本站总访问量次
Java8新特性小结
作者:leftover
字数统计:11.6k 字
阅读时长:62 分钟
- try() {} 语句,可以不需要在finally块中编写释放资源的操作,会自动释放资源
Java9新特性小结
moudle,模块化
jshell,交互式命令行工具
接口可以添加私有方法
以前匿名内部类中不能有< >,必须写明具体的泛型,Java9之后可以写< >,利用类型推导出对应的类型
对try() {} 语句进行了优化,可以不需要在()初始化资源了,例如下面
java// jdk9中 中,对try() {}进行了优化,可以不需要在括号中对资源初始化,只需要在括号中声明有哪些资源即可 ByteArrayInputStream byteArrayInputStream1 = new ByteArrayInputStream(data); FileWriter writer1 = new FileWriter("/Users/leftover/project/study_java/new02.txt"); // 只需声明有哪些资源即可 try (byteArrayInputStream1; writer1) { int c1; while ((c1 = byteArrayInputStream1.read()) != -1) { writer1.write(c1); System.out.print((char) c1); }将String的底层实现由char[] 改为了byte[],对应的StringBuilder和StringBuffer也进行了改变,内部使用了一个coder字段来表明编码方式,
如果一个字符串都是能用LATIN1编码表示,coder为0,则使用的是LATIN1编码(一个字符使用1byte存储),否则coder为1,使用的是UTF-16编码(跟Java8一样的编码),一个字符使用2个byte存储字节流中的transferTo是Java9加入的,字符流中的transferTo方法是Java10 加入的,都是输入流中的所有数据直接复制到输出流中并写入
新增了几个集合api
List.of,Set.of,Map.of,Map.ofEntries可以创建只读的集合Optional 类添加了一个新方法,
stream方法返回一个流新增了几个Stream api :
Stream.iterate,takeWhile,dropWhile,Stream.ofNullablejava// 新增的重载方法,可以有一个终止条件,而不是无限流 Stream.iterate(0, i -> i < 99, i -> i + 1).forEach(System.out::println); System.out.println("-==========="); // List<Integer> list = List.of(1, 2, 4, 6, 8, 3, 66, 88, 44, 33, 22); // 从Stream中依次获取满足条件的元素,直到不满足条件为止结束获取 list.stream().takeWhile(i -> i < 6).forEach(System.out::println); System.out.println("==========="); // 从Stream中依次删除满足条件的元素,直到不满足条件为止结束删除 list.stream().dropWhile(i -> i < 6).forEach(System.out::println); /*对于Stream.of 方法,可以传入一个或者多个参数 若传入一个参数,则不能为null,否则抛出NPE Stream.ofNullable方法只能传入一个参数,可以为null ,为null则返回的是一个空流 */ Stream.of(1,2,3,null); Stream.of(null); long count =Stream.ofNullable(null).count(); System.out.println(count);
Java10新特性
局部变量类型推断
java// 以前的写法 List<Integer> arrayList = new ArrayList<>(); // 使用了局部类型推断(可以根据右边的类型推断出来,只能用于局部变量) // 其实编译器编译之后会将类型加上去,其实编译器帮我们做了这件事 var arrList1 = new ArrayList<Integer>();新增方法
List.copyOf(),传入一个list,创建一个只读集合.⚠️:若传入的list本身就是只读的,则返回的list和传入的list是同一个
若传入的list不是只读的,则会新创建一个只读的list
Java17新特性
Record类(jdk14)
- record类是一个不可变类,只能读取,只能在创建对象的时候赋值,没有set方法,final类,属性不可修改,不能声明普遍成员变量,只能声明static成员变量,自己实现了equals ,hashcode,toString方法
- ⚠️可以自己创建无参的构造方法,但是编译之后无参的构造方法中的内容会合并到全参数的构造方法中(放在开头)
- 也可以自己创建部分参数的构造方法
java
@Test
public void test() {
Record新特性 zwc = new Record新特性("zwc", 19);
System.out.println(zwc);
System.out.println(zwc.age());
System.out.println(zwc.username());
if (zwc instanceof Record新特性(String username, Integer age)) {
//这里面可以使用record里面的字段
if (age > 18) {
System.out.println(true);
} else {
System.out.println(false);
}
} else {
System.out.println(false);
}
//判断某个类是否为record
System.out.println(zwc.getClass().isRecord());
// 获得该record类所有的字段的类型 java.lang.String username 、java.lang.Integer age
RecordComponent[] components = zwc.getClass().getRecordComponents();
for (RecordComponent recordComponent : components) {
System.out.println(recordComponent);
}
}switch表达式(JDK12)
无需写break,不会穿透,并且switch表达式可以有返回值
java
public static void main(String[] args) {
int day = new Scanner(System.in).nextInt();
// 无返回值
switch (day) {
case 0, 6 -> {
System.out.println("休息日");
}
case 1, 2, 3, 4, 5 -> {
System.out.println("工作日");
}
default -> {
System.out.println("输入的日期有误");
}
}
// Object obj = new Circle(8);
Object obj = new Rectangle(2,4);
// 有返回值,可以使用yield来返回值
int result = switch (obj) {
case Circle(Integer r) -> {
yield (int) Math.PI * r * r;
}
case Rectangle(Integer width, Integer height) -> {
yield width * height;
}
default -> {
System.out.println("没有这个图形");
yield 0;
}
};
System.out.println(result);
}文本块(JDK15)
⚠️文本块的“”“ 必须单独占一行
java
public static void main(String[] args) {
// 所见即所得
String text = """
hello
world
""";
System.out.print(text);
// 也可以用\来表示不换行,代码中看起来是换行的,但是实际打印出来是没有换行的
String text1 = """
hello \
world
""";
System.out.println(text1); //hello world
// 格式化
String text2 = """
hello %s
""".formatted("zwc");
System.out.println(text2);
}密闭类(JDK17)
- 可以限制继承,只有被允许的子类才可以继承这个类
- 如果一个类继承了密闭类 ,那么这个子类可以为final , sealed ,non-sealed(不再是密闭类,子类可以继承它)
- 可以对接口使用,用法和效果一致
java
//密闭类,限制只有Red, Green类能继承此类
public sealed class Color permits Red, Green {
}序列化与反序列化
transient 关键字
一个类只要实现了
Serilizable接口,那么他就可以序列化在实际开发过程中,我们常常会遇到这样的问题,一个类的有些字段需要序列化,有些字段不需要,比如说用户的一些敏感信息(如密码、银行卡号等),为了安全起见,不希望在网络操作中传输或者持久化到磁盘文件中,那这些字段就可以加上
transient关键字。被
transient关键字修饰的成员变量在反序列化时会被自动初始化为默认值,例如基本数据类型为 0,引用类型为 nulltransient 使用小结
- transient 关键字只能修饰字段,而不能修饰方法和类。
- static变量均不能被序列化
序列化接口Serilizable 和 Externalizable 的区别
- 在 Java 中,对象的序列化可以通过实现两种接口来实现,如果实现的是 Serializable 接口,则所有的序列化将会自动进行,如果实现的是 Externalizable 接口,因为 Externalizable 接口需要实现 readExternal 和 writeExternal 方法,需要手动完成序列化和反序列化的过程,因此 与 transient 关键字修饰无关
- Serializable 是 Java 标准库提供的接口,而 Externalizable 是 Serializable 的子接口
- Externalizable 接口提供了更高的序列化控制能力,可以在序列化和反序列化过程中对对象进行自定义的处理,如对一些敏感信息进行加密和解密
== 和equals 的对比
==
- ==既可以判断基本类型,也可以判断引用类型
- ==判断基本类型时,判断值是否相等
- ==判断引用类型时,判断的是地址是否相等,即是否是同一个对象
equals
equals 是Object类中的方法,只能用来判断引用类型 ,默认是判断两个对象的地址是否相等,但是很多子类往往会重写equals方法,
例如String类,Integer类
访问修饰符
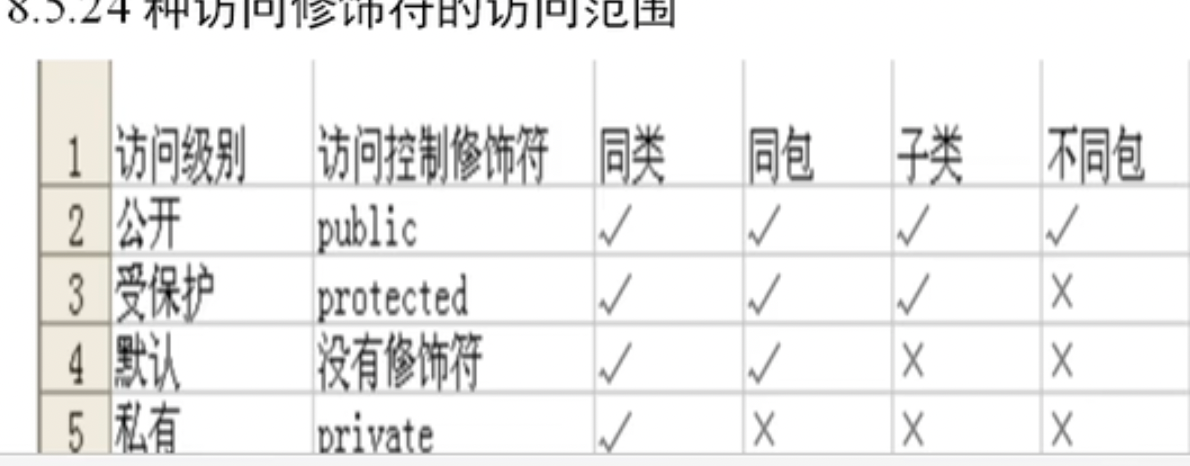
静态变量和静态方法
- 静态方法中不能访问成员方法和成员变量,只能调用静态变量和静态方法
- 静态方法中不能实验this,super等关键字
final
- final 修饰的类不能呗继承
- final修饰的方法不能被重写
- final修饰的属性和局部变量不能被修改
- final不能修饰构造方法
- 如果一个类用了final 修饰, 则该类的方法没必要使用final修饰了
- final 和static 同时使用,效率更高,不会导致类的加载
抽象类
- 不能使用final ,static ,private 修饰抽象方法,因为这与重写相违背
- 一个类继承了某个抽象类,必须实现所有的抽象方法,除非这个类也是抽象类
接口
jdk7之前,接口中的方法都是抽象方法 ,jdk8以后可以有静态方法,默认方法(不能直接使用接口名调用),抽象方法
接口中的方法默认都具有 public abstract
普通类实现接口,必须实现接口的所有方法,抽象类可以不用实现接口的方法
接口中的所有属性都是public static final
接口的修饰符只能是public 和default
默认方法的使用以及注意事项
⚠️若两个接口有相同方法名的默认方法,则子类必须重写接口的默认方法
⚠️使用 接口名.super.方法名(...)调用接口的默认方法
java
public class 接口的默认方法 {
public static void main(String[] args) {
flyable f = new flyable() {};
// 正常情况的话直接使用实现类调用默认方法即可
f.say();
}
}
interface flyable {
default void say() {
System.out.println("say hello");
}
}
interface swimmable {
default void say() {
System.out.println("say hi");
}
}
class Person implements flyable ,swimmable {
