本站总访问量次
Redis 安装
作者:leftover
字数统计:18.1k 字
阅读时长:92 分钟
Mac 上下载 redis
shell
brew install redis配置文件位于/opt/homebrew/etc/redis.conf
Redis 可视化管理工具
Redis-Insight redis 官方的可视化工具
medis2 Mac 上美观度 Redis 可视化管理工具
Redis 学习资源
官方文档(英文,推荐)
Redis 中文文档(非官方,推荐)
Redis 中文的手册(非官方,一般般)
Redis 数据结构及其 命令
key 的层级结构
Redis 的 key 允许多个单词形成层级结构,以: 隔开,可以通过项目名:业务名:类型:id的方式命名(非强制性)
例如:leftover:cms:user:999 ,leftover.backend:user:999
常用通用命令
- KEYS: 查看符合条件的所有 key(⚠️不建议在生产环境使用,当 key 很多的时候,消耗的时间多,且 redis 是单线程的,会阻塞 redis 的其他操作)
- DEL: 删除一个指定的 Key
- EXISTS:判断 key 是否存在
- EXPIRE: 给 key 设置有效期,有效期到期时该 key 会被自动删除
- TTL:查看一个 key 的有效时间(单位
s,key 不存在返回-2,key 存在但是没有设置超时时间返回-1) - PTTL: 和 TTL 一样(返回的时间单位
ms) - RENAME: 重命名一个 key,若 newKey 存在,则会覆盖原来的 key
- RENAMENX: 重命名一个 key,仅当 newkey 不存在时,将 key 改名为 newkey
- TYPE:返回
key的类型,key不存在时返回none。(可返回的类型string,list,set,zset,hashandstream) - MOVE: 将某个 key 移动到其他数据库(如果
key在目标数据库中已存在,或者key在源数据库中不存,则key不会被移动。) - PERSIST:移除 key 的过期时间,key 将持久保持
文档:https://redis.io/docs/latest/commands/?group=generic
string 类型
string 类型有 3 中格式:
- 字符串
- int
- float
SET: 设置指定 key 的值
EXseconds – 设置键 key 的过期时间,单位时秒PXmilliseconds – 设置键 key 的过期时间,单位时毫秒NX– 只有键 key 不存在的时候才会设置 key 的值XX– 只有键 key 存在的时候才会设置 key 的值KEEPTTL-- 获取 key 的过期时间
GET:获取指定 key 的值
SETRANGE:从偏移量
offset开始, 用value参数覆盖键key中储存的字符串值。如果键key不存在,当作空白字符串处理.如果键
key中原来所储存的字符串长度比偏移量小(比如字符串只有5个字符长,但要设置的offset是10), 那么原字符和偏移量之间的空白将用零字节"\x00"进行填充。GETRANGE:返回存储在 key 中的字符串的子串(下标从 0 开始,可以使用负数)
SETEX:设置指定 key 的值,并设置过期时间(单位
s,⚠️已废弃,请使用 SET)PSETEX:设置指定 key 的 value,并设置过期时间(单位
ms,⚠️已废弃,请使用 SET))SETNX:在指定的 key 不存在时,为 key 设置指定的值(⚠️已废弃,请使用 SET)
MSET:为多个 key 设置值(原子操作,所有 key 的值同时设置)
MGET:获取多个 key 的 value
MSETNX:当且仅当所有给定键都不存在时, 为所有给定键设置值。(原子操作)
INCR:将 value+1
INCRBY:将 value 加上给定的增量
DECR: 将 value-1
DECRBY:将 value 减去给定的减量值
INCRBYFLOAT:将 value 加上给定的浮点数增量
APPEND:用于为指定的 key 追加值,若 key 不存在,效果 = SET
STRLEN: 返回字符串的长度
hash 类型
value 中存储的是 hash 表,适合用来存储对象
HSET:用于为存储在
key中的哈希表的field字段赋值value,若 hash 表不存在,则会创建一个 hash 表,若field已经存在,则覆盖旧值HGET:获取存储在哈希表中指定字段的值
HMSET:设置多个
filed的value( ⚠️已废弃,请使用 HSET)HMGET: 获取 hash 表中多个
field的值HSETNX: 为 hash 表的
field设置值,若field已经存在,则不执行HDEL:用于删除哈希表中一个或多个字段
HLEN:获取 hash 表中的字段个数
