private boolean starting = false;
public void stop() {
stop = true;
starting = false;
monitor.interrupt();
}
public void beforeExit() {
log.info("处理后事");
}
public void start1() throws InterruptedException {
// 防止线程安全问题
synchronized (this) {
// 如果已经start,则直接return
if (starting) {
return;
}
starting = true;
}
monitor = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
if (stop) {
beforeExit();
stop = false;
return;
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
log.info("执行监控逻辑");
}
}
}, "monitor");
monitor.start();
}
}消费者、生产者模型
java
public class 生产者消费者模型 {
public static void main(String[] args) {
}
}
// 消息队列
class MessageQueue {
// 消息队列,存放消息
private final Queue<Message> queue = new LinkedList<>();
// 消息队列的容量
private final int capcity;
public MessageQueue(int capcity) {
this.capcity = capcity;
}
// 获取消息
public Message take() throws InterruptedException {
synchronized (queue) {
while (queue.isEmpty()) {
queue.wait();
}
}
Message message = queue.poll();
queue.notifyAll();
return message;
}
// 存入消息
public void put(Message message) throws InterruptedException {
synchronized (queue) {
while (queue.size() >= capcity) {
queue.wait();
}
}
queue.add(message);
queue.notifyAll();
}
}
@ToString
@Getter
@Setter
@AllArgsConstructor
// 消息类
class Message {
private Integer id;
private Object value;
}常见的线程安全类
String 、Integer、StringBuffer、Random、Vector、HashTable、java.util.concurrent 包下的类
文章作者:leftover
版权声明: 所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 leftover!