// ⚠️若两个接口有相同方法名的默认方法,则子类必须重写接口的默认方法
// ⚠️使用 接口名.super.方法名(...)调用接口的默认方法
@Override
public void say() {
// 调用flyable接口的默认方法
flyable.super.say();// or swimmable.super.say();
}
}内部类
- 内部类定义在外部类的局部位置上(比如方法内): (不能添加访问修饰符)
- 局部内部类
- 匿名内部类
- 定义在外部类的成员位置上 (可以添加访问修饰符)
- 成员内部类(没用static修饰)
- 静态内部类(用了static修饰)
局部内部类
- 不能用访问修饰符修饰 ,可以用final修饰(让这个类不能被继承)
- 外部类中和内部类中有属性相同,就近原则 ,若要访问外部类的属性,可使用
类名.this.属性名,例Outer.this.xxx
匿名内部类
- 一般用于实现接口、抽象类,普通类也可以(普通类用得少),当作参数传递
- 不能用访问修饰符修饰 ,可以用final修饰(让这个类不能被继承)
- 外部类中和内部类中有属性相同,就近原则 ,若要访问外部类的属性,可使用
类名.this.属性名,例Outer.this.xxx
java
// 使用方法
new 接口/类 (参数列表) {
// 重写/实现方法
}成员内部类
- 外部类中和内部类中有属性相同,就近原则 ,若要访问外部类的属性,可使用
类名.this.属性名,例Outer.this.xxx
java
// 外部其他类访问该内部类
Outer outer = new Outer();
Outer.Inner inner = outer.new Inner();静态内部类
- 和成员内部类相似,但是使用了static 修饰
- 可以直接访问外部类的所有静态成员,包括私有的,但是不能访问非静态成员
java
// // 外部其他类访问该内部类
Outer1.Inner1 inner1 = new Outer1.Inner1();枚举类
自己实现枚举类
- 构造器私有化
- 本类内部创建一组对象
- 对外暴露创建的对象(public static final 修饰)
- 可以提供get方法,但是不能提供set方法
java
public class Main {
public static void main(String[] args) {
System.out.println(Season.AUTUMN);
System.out.println(Season.SPRING);
System.out.println(Season.WINDER);
System.out.println(Season.SUMMER);
}
}
class Season {
private String name ;
private String desc;
public static final Season SPRING = new Season("春天","温暖");
public static final Season SUMMER = new Season("夏天","炎热");
public static final Season AUTUMN = new Season("秋天","凉爽");
public static final Season WINDER = new Season("冬天","寒冷");
//构造器私有化
private Season(String name, String desc) {
this.name = name;
this.desc = desc;
}
//只有get方法
public String getName() {
return name;
}
public String getDesc() {
return desc;
}
@Override
public String toString() {
return this.getClass() + " " + name + " " +desc;
}
}使用enum关键字实现枚举类
- 使用enum开放一个枚举类,会默认继承Enum类 ,且自己的类是一个final类
- 枚举对象必须放在枚举类的行首
- 多个枚举对象时,使用
,隔开,最后一个使用;结尾 , 若使用无参构造器,则可以省略括号 - 由于使用enum实现枚举类已经隐式地继承了Enum类,故它不可以再继承其他类了,but 可以实现接口
java
package 枚举类.使用enum关键字实现枚举类;
public class Main {
public static void main(String[] args) {
System.out.println(Season.SPRING);
System.out.println(Season.SUMMER);
}
}
enum Season {
//枚举对象放在行首,且默认都添加了public static final修饰符
//WHAT使用了无参构造器
SPRING("春天", "温暖"), SUMMER("夏天", "炎热"), WHAT;
private String name;
private String desc;
//这里的构造器的访问修饰符默认是私有,不能是其他的
private Season(String name, String desc) {
this.name = name;
this.desc = desc;
}
private Season() {
}
public String getName() {
return name;
}
public String getDesc() {
return desc;
}
@Override
public String toString() {
return this.getClass() + " " + name + " " + desc;
}
}四种元注解
- @Retention ,指定注解的作用范围,有三种值,RetentionPolicy.SOURCE,RetentionPolicy.CLASS,RetentionPolicy.RUNTIME
- RetentionPolicy.SOURCE:只在编译阶段使用,编译器使用之后直接丢弃这种策略的注解
- RetentionPolicy.CLASS :编译器会把注解记录在class文件中,当运行Java程序时,JVM不会保留注解。(默认值)
- RetentionPolicy.RUNTIME:编译器会把注解记录在class文件中,当运行Java程序时,JVM会保留注解,程序可以通过反射获取该注解
- @Target :指定注解可以在哪些地方使用
- @Documented :指定该注解是否会在javadoc中体现
- @Inherited:子类会继承父类的注解
异常
try-catch
- 可以有多个catch语句,但是父类要放在最后面
try-catch-finally执行顺序
如果没有异常出现,则执行try中的所有语句,再执行finally再的语句,不会执行catch中的语句
如果出现异常,则try块在异常发生后,try块中的语句不再执行,执行catch中的语句,若有finally,则还需执行finally中的语句
⚠️注意:无论catch和try中有没有return 语句,都会执行finally中的代码,若finally中的代码有返回值,则以finally中的为准
若finally中的代码没有返回值,则以catch块或者try中的为准(有异常则以catch为准,没有异常则以try为准)
抛出异常
对于编译异常,程序中必须处理, 对于运行时异常,若程序中没有处理,则默认是throw的方式处理
子类重写父类的方法时,对抛出异常的规定:子类不能扩大父类抛出异常的范围 , 即子类所抛出的异常类型必须与父类一致或者为父类的子类型
抛出异常的写法:
javapublic static void hi() throws ArithmeticException { int n1 = 4; int n2 = n1 / 0; }
throws VS throw
- throws是异常处理的一种方式(即继续向上抛出异常),在方法定义处声明,后面跟异常类型
java
public static void hi() throws ArithmeticException {
}throw 是手动生成异常的关键字,使用在方法体中,后面跟的是一个异常对象
javathrow new ArithmeticException("出现了一个异常");
Java的八种数据类型及其包装类
boolean 、char、byte、short、int、long、float、double
Boolean、Character、Byte、Short、Integer、Long、Float、Double
Integer
jdk5之前需要手动装箱和拆箱(目前的jdk版本都支持)
javaInteger integer1 = Integer.valueOf(99); Integer integer2 = new Integer(100); int b = integer1.intValue();jdk5之后可以自动装箱或者拆箱
javaInteger integer = 22; int a = integer;对于
Integer integer = 22;,其本质上调用的是Integer.valueOf()方法,首先会判断其是否是-128 ~127 ,若是,则会从缓存中取对象,而不会重写new 一个Integer 对象, 若不在这个范围,则会调用 new Integer() 创建一个对象
String
String 本质上也是使用字符数组来存储字符串的内容,其对象里有一个
public final char value []的字符数组用来存字符串的内容字符串的字符使用的是Unicode字符编码,一个字符(不区分字母还是汉字)占2个字节
字符串格式化的方法
javaString.format("我的名字是%s,年龄是%d,工资是%.2f,性别是%c", name, age, sal, sex)
字符串创建原理
使用字面量的方式创建字符串:首先会在常量池中查看是否有这样一个相同的字符串,若没有则在常量池中创建一个,最后将变量指向常量池这个字符串的地址
使用new String 的方式创建字符串:先在堆中创建一个String 对象 (str),再在常量池中查看是否有这样一个相同的字符串,若没有则在常量池中创建一个,最后将堆中创建的String对象(str)的value数组指向常量池这个字符串的地址,最后再将变量s指向堆中 String 对象的地址
String str = a+"gag";
首先会创建一个StringBuilder 对象,然后分别append (a) 和append (“gag”), 最后通过new String () 转为String
java
//正是由于创建方式的不同,所以才会导致下面的结果
String str1 ="hhh";
String str2 = "hhh"
str1==str2 ? // true
String str3 = new String ("hhh");
str1 ==str3 ? // falseStringBuffer 和StringBuilder
- StringBuilder 没有实现线程安全,推荐其在单线程条件下使用,StringBuffer实现了线程安全,推荐其在多线程条件下使用
- String 效率低,但是复用率高
BigInteger 和BigDecimal
BigInteger 适合保存非常大的整数;BigDecimal 适合保存精度更高的浮点数
二者均不能直接用+-*/进行运算,需要调用对应的方法运算
java
BigInteger bigInteger= new BigInteger("1473775365666666666667346375636563765763576375663858385836");
BigInteger bigInteger1 =new BigInteger("27874");
System.out.println( bigInteger.add(bigInteger1));
System.out.println( bigInteger.subtract(bigInteger1));
System.out.println( bigInteger.multiply(bigInteger1));
System.out.println( bigInteger.divide(bigInteger1));java
BigDecimal bigDecimal = new BigDecimal("4378758745878.25875874757457748584758487584758784758");
BigDecimal bigDecimal1 = new BigDecimal("2324.34");
System.out.println(bigDecimal.add(bigDecimal1));
System.out.println(bigDecimal.subtract(bigDecimal1));
System.out.println(bigDecimal.multiply(bigDecimal1));
//除法可能除不尽,则可能报错,可以指定需要保留的精度
System.out.println(bigDecimal.divide(bigDecimal1));
//保留跟被除数一样的精度
System.out.println(bigDecimal.divide(bigDecimal1, RoundingMode.CEILING));