HEXISTS:用于判断哈希表中字段是否存在
HINCRBY: 让 hash 表中的
field加上指定的整数增量值HINCRBYFLOAT:让 hash 表中的
field加上指定的浮点数增量HGETALL:用于返回存储在
key中的哈希表中所有的field和valueHKYES: 获取 hash 表中所有的
fieldHVALS : 获取 hash 表中的所有
value
List 类型
List 的底层是一个双向链表,类似于 Java 的LinkedList,元素可以重复
- LPUSH: 从左侧插入一个或者多个元素
- RPUSH
- LPOP:移除并返回左侧的第一个元素
- RPOP
- BLPOP:移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止,是 LPOP 的阻塞版本
- BRPOP:
- LPUSHHX: 当 key 存在并且存储着一个 list 类型值的时候,向值 list 的头部插入 value
- RPUSHHX:
- LINSERT: 将某个值插入到指定元素的前面或者后面 。(例如
LINSERT nems before zwc zwc666)将 zwc666 插入到 zwc 前面 - LSET: 通过 index 设置 list 指定位置的值
- LREM: 从 list 中删除前 count 个 value 等于
element的元素- count > 0: 从头到尾删除值为 value 的元素(最多移除 count 个)
- count < 0: 从尾到头删除值为 value 的元素。(最多移除
|count|个) - count = 0: 移除所有值为 value 的元素
- LRANGE: 返回 list 中指定区间内的元素(
LRANGE nems 0 -1) - LTIRM: 用于修剪(trim)一个已存在的 list,这样 list 就会只包含指定范围的元素(这是很有用的,比如当用 Redis 来存储日志)
- LLEN:返回 List 的长度
- LINDEX:返回 索引 index 位置存储的元素。 index 下标是从 0 开始索引的,可以使用负数
Set 类型
简介:类似于 Java 中的 HashSet 集合(无序、元素不可重复、支持交集,并集,差集等)
- SADD:向 set 中添加一个/多个元素
- SREM:移除 set 中的一个/多个元素
- SCARD:返回 set 中元素的个数
- SPOP:随机删除 set 中的一个或者多个元素并返回
- SISMEMBER:判断一个集合是否存在于 set 中
- SMEMBERS:返回 set 中的所有元素
- SMOVE :从集合
source中移动成员member到集合destination。 这个操作是原子操作。 在任何时刻,member只会存在于source和destination其中之一。 - SINTER key1 key2: 求 key1 和 key2 的交集
- SDIFF key1 key2: 求 key1 与 key2 的差集
- SUNION key1 key2: 求 key1 和 key2 的并集
- SINTERSTORE:和 SINTER 类似,但是他会将结果存储到
destination集合中 - SDIFFSTORE:。。。
- SUNIONSTORE:。。。
SortedSet(ZSET)
简介:有序的 set 集合(可排序,元素不可重复、支持交集,并集,差集等),和 Java 中的 TreeSet 类似,SortedSet 中每一个元素都带有一个 score 属性,基于 score 属性对元素排序,底层的实现上一个跳表(SkipList)+hash 表(由于其可排序,因此经常用来实现排行榜这样的功能)
- ZDD:向 zset 中添加一个/多个元素,若存在则更新其 score 值
- ZREM:删除 zset 中的一个指定元素
- ZSCORE:获取 zset 指定元素的 score 值
- ZRANK:获取 zset 中指定元素的排名
- ZCARD:获取 zset 中元素的个数
- ZCOUNT:统计
score值在min和max之间的元素数量 - ZINCRBY:让 zset 中的指定元素的 score 加上指定的增量值
- ZRANGE:返回指定索引区间内的元素
- ZRANGEBYSCORE:返回指定分数区间内的元素
- ZRANGEBYLEX: 用于按字典顺序获取有序集合(
zset)中的元素。(可以指定字母的范围)(它特别适用于按字母顺序排列的场景) - ZREMRANGEBYLEX:移除 zset 中给定的字典区间的所有元素
- ZREMRANGEBYRANK:移除 zset 中给定排名区间的所有元素
- ZREMRANGEBYSCORE:移除 zset 中给定粉丝区间的元素
- ZINTER:交集
- ZDIFF:差集
- ZUNION:并集