System.out.println(bigDecimal.divide(bigDecimal1, RoundingMode.DOWN));
System.out.println(bigDecimal.divide(bigDecimal1, RoundingMode.FLOOR));
System.out.println(bigDecimal.divide(bigDecimal1, RoundingMode.HALF_UP));Random 与SecureRandom
Random类是伪随机,SecureRandom 类是真随机,SecureRandom的安全性是通过操作系统提供的安全的随机种子来生成随机数。这个种子是通过CPU的热噪声、读写磁盘的字节、网络流量等各种随机事件产生的“熵”。
java
// 伪随机,给定的种子相同时,多次运行的结果一致,若构造器中没有传入参数,则使用的是时间戳作为种子,
// 因为时间戳一直在变化,所以每次运行的结果一致
Random rd = new Random(121);
for (int i = 0; i < 10; i++) {
int num = rd.nextInt(100);
System.out.println(num);
}
System.out.println("======================");
byte[] arr = {1, 2, 23};
// 真随机,每次运行的结果都不相同
SecureRandom rd1 = new SecureRandom(arr);
for (int i = 0; i < 10; i++) {
int num = rd1.nextInt(100);
System.out.println(num);
}时间相关的类
Date
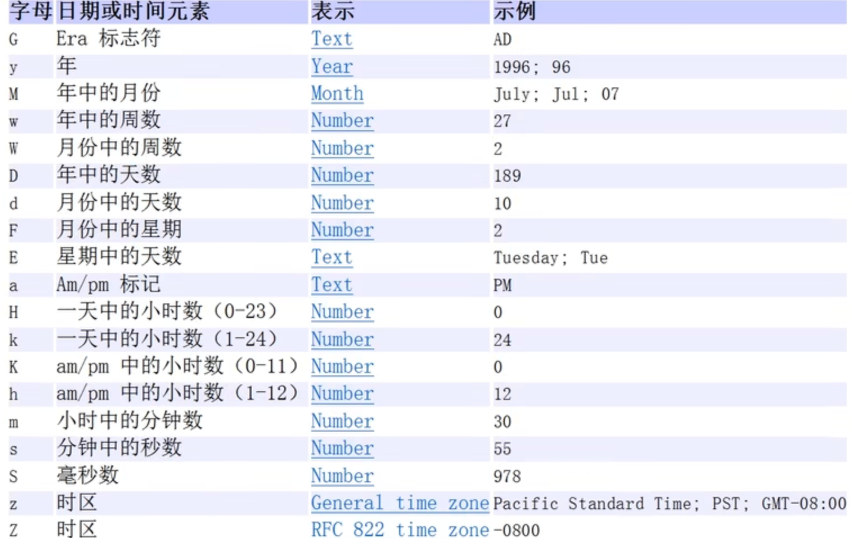
java
Date date = new Date();
// 返回时间戳(ms)
System.out.println(date.getTime());
System.out.println(System.currentTimeMillis());
// 格式化时间
SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH 时 mm分 ss秒 SSS毫秒 aKK E");
//设置时区
sdf.setTimeZone(TimeZone.getTimeZone("GMT"));
System.out.println(sdf.format(date));
// 解析时间
Date date1 = sdf.parse("2024年04月22日 00 时 28分 01秒 357毫秒 上午00 星期一");
System.out.println(date1);Calendar
第三代时间类
LocalDate
只有年月日
LocalTime
只有时分秒
LocalDateTime
- 既有年月日也有时分秒,最全面
java
LocalDateTime ldt = LocalDateTime.now(ZoneId.of("GMT"));
System.out.println(ldt.getDayOfMonth());
System.out.println(ldt.getDayOfWeek());
// 英文的月份 APRIL
System.out.println(ldt.getMonth());
// 数字的月份 4
System.out.println(ldt.getMonthValue());
// 设置年份
LocalDateTime ldt1 = ldt.withYear(2022);
System.out.println(ldt);
System.out.println(ldt1);
// Date.from()
// 格式化时间
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
System.out.println(dtf.format(ldt));
// 转为LocalDate 对象判断是否是闰年
System.out.println(ldt.toLocalDate().isLeapYear());
System.out.println(ldt1.toLocalDate().isLeapYear());
// LocalDateTime转为Instant Z 为UTC时间,-8 为亚洲/上海的时间
Instant instant = ldt.toInstant(ZoneOffset.of("-8"));
System.out.println(instant);
//Date 和Instant 相互转化
Instant instant1 = Instant.now();
Date date = Date.from(instant1);
Instant instant2 = date.toInstant();
System.out.println(instant2);集合
Collection
创建只读集合
Array.asList ,List.of,Set.of,Map.of,Map.ofEntries方法可以创建只读的集合
List
ArrayList(非线程安全)
ArrayList 基本等同与Vector ,ArrayList是线程不安全的,Vector是线程安全的,在多线程情况下使用Vector
源码解读
ArrayList 底层使用的是数组实现的,使用了一个名为elementData的数组存放数据, new ArrayList的时候可以传入一个数字,指定存放数组的大小,若没有指定,初始容量为0,然后添加元素之后会默认扩容为10。
使用add方法的时候,若当前容量不够,则会进行扩容,每次扩容为当前容量的1.5倍,使用的是Arrays.copyOf(oldArr,newLength);
remove 的源码,一开始判断索引是否正确,然后将要删除的元素的后面的元素都往前挪,然后size--,将后面空出来的那个元素赋值为null
Vector(线程安全)
- 源码解读
- Vector 底层使用的是数组实现的,使用了一个名为elementData的数组存放数据, 其构造器可以穿入初始的数组容量,还可以穿入一个扩容因子(容量不够时扩容多少长度),没有传入初始容量,则一开始为0,第一次扩容的时候默认扩容到10 ,没有传入扩容因子这个参数时,默认扩容为原来的两倍,如果传了这个参数,则根据这个参数的大小进行扩容
LinkedList(非线程安全)
源码解读
LinkedList底层使用的是双向链表 + 头尾指针 实现 ,具有类似双端队列的功能,可以在头部尾部插入和删除元素
add元素时,默认是在尾部插入,使用尾插法进行增加元素,可以指定在某个位置add元素,先找到元素的位置,使用双向链表的插入结点的方式插入结点即可
对于LinkedList来说,其增删改查的操作都是基于双向链表进行实现的
和ArrayList一样,LinkedList也是线程不安全的
Set
- 无序,元素不可重复
HashSet(非线程安全)
- Hashset 底层使用的是HashMap , K就是HashSet 的元素,value 有一个默认值
LinkedHashSet (非线程安全)
- 继承自HashSet,底层使用的是LinkedHashMap , K就是LinkedHashSet 的元素,value 有一个默认值
TreeSet (非线程安全)
Map
HashMap(非线程安全)
- jdk1.8之后底层 使用的是数组+单链表+红黑树的结构 ,jdk1.8之前使用的是数组+链表的结构实现的
- HashMap的迭代元素的顺序是不确定的
- HashMap使用的是拉链法的方式解决冲突,就是将数组与链表进行结合,数组的每一个元素都是一个链表,有相同的hash的元素会放在同一个链表上
- 相比于jdk1.8之前的版本,当链表长度>= 8时, 会调用
treeifybin()方法,这个方法会先判断HashMap中table数组的长度来决定是否转成红黑树,只有当数组长度>= 64时 ,才会将链表转为红黑树,以减少搜索的时间,否则,就只是执行resize()方法对table数组进行扩容。 - HashMap 中table 数组的扩容: HashMap 有一个
loadFactor(负载因子)的属性,默认值为0.75,还有一个名为table的数组用于存储元素,默认大小为16,其大小总是2的整数次幂。capacity 和 loadFactor可以在构造函数中传入,但是传入的capacity并不等于真正的table数组的容量大小,它会进行处理,保证table的长度为2的整数次幂。当HashMap的大小size > capacity * loadFactor 时,会对table数组进行扩容,扩容为原来的两倍。
add方法
先 i = (n - 1) & hash 得到该元素应该存放的索引位置(n-1是因为数组的长度为n,但是数组的索引为0 —— n-1),如果这个位置上没有一个元素,则直接将新元素存放到链表的开头,若有元素,则先判断第一个元素与新加入的元素是否相同, 若相同,则不添加,不相同则判断是树形结构还是链表结构。若为链表结构,则遍历这个链表,只有新旧元素的hash相同 && (key 相同或者 key.equals() 的值相等)就判断为同一个元素,则不会添加进去,若遍历完链表之后没有一个相同的元素,则将新元素添加到链表的末尾。若为树形结构,则遍历红黑树,看是否有相同的元素,若没有,则将新元素插入到红黑树中
javap.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))
LinkedHashMap
- 继承自HashMap ,和HashMap相比,存储的结点类型换成了Entry 而不是Node ,Entry 类继承自Node,多了一个before 和 after 指针 可以指向前驱和 后继结点,(所以 LinkedHashMap 的结点之间实现了一个双向链表),可以按顺序遍历LinkedHashMap ,相比HashMap来说,其遍历的效率会更高,因为要维护一个双向链表,故其插入删除操作性能会更低
- 对于put和get方法, 他会将最新访问的结点放到双向链表的末尾
HashTable(线程安全)
HashTable是线程安全的,线程安全也意味着其性能相比HashMap来说差很多,Java提供了更高效且更强大的线程安全哈希表,例如ConcurrentHashMap。ConcurrentHashMap使用了分段锁等高级技术,在高并发环境下表现更出色,因此在实际开发中,ConcurrentHashMap通常被优先选择,因此不推荐使用HashTable
hashTable 的Key 和Value均不能为null,否则会抛出NullpointerException
hashTable 是线程安全的,hashMap是非线程安全的
源码解析
HashTable采用数组加链表的方式存储数据 ,HashMap是数组+链表+红黑树的方式
默认是初始容量为11,加载因子为0.75,达到threshold 时进行扩容,扩容为原来的两倍+1
javaint newCapacity = (oldCapacity << 1) + 1;创建时如果给定了容量初始值,那么Hashtable会直接使用你给定的大小,而HashMap会将其扩充为2的幂次方大小
判断新元素和旧的元素是否为同一个结点
java// 得到key的哈希值 int hash = key.hashCode(); // 得到该key存在到数组中的下标 int index = (hash & 0x7FFFFFFF) % tab.length; //HashMap中是 int index = hash & (tab.length-1) //判断是否为同一个元素 (entry.hash == hash) && entry.key.equals(key) //HashMap中是这样判断的 (entry.hash == hash) && (entry.key == key || entry.key.equals(key)) //这样会更严谨一些
ConcurrentHashMap
Properties
- Properties类继承了Hashtable, 并实现了Map接口,使用特点和Hashtable类似,key 和Value均不能为null,否则会抛出NullpointerException
- Properties 一般用于从xxx.properties文件中加载数组到Properties类对象,通常用于存储配置文件的K-V数据
java
Properties properties = new Properties();
properties.load(new FileReader("/Users/leftover/project/study_java/rc.properties"));
// 输出文件的内容
properties.list(System.out);
String user =properties.getProperty("user");
System.out.println(user);
properties.setProperty("pwd","1223");
properties.setProperty("user","张文超");
// 将内容写入,还可以添加注释
// 中文的内容使用unicode编码
properties.store(new FileWriter("/Users/leftover/project/study_java/rc.properties"),"这是一条注释");TreeMap
TreeMap的key 不能为null, value可以为null,key为null会抛出NullpointerException
EnumMap
因为HashMap是一种通过对key计算hashCode(),通过空间换时间的方式,直接定位到value所在的内部数组的索引,因此,查找效率非常高。
如果作为key的对象是enum类型,那么,还可以使用Java集合库提供的一种EnumMap,它在内部以一个非常紧凑的数组存储value,并且根据enum类型的key直接定位到内部数组的索引,并不需要计算hashCode(),不但效率最高,而且没有额外的空间浪费。
java
public class enumMap {
public static void main(String[] args) {
EnumMap<Week, String> enumMap = new EnumMap(Week.class);
enumMap.put(Week.MONDAY, "星期一");
enumMap.put(Week.TUE, "星期二");
enumMap.put(Week.WED, "星期三");
enumMap.put(Week.THR, "星期四");
enumMap.put(Week.FRI, "星期五");
Set<Map.Entry<Week, String>> entrySet = enumMap.entrySet();
for (Map.Entry<Week, String> entry : entrySet) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
}
enum Week {
MONDAY, TUE, WED, THR, FRI, SAT, SUN
}反射
- 反射的基本使用
java
Properties properties = new Properties();
String basePath = System.getProperty("user.dir");
String filePath = basePath + File.separator + "src" + File.separator + "refection" + File.separator + "rc.properties";
properties.load(new FileInputStream(filePath));
// 得到一个Class的对象
Class cls = Class.forName(properties.getProperty("classFullPath"));
// new 对象一个实例
Object o = cls.newInstance();
// 根据方法名得到一个Method对象
Method methodName = cls.getMethod(properties.getProperty("method"));
// 调用o对象的方法
methodName.invoke(o);
// 根据属性名得到一个Field对象
Field fieldName = cls.getField("sal");
// 调用get方法,得到 o对象的某个属性(会自行装箱为引用数据类型)(私有属性无法得到)
Object field = fieldName.get(o);
System.out.println(field);
Constructor constructor = cls.getConstructor(); // 得到一个无参构造器
Constructor constructor1 = cls.getConstructor(String.class, int.class); //得到一个参数的构造器,要指定参数的类型- setAccessible(boolean flag)方法用于启动和禁用安全检查,true为禁用,flase为启动(禁用了安全检查则不会进行访问权限的检查,可以提高反射的性能,可以获取私有属性和私有方法,需要注意安全⚠️)
类的静态加载与动态加载
- 静态加载:是编译时加载相关类,如果没有这个类,则会报错
- 动态加载:运行时加载相关的类,如果运行时不用该类,则不报错,若运行时用到了这个类,且该类不存在,则报错
- 类加载的时机:
- new 关键字创建对象时(静态加载)
- 子类被加载时(静态加载)
- 调用类中的静态成员时(静态加载)
- 通过反射(动态加载)
Class类
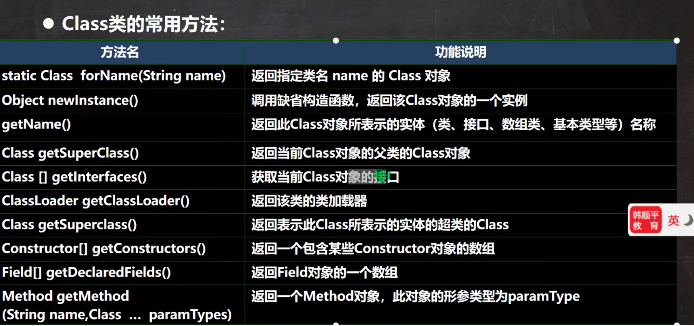
获取类对象
java// 1. 已知全类名的情况下,可以调用 Class.forName方法获取该类的Class对象,多用于配置文件,读取全类名,加载类 Class<?> class1 = Class.forName("refection.Cat"); // 2. 已知具体的类,通过class属性来获取,一般用于参数传递,比如通过反射得到构造器对象 Class class2 = Cat.class; class2.getConstructor(String.class, int.class); // 3. 已知某个类的实例,调用该实例的getClass方法获取Class对象 // 通过创建好的对象实例来获取Class对象 Cat cat = new Cat(); Class class3 = cat.getClass(); // 4.通过类加载器的方式获取Class对象(用的比较少) ClassLoader cl = cat.getClass().getClassLoader(); Class<?> class4 = cl.loadClass("refection.Cat"); // 获取基本数据类型的Class对象 (一般用于传递参数) // 1. Class class5 = int.class; // 2. Class class6 = Integer.TYPE;
Field对象
getField 方法只能获取自己和父类的public的属性
getDeclaredField方法可以获取本类的所有属性(访问私有属性需要调用setAccessible()方法禁用访问安全检查)
java
Field fieldName = cls.getField("sal");
Field fieldName1 = cls.getDeclaredField("age");反射的一些方法
- 以int类型返回修饰符时,默认修饰符为0,public 为1 ,private是2,protected是4,static是8,final是16,最后结果是相加得到
java
Class<?> class1 = Class.forName("refection.Cat");
System.out.println(class1.getName()); //全类名
System.out.println(class1.getSimpleName()); //简单类名
// 获取所有public修饰的属性(包括本类和父类)
Field[] fields = class1.getFields();
for (Field field : fields) {
System.out.println("本类和父类的public属性:" + field.getName());
}
System.out.println("===========");
// 获取本类的所有属性
Field[] fields1 = class1.getDeclaredFields();
for (Field field : fields1) {
System.out.println("本类的所有属性:" + field.getName());
}
// 获取本类和父类的public方法
Method[] methods = class1.getMethods();
for (Method method : methods) {
// 获取方法参数类型
Class<?>[] parameterTypes = method.getParameterTypes();
// 获取方法的返回类型
Class<?> returnType = method.getReturnType();
// 以int类型返回修饰符.默认修饰符为0,public 为1 ,private是2,protected是4,static是8,final是16
int modifiers = method.getModifiers();
// 方法名
String name = method.getName();
}
// 获取本类的所有方法
Method[] declaredMethods = class1.getDeclaredMethods();
// 返回本类所有的public的构造器对象
Constructor<?>[] constructors = class1.getConstructors();
// 返回本类所有的构造器对象
Constructor<?>[] declaredConstructors = class1.getDeclaredConstructors();
for (Constructor constructor : declaredConstructors) {
// 以class[]返回参数类型数组
Class[] parameterTypes = constructor.getParameterTypes();
for (Class cl :parameterTypes) {
System.out.println("Constructor的参数类型:" + cl);
}
}
// 以Package对象的形式返回包信息
System.out.println(class1.getPackage());
// 返回父类的Class对象
System.out.println(class1.getSuperclass());
// 返回所有的接口信息
Class<?>[] interfaces = class1.getInterfaces();
//返回所有的注解信息
Annotation[] annotations = class1.getAnnotations();动态代理
在程序运行阶段,在内存中动态生成代理类,被称为动态代理,目的是为了减少代理类的数量,解决代码复用问题
在内存中动态生成类的技术,常见的包括:

⚠️由于CGLIB库底层是通过继承方式实现的,所以被代理的目标类不能为final
cglib的基本使用
javaEnhancer enhancer = new Enhancer(); // 设置父类 enhancer.setSuperclass(Target.class); // 设置回调 ,类似jdk中的InvocationHandler enhancer.setCallback(new MethodInterceptor() { /** * obj :目标对象 * method:目标方法对象 * args:方法参数 * proxy:CGlib方法代理对象 */ @Override public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable { System.out.println("hh"); // 调用父类的方法 Object returnValue = proxy.invokeSuper(obj, args); // 将结果返回 return returnValue; } }); // 创建代理对象 // 这一步做了两件事 // 1. 在内存中生成父类的子嘞,其实就是代理类的字节码 // 2. 创建代理对象 Target targetProxy = (Target) enhancer.create(); int sum = targetProxy.sum(100); System.out.println(sum); //hh \n 4950代理模式的应用场景:
- 在程序中,功能需要增强时
- 在程序中,目标需要被保护时
- 在程序中,对象A和对象B无法直接交互时
代理模式中的角色:
- 代理类
- 目标类
- 代理类和目标类的公共接口(抽象主题):客户端在使用代理类时就像在使用目标类一样,不被客户端所察觉,所以代理类和目标类要有共同的行为,也就是实现共同的接口
java
public class 动态代理 {
public static void main(String[] args) {
ClotheFactory nike = new NikeClotheFactory();
ClotheFactory proxyInstance = (ClotheFactory) DynamicProxy.getProxyInstance(nike);
proxyInstance.produceClothe();
}
}
//动态代理类
class DynamicProxy {
public static Object getProxyInstance(Object obj) {
DynamicProxyInvocationHandler handler = new DynamicProxyInvocationHandler();
handler.bind(obj);
//第一个参数的目标对象的类加载器,第二个参数是代理对象要代理的接口(一般是实现被代理对象的所有接口),调用目标对象的方法时,会进行的处理
return Proxy.newProxyInstance(obj.getClass().getClassLoader(), obj.getClass().getInterfaces(), handler);