- ZINTERSTORE:计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 key 中
- ZDIFFSTORE: 。。。
- ZUNIONSTORE: 。。。
⚠️:所有排名默认是升序的,若要降序,则在命名的 Z 后面添加REV即可
GEO
GEO 的底层使用的是 redis 的ZSet,添加一个坐标元素(给定经纬度),会通过一个算法转化为一串数字作为 zset 的 score,value 则自己提供
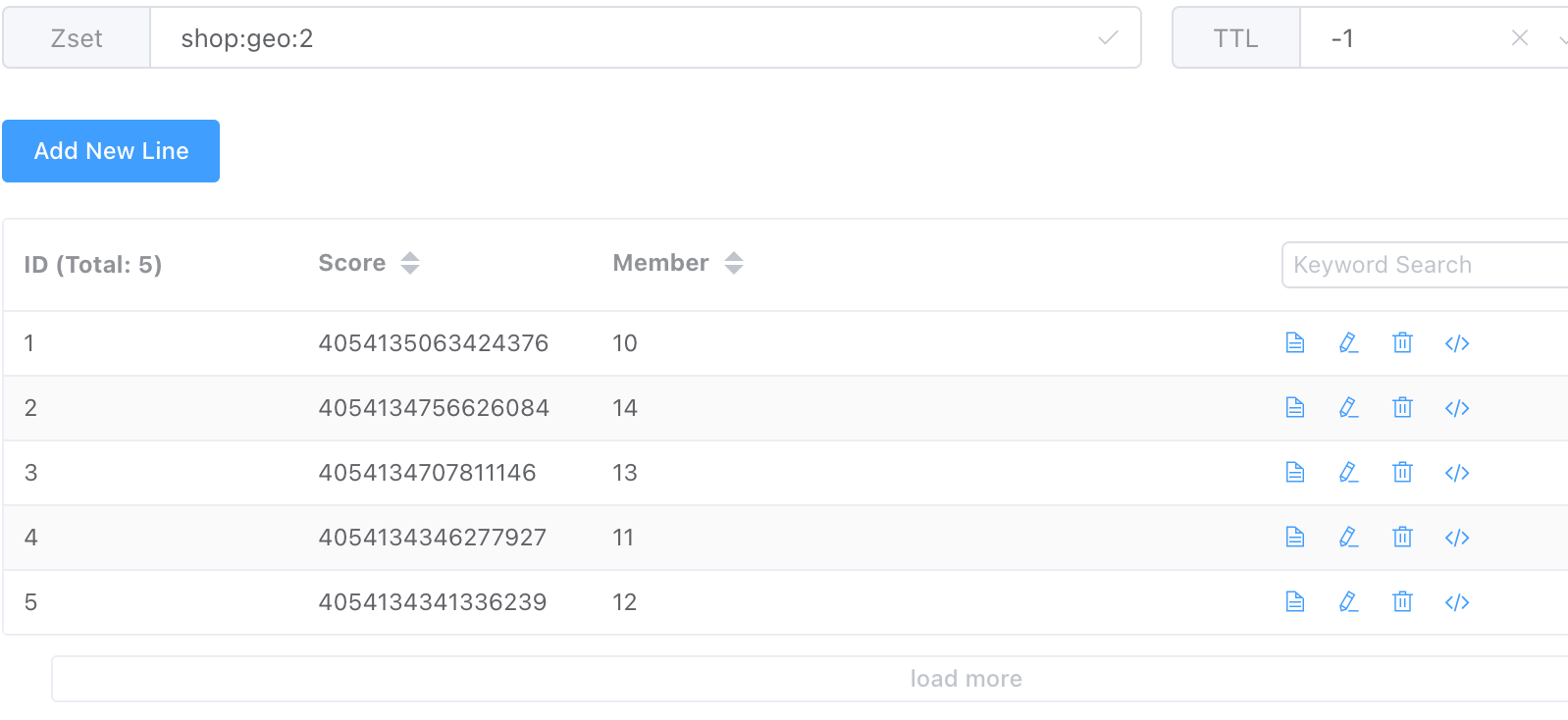
- GEOADD: 将指定的地理空间位置(纬度、经度、名称)添加到指定的 key 中
- GEODIST: 返回两个元素之间的距离
- GEOHASH: 返回一个或多个位置元素的 Geohash 表示
- GEOPOS: 返回一个或多个位置元素的位置(经度和纬度)
- GEORADIUS:以给定的经纬度为中心, 找出某一半径内的元素(已废弃,请使用 GEOSEARCH)
- GEOSEARCH:查找指定范围内的元素(可以按圆查找,也可以按矩形查找;可以使用给定的的经纬度作为中心点,也可以使用某个位置元素作为中心点)
- GEOSEARCHSTORE:和
GEOSEARCH类似,不过它会将查找到的结果存储在指定的 key 中
BitMap
redis 的 BitMap 是基于string类型实现的,所以最大上限为 512M,2^32 bit
- SETBIT: 向指定位置存入一个 0 或者 1, 返回这个位置原来的值(0/1)
- GETBIT:获取指定位置的 bit 值
- BITCOUNT:统计 BitMap 中值为 1 的数量
- BITFIELD:操作(查询、修改、自增)BitMap 中 bit 数组中指定位置(offset)的值 (可以同时操作多个位)
- BITFIELD_RO: BITFIELD 命令的变体,只有查询的操作
- BITOP:将多个 bitMap 的结果做位运算(与、或、异或)
- BITPOS:在指定范围内第一个 0 或者 1 出现的位置(从 0 开始)
HyperLogLog
UV 和 PV 的概念

HyperLogLog 的概念
HyperLogLog 是从 LogLog 算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。
Redis 在的 HLL 是基于string 结构实现的,且单个 HLL 的内存永远 < 16kb。但是其测量结果是概率性的,有<0.81%的误差,不过对于 UV 统计来说,完全可以忽略。
- 命令
- PFADD:向 HyperLogLog 中添加一个/多个元素(元素不重复)
- PFCOUNT:返回 HyperLogLog 中的大概的数量(有误差)
- PFMERGE:合并 N 个不同的 HyperLogLog 到一个里面
BloomFilter(布隆过滤器)
布隆过滤器是一种专门用来解决去重问题的高级数据结构(用来判断某个数字,字符串是否存在),由一个大型位数组和几个 hash 函数组成,会有一点不精确,有误判的概率
原理
举个例子:假设这里 BloomFilter 使用 3 个 hash 函数,
存入 BloomFilter 中:当我们要将 5 存入 BloomFilter 中时,会先使用这 3 个 hash 函数分别对 5 进行 hash,然后 在数组中的位置=(hash 值 % bit 数组长度),3 个 hash 函数对应 3 个位置(假设为 5,6,7),分别将这三个位置设置为 1。
判断元素是否存在:和上面类似,例如我们判断 5 是否存在,使用这 3 个 hash 函数分别对 5 进行 hash,然后 在数组中的位置=(hash 值 % bit 数组长度),3 个 hash 函数对应 3 个位置,若这 3 个位置的值都为 1,则返回 true(存在),否则返回 false(不存在)
特点
- BloomFilter 返回 false,则表示该数据一定不存在,BloomFilter 返回 true,则该数据可能存在,也可能不存在
- BloomFilter 只能添加元素,不能删除元素
- 添加和查询时间复杂度均为 O(k),其中 k 是哈希函数的数量。
使用场景
- 用来判断某个数据是否存在 redis 和数据库中,解决缓存穿透问题
- 黑名单检验(识别垃圾邮件、判断某个 IP 是否在黑名单中)
CuckooFilter(布谷鸟过滤器)
命令的参考手册
Java Redis 的三种客户端的比较
Jedis
优点
- api 和 redis 的命令一致,容易上手,
- 支持 pipelining、事务、LUA Scripting、Redis Sentinel、Redis Cluster 等等 redis 提供的高级特性。
缺点