}
}
class DynamicProxyInvocationHandler implements InvocationHandler {
private Object obj;
public void bind(Object obj) {
this.obj = obj;
}
//当我们通过代理类的对象调用方法时,就会自动调用如下的invoke方法
// 参数分别为 代理类对象(即Proxy对象),调用的方法对象,调用的方法的参数
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("一些准备工作");
// 调用原来被代理类的方法
Object returnValue = method.invoke(obj, args);
System.out.println("一些结束工作");
//这里需要将返回值返回回去,代理对象调用对应的方法时才能获取到返回值,否则获取不到返回值
return returnValue;
}
}泛型
泛型类
普通成员(属性、方法)可以使用类的泛型,但是
静态成员不能使用类的泛型(因为泛型类的类型,是在创建对象时确定的,而静态方法不需要创建对象就可以使用)使用泛型的数组,不能初始化(因为数组在new的时候不能确定T的类型,就无法确定数组应该开辟多大的空间)
泛型只能传入引用类型,不能传基本数据类型
如果没有传入对应的类型,则默认是Object
书写的时候我们往往会简写,后面的<>编译器可以自行推导出来
javaHashMap<String, Integer> map = new HashMap<>();
泛型接口
- 静态成员不能使用泛型,(接口中所有的属性都是静态属性,都不能使用泛型)
- 泛型接口的类型,在继承接口或者实现接口时确定
- 没有指定类型,则默认为Object
java
interface IA<T, R> {
void say(T name, R age);
default T eat(T name, R age) {
return name;
}
}
class B implements IA <String,Integer> {
@Override
public void say(String name, Integer age) {
}
@Override
public String eat(String name, Integer age) {
return IA.super.eat(name, age);
}
}泛型方法
调用函数的时候会自动识别传入的参数的类型 来确认泛型最终的类型
java
//泛型方法
public <R> R printfCollections5(R r) {
System.out.println(r);
return r;
}泛型的继承和通配符
java
List <Object> list = new ArrayList<String> (); //不可以这样❌
// 支持T及其子类
public void printfCollections(List<? extends T> list) {
}
//只接收类型为T
public void printfCollections1(List<T> list) {
}
//支持 T及其父类
public void printfCollections2(List<? super T> list) {
}
//支持任意的泛型
public void printfCollections3(List<?> list) {
}IO操作
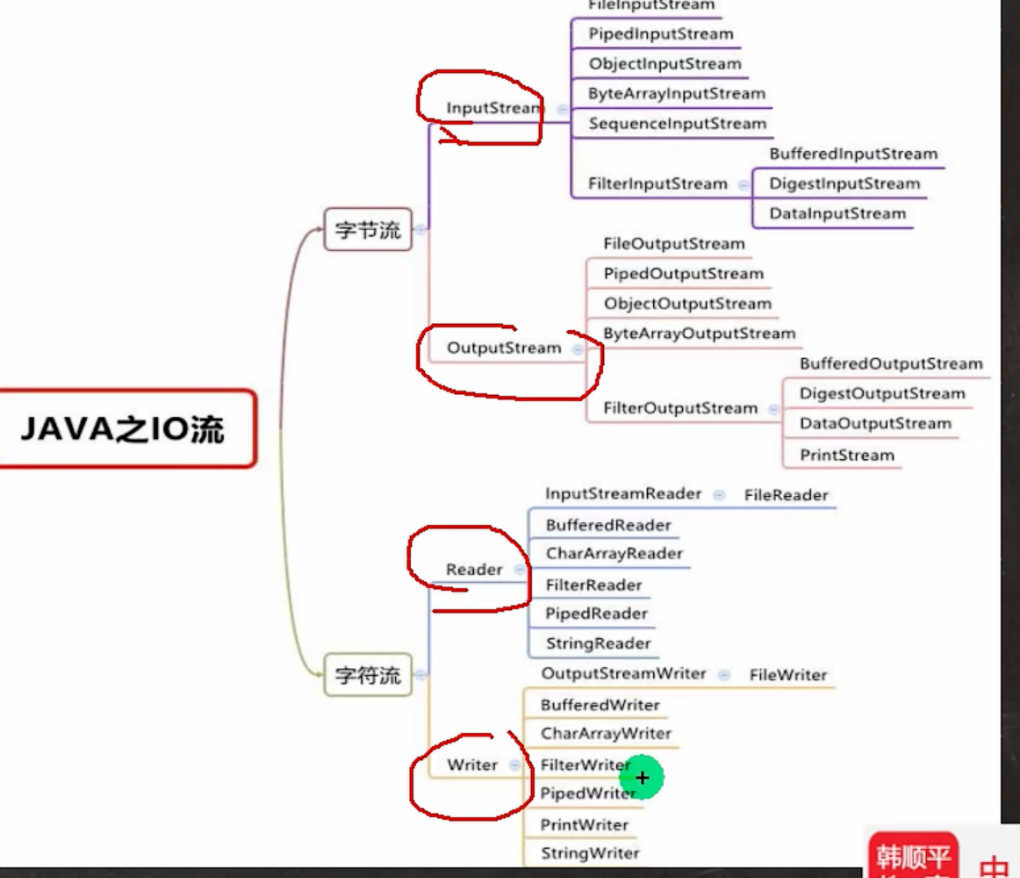
File对象
- 在Java中,目录也被当成是一种文件,也是使用File对象进行操作
java
File dir = new File("/Users/leftover/project/study_java/aa/bb");
//可以创建多级目录
dir.mkdirs();
//只能创建一级的目录
dir.mkdir();
File file = new File("/Users/leftover/project/study_java/new01.txt");
if (file.exists()) {
//删除文件或者目录
file.delete();
} else {
//创建文件
file.createNewFile();
}IO流
字符流:Reader和Writer,操作的数据单位为字符,适用于文本文件
字节流:InputStream和OutputStream,操作单位为字节,适用于二进制文件
字节流
FileInputStream
java
File file = new File("/Users/leftover/project/study_java", "aa.txt");
FileInputStream fileInputStream = new FileInputStream(file);
int c;
// 一个字节一个字节地读取
while ((c = fileInputStream.read()) != -1) {
System.out.print((char) c);
}
fileInputStream.close();
System.out.println();
System.out.println("===============");
//一次性最多读取8个字节到readContent数组中
FileInputStream fileInputStream1 = new FileInputStream(file);
byte[] readContent = new byte[8];
int readLength;
while ((readLength = fileInputStream1.read(readContent)) != -1) {
System.out.print(new String(readContent, 0, readLength));
}
fileInputStream1.close();FileOutputStream
java
File file = new File("/Users/leftover/project/study_java", "new01.txt");
//true 为在文件末尾追加
FileOutputStream fileOutputStream = new FileOutputStream(file, true);
// 写入单个字节
fileOutputStream.write('张');
// 写入一个字节数组
String name = "zwc,hello,张文超";
byte[] bytes = name.getBytes(StandardCharsets.UTF_8);
fileOutputStream.write(bytes);
fileOutputStream.close();transferTo方法
java
// 把输入流中的所有数据直接复制到输出流中
// 字符流中的transferTo方法是Java10 加入的
// 字节流中的transferTo是Java9加入的
byte[] data = {66, 67, 68, 55, 99, 78, 66, 77, 88, 99};
try (ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(data);
FileOutputStream fileOutputStream = new FileOutputStream("/Users/leftover/project/study_java/new03.txt");
) {
// 将输入流中的数据转化到输出流中,输出流中会自动调用write方法
byteArrayInputStream.transferTo(fileOutputStream);
} catch (IOException e) {
throw new RuntimeException(e);
}字符流
FileReader
java
File file = new File("/Users/leftover/project/study_java", "new01.txt");
FileReader fileReader = new FileReader(file);
FileReader fileReader1 = new FileReader(file);
int data = 0;
// 一个字符一个字符地读取
while ((data = fileReader.read()) != -1) {
System.out.print((char) data);
}
System.out.println();
System.out.println("===============");
// 使用字符数组一次读取多个字符
char[] buf = new char[10];
int readLength = 0;
while ((readLength = fileReader1.read(buf)) != -1) {
System.out.print(new String(buf, 0, readLength));
}
fileReader.close();
fileReader1.close();FileWirter
⚠️ FileWriter使用之后,必须调用close方法,或者刷新(flush),否则写入不到指定的文件
java
File file = new File("/Users/leftover/project/study_java", "note.txt");
file.createNewFile();
//true 表示以追加的方式写入
FileWriter fileWriter = new FileWriter(file, true);
String outputStr = "风雨之后,顶尖蔡工";
fileWriter.write(outputStr);
fileWriter.flush();
fileWriter.close();节点流

- 节点流可以从一个
特定的数据源读取数据,例如FileReader,FileWriter,FileInputStream,FileOutputStream,StringReader(处理字符串),CharArrayReader(处理数组)等等
处理流
- 处理流(也叫包装流),对节点流或者处理流进行了封装,连接在已存在的流(节点流或处理流)之上,为程序提供更为强大的读写功能,如BufferedReader,BufferedWriter等都是处理流
BufferedReader 和BufferedWriter
java
File file = new File("/Users/leftover/project/study_java", "new01.txt");
FileReader fileReader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String data = "";
// 若流结束,返回null
while ((data = bufferedReader.readLine()) != null) {
System.out.println(data);
}
bufferedReader.close();java
File file = new File("/Users/leftover/project/study_java", "note.txt");
FileWriter fileWriter = new FileWriter(file, true);
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
for (int i = 0; i < 3; i++) {
bufferedWriter.write("hajhgjahghakghkagh");
//写入一个系统的换行符
bufferedWriter.newLine();
}
bufferedWriter.close();BufferedInputStream 和BufferedOutputStream
java
File readImg = new File("/Users/leftover/project/study_java", "img1.png");
FileInputStream fileInputStream = new FileInputStream(readImg);
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
File writeImg = new File("/Users/leftover/project/study_java", "img02.png");
writeImg.createNewFile();
FileOutputStream fileOutputStream = new FileOutputStream(writeImg);
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(fileOutputStream);
byte[] data = new byte[88];
int readLength = 0;
while ((readLength = bufferedInputStream.read(data)) != -1) {
bufferedOutputStream.write(data, 0, readLength);
}
bufferedInputStream.close();
bufferedOutputStream.close();ObjectInputStream 和ObjectOutputStream
- ObjectOutputStream和 ObjectInputStream 是处理流,可以将数据及其数据结构保存到
xxx.dat文件中,并且可以读取xxx.dat文件,恢复数据和数据结构 - 序列化就是在保存数据时,保存数据的值和类型
- 反序列化时在恢复数据时,恢复数据的值和数据类型
- 要让某个对象可以序列化,需要实现
Serializable或者Externalizable接口,其里面的所有属性都要实现可序列化的接口,所有属性都会序列化,除了static和transient修饰的成员 - 读写的时候,顺序要一致,读写的数据类型也要一致,否则会报错
- 序列化的类中建议添加
private static final long serialVersionUID字段,当新的类对老版本的类不兼容时,可以修改这个值,这时候原来代码就反序列化不了了,若兼容,则可以不用修改这个值,以前的老的反序列化代码还是能继续用
转换流
- 默认的字符输入输出流是以utf-8的编码方法读取的,但如果我们需要以其他编码方式(例gbk)读取/写入文本,这时候普通的字符流就不行了,这时候需要使用到转换流
- 转换流可以指定编码方式
- 转换流的底层使用的是字节流操作的数据,但是我们是使用的是字符流的方式写编码(会更方便)
InputStreamReader
java
BufferedReader bufferedReader = new BufferedReader(
new InputStreamReader(
//指定编码方式
new FileInputStream("/Users/leftover/project/study_java/new02.txt"), Charset.forName("gbk")
));
String data = bufferedReader.readLine();
System.out.println(data);OutputStreamWriter
java
FileOutputStream fileOutputStream = new FileOutputStream("/Users/leftover/project/study_java/new02.txt");
//指定编码方式
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(fileOutputStream, Charset.forName("gbk"));
outputStreamWriter.write("gaghah,张文超");
outputStreamWriter.close();打印流
- 打印流只有输出流
PrintStream(字节打印流)
java
// System.out 获取的就是一个标准的打印流(默认输出到显示器)
// PrintStream 默认输出的位置为显示器
PrintStream out = System.out;
// 输出到显示器
out.print("zwc,张文超");
out.println();
out.write("hhjahj".getBytes());
// 重定向输出的设备,输出到文件
System.setOut(new PrintStream("/Users/leftover/project/study_java/new08.txt"));
PrintStream out1 = System.out;
out1.print("zwc");
out.close();
out1.close();PrintWriter(字符打印流)
java
// 写入到显示器
PrintWriter printWriter = new PrintWriter(System.out);
printWriter.print("张文超");
// 需要调用close方法或者flush方法才会将数据写入
printWriter.close(); // printWriter.flush();
// 写入到文件
PrintWriter printWriter1 = new PrintWriter(new FileWriter("/Users/leftover/project/study_java/new09.txt"));
printWriter1.print("zwc,张文超");
printWriter1.flush();
printWriter1.close();多线程
并发:同一时刻,多个任务交替执行,造成一种“貌似同时”的错觉,,单核cpu实现的多任务就是并发
并行:同一时刻,多个任务同时执行,多核cup可以实现并行
当我启动一个程序时,会启动一个进程,然后这个进程会立刻创建一个
main线程,之后根据你编写的多线程的代码由main线程创建多个线程(子线程也可以继续创建线程)要启动一个线程时,必须调用start方法,而不是run方法,因为run方法只是一个普通方法,此时如果调用run方法,执行这个方法的线程还是父线程(此时父线程会阻塞在这里),而不是新创建的子线程。start方法中会调用start0方法,会创建一个新的线程,由新的线程执行run方法。
创建线程的方法
实现一个线程类,可以通过继承Thread类,或者实现Runnable接口
javaT1 t1 = new T1(); Thread thread = new Thread(t1); thread.start();如果想要在线程执行完毕之后得到返回的结果,可以使用
Callable接口,FutureTask类来创建线程javapublic class 利用Callable接口创建任务对象 { public static void main(String[] args) throws ExecutionException, InterruptedException { //创建一个线程 Callable call = new MyCallable(200); FutureTask<Integer> futureTask = new FutureTask<Integer>(call); new Thread(futureTask).start(); //获取返回值 //这里的get方法会等待线程执行完毕之后再执行,因此不用担心获取不到返回值的问题 Integer sum = futureTask.get(); System.out.println(sum); } } class MyCallable implements Callable<Integer> { private int n; public MyCallable(int n) { this.n = n; } //求1-n的和 @Override public Integer call() throws Exception { int sum = 0; for (int i = 0; i <= n; i++) { sum += i; } return sum; } }常用的方法
javasetName //设置线程的优先级,有3个优先级,1,5(默认),10 setPriority getPriority getName start //静态方法 sleep // 中断一个被阻塞的线程,例如sleep ,wait等方法,然后会捕获一个InterruptedException(根据的block的情况而定) interrupt //线程的插队,即让某个子线程插队执行,只有这个子线程执行完毕之后才会执行父线程,其他的子线程不受影响,只有父线程会等这个子线程执行完毕之后才继续执行 join(); //静态方法。 在哪个线程中调用了这个方法,这个线程会进行礼让,让出cpu,让其他线程执行,⚠️但是礼让的时间不确定,也不一定会礼让成功(取决于cpu的负载情况) yield()
守护线程
setDaemon(true) 方法可以将某个线程设置为守护线程
用户线程:也叫工作线程,当线程的任务执行完毕或者通知方式结束
守护线程:一般是为工作线程服务的。(常见的守护进程:垃圾回收机制)
- 当所有的用户线程结束时,守护线程自动结束(无论该守护线程有没有执行完毕)
- 用户进程还没结束,当守护进程执行完毕了,守护进程也会结束
线程的生命周期
- ⚠️需要说明的是: Runnable状态也常常被划分为两个状态:Ready(准备运行)、Running(正在运行),所有也常说有7种状态,但是官方的文档中是6种状态
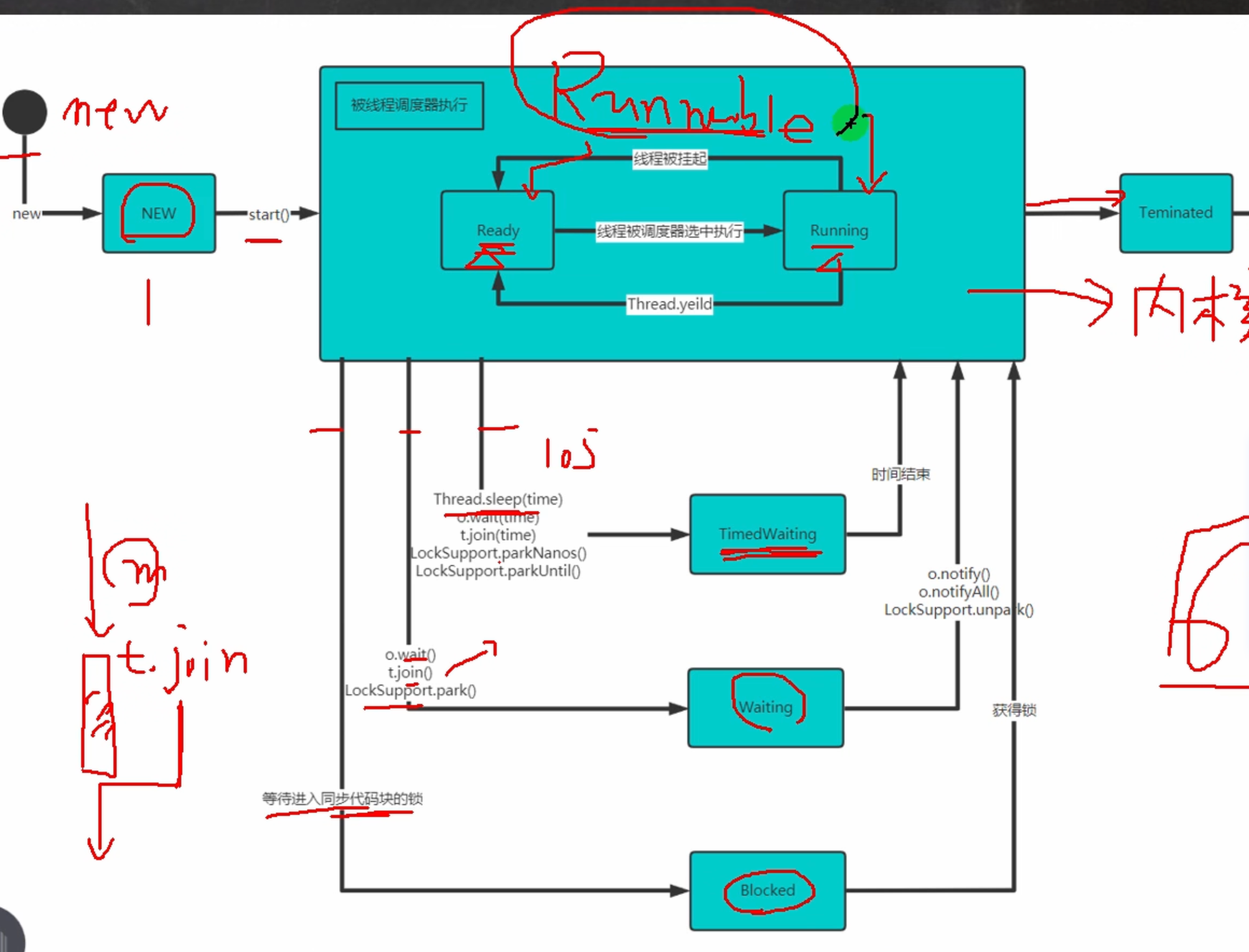
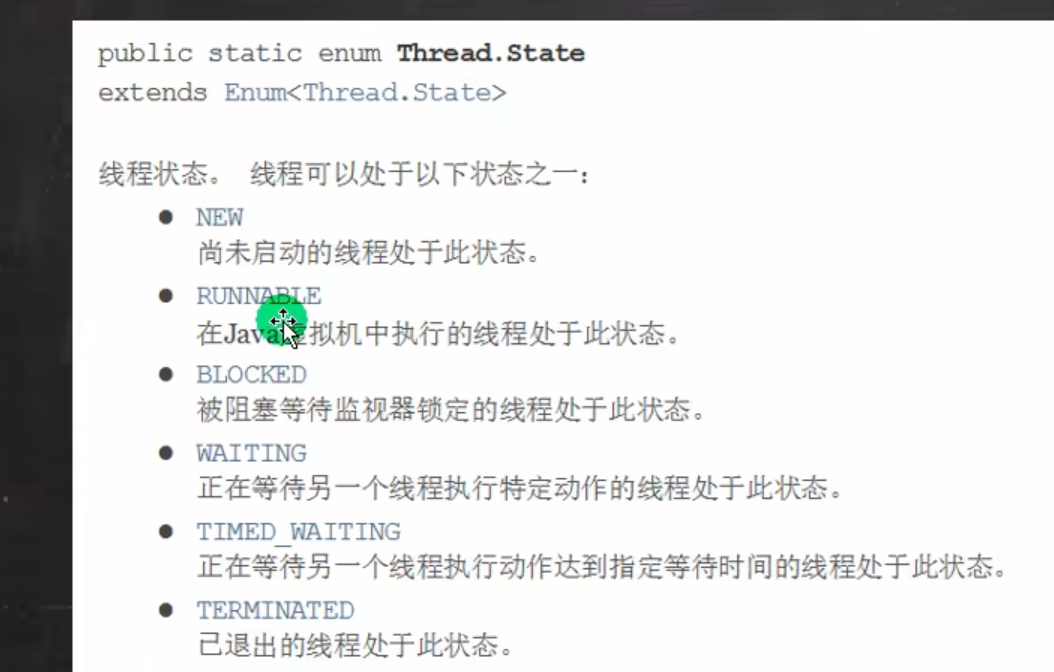
线程同步
同步的具体方法
- 同步代码块
javasynchronized (对象) { //这个对象要为同一个对象 }- 同步方法
javapublic synchronized void sell() { //此时整个方法会变成同步方法,且默认锁对象为this } public static synchronized void sell() { //若为static方法,此时整个方法会变成同步方法,此时的默认锁对象为当前类.class }lock锁实现进程同步
⚠️ 定义一个lock锁的成员变量,最好为final
把语句用try catch finally包裹起来,解锁的操作一定要放在finally块中,否则可能程序出现异常而无法解锁
javapublic class Lock锁 { public static void main(String[] args) { Account1 account1 = new Account1(); Thead1 thead1 = new Thead1(account1); Thead2 thead2 = new Thead2(account1); thead1.start(); thead2.start(); } } class Thead1 extends Thread { Account1 account1 = null; @Override public void run() { super.run(); while (account1.getMoney() > 0) { account1.subMoney(1); try { Thread.sleep(500); } catch (InterruptedException e) { throw new RuntimeException(e); } } } public Thead1(Account1 account1) { this.account1 = account1; } } class Thead2 extends Thread { Account1 account1 = null; @Override public void run() { super.run(); while (account1.getMoney() > 0) { account1.subMoney(1); try { Thread.sleep(500); } catch (InterruptedException e) { throw new RuntimeException(e); } } } public Thead2(Account1 account1) { this.account1 = account1; } } class Account1 { private int money = 50; //定义一个lock锁的成员变量,最好为final private final Lock lock = new ReentrantLock(); public int getMoney() { return money; } public int addMoney(int money) { //把语句用try catch finally包裹起来,解锁的操作一定要放在finally块中,否则可能程序出现异常而无法解锁 try { lock.lock(); this.money = money + this.money; } catch (Exception e) { e.printStackTrace(); } finally { //将解锁操作放在finally块中 lock.unlock(); return this.money; } } public int subMoney(int money) { try { lock.lock(); if (this.money >= money) { this.money = this.money - money; System.out.println(Thread.currentThread().getName() + "取走1块钱,还剩" + this.money); } } catch (Exception e) { e.printStackTrace(); } finally { lock.unlock(); } return this.money; } }互斥锁
每个对象都对应于一个可称为“互斥锁”的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象
关键字
synchronized来与对象的互斥锁联系。当某个对象用synchronized修饰时,表明该对象在任一时刻只能由一个线程访问同步的局限性:程序执行的效率会降低
同步方法如果没有使用static修饰:默认锁对象为
this如果使用了static修饰,默认锁对象:当前类.class
⚠️要实现线程之间的互斥访问:要求多个线程的锁对象为同一个(即对象的
地址要相等)!