- Jedis 在实现上是直接连接的 redis server,如果在多线程环境下是非线程安全的,这个时候可以使用连接池来管理 Jedis,来解决多线程环境下线程不安全的问题
- 采用了阻塞式 IO(不支持异步编程),可能在高负载下出现性能瓶颈。
Lettuce
优点
- 线程安全
- 支持同步编程,异步编程,响应式编程,自动重新连接,主从模式,集群模块,哨兵模式,管道和编码器等等高级的 Redis 特性
- 如果不是执行阻塞和事务操作,如 BLPOP 和 MULTI/EXEC 等命令,多个线程就可以共享一个连接,性能方面不会衰减
缺点
- API 更加抽象,学习使用成本高
Redission
优点
- 实现了分布式的特性和可扩展的数据结构。支持分布式锁、队列、信号量、集合等多种 Redis 基于对象的高级功能,适合分布式开发
- 线程安全
缺点
- 功能强大,但学习曲线较陡。
选择
Jedis 适合简单、同步的 Redis 操作,易于理解和使用。
Lettuce 适合需要高并发和异步操作的应用,提供更现代的编程模型。
Redisson 适合需要复杂分布式功能的应用,提供更高级的 Redis 操作抽象。
Redis 的基本使用
使用 Jedis
- 引入依赖
xml
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.1.2</version>
</dependency>- 配置 redis 连接池,以及基本使用
java
@SpringBootTest
class JedisApplicationTests {
private static Jedis jedis;
private static JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
private JedisPool jedisPool;
static {
//配置连接池
jedisPoolConfig.setMaxTotal(8);
jedisPoolConfig.setMaxIdle(8);
jedisPoolConfig.setMinIdle(4);
jedisPoolConfig.setMaxWait(Duration.ofMinutes(1));
}
@BeforeEach
void setUp() {
// jedis = new Jedis("localhost", 6379);
// 使用连接池
jedisPool = new JedisPool(jedisPoolConfig, "localhost", 6379);
// 获取redis的连接
jedis= jedisPool.getResource();
}
@Test
public void testJedis() {
jedis.select(1);
jedis.set("name", "zwc");
jedis.set("age", "100");
jedis.incrBy("age", 2L);
}
@AfterEach
void clear() {
if (jedis != null) {
//归还连接
jedis.close();
}
}
}使用 Spring-Data—Redis

- 引入依赖
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 如果要使用redis的连接池的话,需要添加下面的这个依赖-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!-- 序列化的依赖,若引入了spring-mvc,则不需要再手动引入jackson依赖-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>⚠️spring-data-redis 默认底层使用的是lettuce,若需要使用jedis,则需要手动引入 jedis 的依赖,再在application.yml中配置spring.data.redis.client-type的值为jedis
- 在
application.yml中配置 redis 的相关信息,以及连接池的相关信息
yml
spring:
data:
redis:
host: localhost
port: 6379
lettuce:
pool:
enabled: true
# 最小空闲的连接数量
min-idle: 0
# 最大的连接数
max-active: 8
# 最大空闲的连接数
max-idle: 4
# 当连接池中的连接耗尽时,最大等待多长时间就抛出异常
max-wait: 4000
# 设置客户端的类型,默认为lettuce,若使用jedis,则需要引入jedis的依赖
client-type: lettuce配置序列化方式
spring-data-redis 默认使用的是 jdk 的序列化,即使用