释放锁的分析
会释放锁:
同步方法或者同步代码块执行完毕
同步代码块,同步方法中遇到break;return
同步方法、同步代码块出现了为处理的Error或者Exception,导致异常结束
当前线程在同步方法或者同步代码块中时,执行了线程对象的wait()方法,当前线程暂停,并释放锁
javasynchronized (obj) { while (<condition does not hold>) obj. wait(); ... // Perform action appropriate to condition }
不会释放锁
线程执行同步方法或者同步代码块时,程序调用了Thead.sleep(),Thead.yield(),方法暂停当前线程的执行
线程执行同步方法或者同步代码块时,其他线程调用了该线程的suspend()方法将该线程挂起,该线程不会释放锁
tips:应当尽量避免使用suspend和resume方法来控制线程(这两个方法已经被弃用了)
线程通信
wait,notify,notifyAll方法,必须由锁对象调用这个方法,否则会出现问题具体代码查看多线程-线程通信_实现生产者和消费者问题

线程池
创建线程池

java
ExecutorService pool = new ThreadPoolExecutor(
3, //线程池核心线程的数量
5,//线程池最大的线程的数量(临时线程数=最大线程数-核心线程数) ,必须>=线程池核心线程的数量
100, //指定临时线程存活的时间
TimeUnit.SECONDS, //指定临时线程存活的时间单位(秒,分,时,天)
new ArrayBlockingQueue<>(5), //指定线程池的任务队列
Executors.defaultThreadFactory(), //指定线程池的线程工厂,用于创建线程(左边的参数是默认的线程工厂)
new ThreadPoolExecutor.AbortPolicy() // 指定线程池的任务拒绝策略(线程都在忙,且任务队列已满,新任务来的时候的处理策略)(左边传入的是默认的一个处理策略)
);⚠️ notice
临时线程的创建时机 ?
新任务提交时发现核心线程都在忙,且任务队列已满,此时还可以创建临时线程,就会创建临时线程
什么时候会开始拒绝新任务?
核心线程和临时线程都在忙(创建不了线程了),任务队列已满,新任务过来的时候才会开始拒绝任务
常见的任务拒绝策略
使用Executors工具类创建线程池(尽量不要使用这种方法创建线程池,不容易控制资源的大小,容易出现安全隐患)

线程池执行任务
execute():执行Runnable任务
Future <T> submit(Callable <T> task):执行Callable任务,返回未来任务对象,用于获取线程返回的结果
showdown() :等待全部任务执行完毕之后,再关闭线程池
showdownNow():立刻关闭线程池,停止正在执行的任务,并返回队列中未执行的任务(用的少)
悲观锁和乐观锁
悲观锁
上面
lock锁和synchronized实现的进程同步都称为悲观锁,即每次只有一个进程执行同步代码,只有等锁释放了之后其他线程才能抢锁,再执行同步代码。这种锁效率比较低悲观锁的实现方式是加锁,加锁既可以是对代码块加锁(如Java的synchronized关键字),也可以是对数据加锁(如MySQL中的排它锁)。
悲观锁:悲观锁在操作数据时比较悲观,认为别人会同时修改数据。因此操作数据时直接把数据锁住,直到操作完成后才会释放锁;上锁期间其他人不能修改数据。
乐观锁
乐观锁的实现方式主要有两种:CAS机制和版本号机制。
乐观锁:乐观锁在操作数据时非常乐观,认为别人不会同时修改数据。因此乐观锁不会上锁,只是在执行更新的时候判断一下在此期间别人是否修改了数据:如果别人修改了数据则放弃本次操作,取最新的数据再执行操作,若此期间别人没有修改数据,则执行操作。
java8 新特性
lamdba表达式和方法引用
Lambda 表达式用于函数式接口(只有一个抽象方法的接口)
本质上是函数式接口的实例
javaRunnable r = () -> System.out.println("哈哈哈哈")方法引用本质上是Lambda表达式的一种语法糖,本质上也是lambda表达式,是一种更简洁的写法,but可读性更差
当传递给lambda体的操作已经有实现的方法了,可以使用方法引用
使用格式:类(或对象):: 方法名 (分以下三种情况)
对象:: 非静态方法
类::静态方法
类:: 非静态方法(有点特殊),例如下面,第一个参数作为调用者时,调用的函数传入第二个参数或者没有参数,此时也可以使用方法引用
方法引用的使用要求:要求接口中的
抽象方法的形参列表和返回值类型与方法引用的方法的形参列表和返回值类型相同
java
DoublePredicate doublePredicate = new DoublePredicate() {
@Override
public boolean test(double value) {
return value > 66;
}
};
System.out.println(doublePredicate.test(88.2));
// 正常使用方法引用
//一般静态方法就使用类::静态方法 ,非静态方法就用 对象::非静态方法
Compare compare = new Compare();
DoublePredicate doublePredicate1 = compare::compare;
System.out.println(doublePredicate1.test(88.2));
// 第三种使用方法引用的方法 类::非静态方法
BiPredicate<String, String> biPredicate = new BiPredicate<String, String>() {
@Override
public boolean test(String s, String s2) {
//第一个参数作为调用者
return s.equals(s2);
}
};
//方法引用
BiPredicate<String, String> biPredicate1 = String::equals;构造器引用和数组引用
java
// lambda表达式
Function<Integer, String[]> function = (length) -> new String[length]; //返回了一个长度为length的数组
// 对应的数组引用
Function<Integer, String[]> function1 = String[]::new;
Supplier<String> supplier = new Supplier<String>() {
@Override
public String get() {
// 返回一个对象
return new String("即啊会发觉哈"); // 返回了一个String对象
}
};
// 对应的构造器引用
Supplier<String> supplier1 = String::new;Stream API
- Stream api提供了一种高效且易于使用的处理数据的方式(一般用于处理集合和数组的数据)
- Stream操作的三个步骤
- 创建Stream
- 中间操作
- 终止操作
- Stream操作是延迟执行的,
只有等到执行了终止操作时,才会执行中间操作,得到结果
创建Stream
java
// 第一种: 通过集合创建Stream
List<Integer> list = new ArrayList<>();
// 返回一个顺序流
Stream<Integer> stream = list.stream();
// 返回一个并行流
Stream<Integer> parallelStream = list.parallelStream();
// 第二种: 通过Arrays.stream() 创建一个集合
String[] arr = {"132", "访华", "ajkajfkj"};
Stream<String> stringStream = Arrays.stream(arr);
int[] arr1 = {1, 2, 3};
IntStream stream1 = Arrays.stream(arr1);
// 第三种:Stream.of()传入一系列可变参数当作数据源来创建一个流
Stream<Integer> integerStream = Stream.of(1, 23, 4, 6, 9);
//第四种:创建无限流,这种方式一般是自己创建一些数据的时候使用
// 使用生成的方式生成数据源
Stream<Double> doubleStream = Stream.generate(() -> Math.random());
// 使用迭代的方式生成数据源
Stream<Integer> iterateStream = Stream.iterate(2, i -> i * 2);
Stream.iterate(2, i -> i * 2).limit(10).forEach(System.out::println);stream api的中间操作-筛选
java
Integer[] arr = {1, 2, 5, 3, 999, 555, 6, 3, 1, 6};
List<Integer> list = Arrays.asList(arr);
//limit 截断流,使其元素不超过指定数量
//filter 筛选,从流中筛选出指定条件的元素
list.stream().limit(6).filter((i) -> i > 5).forEach(System.out::println);
System.out.println("===========");
// 跳过前n个元素,若元素数量 <= n ,则全部跳过
list.stream().skip(3).forEach(System.out::println);
List<User> userList = new ArrayList<>();
userList.add(new User("zwc", 18));
userList.add(new User("zwc", 18));
userList.add(new User("zwc", 18));
userList.add(new User("zwc", 18));
userList.add(new User("zwc", 18));
System.out.println(list);
System.out.println("===========");
// distinct 去重,通过equals方法 对比两个元素是否相等(和hashCode方法没关系)
userList.stream().distinct().forEach(System.out::println);stream api的中间操作-映射
forEachOrdered 和forEach 的对比: forEachOrdered 可以保证在并行流的时候也按顺序取元素,而forEach在并行流的时候不会按顺序取元素
map,flatMap,mapToInt等
java
List<String> list = new ArrayList<>();
list.add("jfa");
list.add("ruuio");
list.add("agdgagf");
List<String> list2 = new ArrayList<>();
list.add("jfa133");
list.add("23u21");
list.add("发反季节啊");
// map的用法 ,接收一个函数,该函数会应用到每个元素上将其映射为一个新的元素
list.stream().map(s -> s.toUpperCase()).forEach(System.out::println);
System.out.println("=======");
// forEachOrdered 和forEach 的对比
// forEachOrdered 可以保证在并行流的时候也按顺序取元素
list.parallelStream().map(s -> s.toUpperCase()).forEach(System.out::println);
System.out.println("=======");
list.parallelStream().map(s -> s.toUpperCase()).forEachOrdered(System.out::println);
// mapToInt 返回的流是一个IntStream
System.out.println("=======");
list.stream().mapToInt(s -> s.length()).forEach(System.out::println);
// flatMap 接收一个函数作为参数,这个函数会将流中的每一个值都换成另一个流,最后将所有的流连接在一起形成一个流
// 类似扁平化的效果
List<List<String>> lists = new ArrayList<>();
lists.add(list);
lists.add(list2);
System.out.println("=======");
lists.stream().flatMap(l ->l.stream()).forEach(System.out::println);stream api的中间操作排序
java
List<User> userList = new ArrayList<>();
userList.add(new User("zwc",1));
userList.add(new User("zwc2",23));
userList.add(new User("zwc222",11));
userList.add(new User("zwc11",2323));
// 按年龄排序
userList.stream().sorted((user1, user2) -> Integer.compare(user1.getAge(), user2.getAge())).forEach(System.out::println);stream api的终止操作——收集
java
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(123);
list.add(111);
list.add(12323);
//collect 收集,将流中的元素收集起来
List<Integer> integerList = list.stream().filter(num -> num > 100).collect(Collectors.toList());
Set<Integer> integerList1 = list.stream().filter(num -> num > 100).collect(Collectors.toSet());
integerList.forEach(System.out::println);
System.out.println("=====");
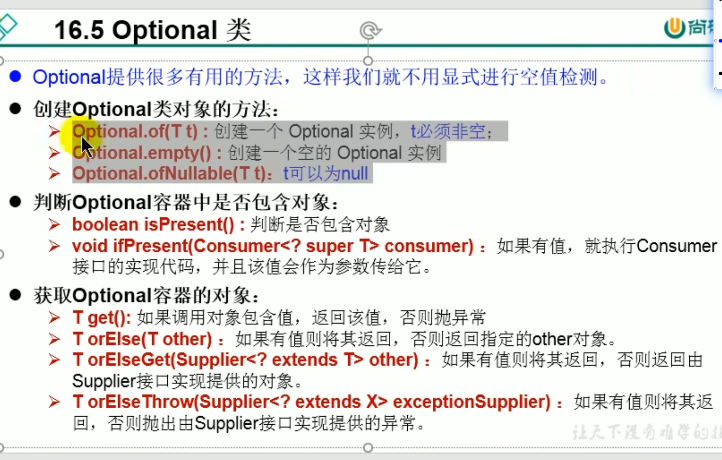
integerList1.forEach(System.out::println);Optional类
Optional类是一个容器类,主要用于避免空指针异常的问题,并且Optional类也可以进行链式调用,写起来很简洁
javapublic class Optional类 { public static void main(String[] args) { // printfName1(null); printfName2(null); } // 不使用Optional 类的写法 public static void printfName1(Boy boy) { // 这里我们不确定传进来的是否是null ,正常情况下应该写判断逻辑 if (boy == null) { System.out.println("无此人"); } else { System.out.println(boy.getName()); } } // 使用Optional类的写法 public static void printfName2(Boy boy) { Person1 person = new Person1(boy); //很简洁 String s = Optional.ofNullable(person).map(person1 -> person1.getBoy()).map(boy3 -> boy3.getName()).orElse("默认"); System.out.println(s); } } class Boy { private String name; private int age; public Boy(String name, int age) { this.age = age; this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } } class Person1 { private Boy boy; public Person1(Boy boy) { this.boy = boy; } public Boy getBoy() { return boy; } public void setBoy(Boy boy) { this.boy = boy; } }Optional类的主要的方法
JDBC
连接数据库
java
Properties properties = new Properties();
String workDir = System.getProperty("user.dir");
String fullPath = workDir + "/db.properties";
properties.load(new FileReader(fullPath));
// Driver类中有一个静态代码块,会自动注册Driver,可以不用调用DriverManager.registerDriver(drive)来注册Drive
Class<?> aClass = Class.forName("com.mysql.cj.jdbc.Driver");//这一行其实也可以不用写,这个类会自动加载
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/study_java", properties);
System.out.println(connection);
connection.close();jar包里面配置了对应的类,我们启动的时候会自动加载com.mysql.cj.jdbc.Driver这个类,但是还是建议写一下,手动加载
Driver类中有一个静态代码块,会自动注册Driver,可以不用调用DriverManager.registerDriver(drive)来注册Drive
PrepareStatement防止sql注入
在使用PreparedStatement对象执行SQL语句时,sql语句会被数据库编译与解析,并放到命令缓冲区。然后,每当执行同一个PreparedStatement对象时,由于在缓冲区中可以发现预编译的命令,虽然它会被再解析一次,但不会被再次编译,是可以重复使用的 ;但是 Statement每次执行一条语句都要编译,因此在批处理的时候Statement会比PreparedStatement效率低很多
PreparedStatement 可以有效防止sql注入的问题
使用PreparedStatement,代码可读性和可维护性更好
java
Connection connection = Mysql.getMysqlConnection();
//需要传值的位置设置? ,然后通过set api设置值,这样可以防止sql注入
String sql = "select * from User where id=? and name =?";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
// PreparedStatement可以 防止sql注入
// 通过set的api可以有效防止sql注入
preparedStatement.setString(1, "'1' or '");
preparedStatement.setString(2, "'or '1'='1'");
// preparedStatement.executeQuery() 不需要传入sql,如果这里传入sql起不到防止sql注入的效果
ResultSet resultSet = preparedStatement.executeQuery();
if (resultSet.next()) {
System.out.println("登陆成功");
} else {
System.out.println("登陆失败");
}CallableStatement
执行事务
JDBC中的sql语句是默认提交,即当sql执行成功时,就会提交到mysql中,提交之后就不可以撤回了
connection.setAutoCommit(false);关闭自动提交
java
Connection connection = null;
PreparedStatement preparedStatement1 = null;
PreparedStatement preparedStatement2 = null;
try {
connection = Mysql.getMysqlConnection();
// 关闭自动提交
connection.setAutoCommit(false);
String sql1 = "update account set balance =balance-100";
preparedStatement1 = connection.prepareStatement(sql1);
preparedStatement1.executeUpdate();
int a = 1 / 0;
String sql2 = "update account set balance =balance+100";
preparedStatement2 = connection.prepareStatement(sql2);
preparedStatement2.executeUpdate();
// 手动提交
connection.commit();
} catch (Exception e) {
//出错了,没执行完,手动回滚
connection.rollback();
e.printStackTrace();
} finally {
preparedStatement1.close();
preparedStatement2.close();
connection.close();
}批处理执行sql
⚠️:想要批处理执行sql,需要修改连接数据库的url,在后面加上rewriteBatchedStatements=true
如jdbc:mysql://localhost:3306/study_java?rewriteBatchedStatements=true
java
Connection connection = Mysql.getMysqlConnection();
String sql = "insert into batch values (null,?,?)";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
for (int i = 1; i <= 5000; i++) {
preparedStatement.setString(1, "zwc" + i);
preparedStatement.setInt(2, i);
// 将sql添加到批处理队列中
preparedStatement.addBatch();
if (i % 1000 == 0) {
// 满1000条, 执行批处理队列中的sql
preparedStatement.executeBatch();
// 将批处理队列清空
preparedStatement.clearBatch();
}
}
preparedStatement.close();
connection.close();数据库连接池
c3p0连接池
java
// 这里填的是连接池的名称,需要跟配置文件中的一致
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource("myDbResource");
Connection connection = comboPooledDataSource.getConnection();
System.out.println("连接成功");
connection.close();配置文件名称c3p0-config.xml
xml
<?xml version="1.0" encoding="UTF-8" ?>
<c3p0-config>
<!-- 命名的数据源配置 -->
<named-config name="myDbResource">
<property name="driverClass">com.mysql.cj.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/study_java</property>
<property name="user">root</property>
<property name="password">zwc666666</property>
</named-config>
</c3p0-config>德鲁伊连接池
java
Properties properties = new Properties();
String workDir = System.getProperty("user.dir");
String fullPath = workDir + "/src/druid.properties";
properties.load(new FileReader(fullPath));
//得到连接
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
Connection connection = dataSource.getConnection();
System.out.println("连接成功");
//
connection.close();dbutils(工具库)
⚠️:实体类一定要有无参构造器,供反射使用,属性名要和数据库名称一致

java
Properties properties = new Properties();
String workDir = System.getProperty("user.dir");
String fullPath = workDir + "/src/druid.properties";
properties.load(new FileReader(fullPath));
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
// Connection connection = dataSource.getConnection();
// 将dataSource 传入,可以不需要获取连接了 ,内部也会自动帮你close连接
QueryRunner queryRunner = new QueryRunner(dataSource);
// 查询多行 BeanListHandler
String sql = "select * from User where id > ?";
List<User> userList = queryRunner.query(sql, new BeanListHandler<>(User.class), 2);
for (User user : userList) {
System.out.println(user);
}
System.out.println("=======");
// 查询单行 BeanHandler
String sql1 = "select * from User where id =?";
User user = queryRunner.query(sql1, new BeanHandler<>(User.class), 5);
System.out.println(user);
System.out.println("==========");
// 查询单行单列 ScalarHandler
String sql2 = "select name from User where id =?";
String name = queryRunner.query(sql2, new ScalarHandler<String>(), 3);
System.out.println(name);
System.out.println("======");
// 实现更新,删除,修改等等
String sql3 = "update User set age = ? where id = ?";
//返回的是受影响的行数
int affectRow = queryRunner.update(sql3, 100, 6);
System.out.println(affectRow == 0 ? "没有任何行受影响" : "有" + affectRow + "行受影响");
public class User {
private int id;
private String name;
private int age;
private String hobby;
// ⚠️ 这个是实体类,必须要有一个无参的构造函数,供反射使用
public User() {
}
public User(int id, String name, int age, String hobby) {
this.id = id;
this.name = name;
this.age = age;
this.hobby = hobby;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getHobby() {
return hobby;
}
public void setHobby(String hobby) {
this.hobby = hobby;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
", hobby='" + hobby + '\'' +
'}';
}
}DAO
DAO: data access object (数据访问对象)
文章作者:leftover
版权声明: 所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 leftover!