ObjectOutputStream和ObjectIputStream,这种序列化方式可读性差,会加上很多无用的东西,导致浪费内存,因此我们会自己定义序列化方式,下面的配置的序列化方式:
- key 使用 String 的序列化方式(key 一般是 string,因此使用 String 的序列化方式即可,若 key 不一定为 string,需采用其他的序列化方式)
- value 采用
jackson来进行序列化和反序列化。(需引入jackson-databind的依赖)
java
package leftover.springdataredis.config;
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> getRedisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(connectionFactory);
// 设置key的序列化方式
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setHashKeySerializer(RedisSerializer.string());
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
//设置value的序列化方式
redisTemplate.setValueSerializer(jsonRedisSerializer);
redisTemplate.setHashValueSerializer(jsonRedisSerializer);
return redisTemplate;
}
}- 使用
java
@Autowired
RedisTemplate<String, Object> redisTemplate;
@Test
void testString() {
ValueOperations<String, Object> valueOperations = redisTemplate.opsForValue();
valueOperations.set("name", "hjhjh");
Object name = valueOperations.get("name");
System.out.println(name);
valueOperations.set("user:100", new User("zwc777", 199));
User user = (User) valueOperations.get("user:100");
System.out.println(user);
}user 序列化之后的结果
json
{
"@class": "leftover.springdataredis.pojo.User",
"username": "zwc777",
"age": 199
}使用StringRedisTemplate
StringRedisTemplate 是 RedisTemplate 的子类, 这个类默认key 、value、hashKey、hashValue都采用 string 的序列化方式
java
@Autowired
StringRedisTemplate stringRedisTemplate;
ObjectMapper objectMapper = new ObjectMapper();
@Test
void testStringRedisTemplate() throws JsonProcessingException {
ValueOperations<String, String> valueOperations = stringRedisTemplate.opsForValue();
//手动序列化
String jsonStr = objectMapper.writeValueAsString(new User("zwc", 188));
valueOperations.set("user:300", jsonStr);
//手动反序列化
String s = valueOperations.get("user:300");
User user = objectMapper.readValue(s, User.class);
System.out.println(user);
}缓存
缓存的作用
- 对于一些经常访问的数据,我们可以将其放到 redis 中,这样业务应用在访问数据时,会先查询 Redis 中是否保存了相应的数据
若缓存中有相应的数据,称为
缓存命中,则直接从 Redis 中取出数据返回。(Redis 中的数据保存在内存中,性能好)若缓存中没有相应的数据,称为
缓存缺失,则需回源到数据库查询相应的数据,再将查询到的数据存入 Redis 中,以便之后的请求可以命中缓存。(需要回源到数据库,性能差)因此缓存可以用来提升网站的性能,尤其是高并发场景下的性能
- 数据库通常是应用的瓶颈之一。使用 Redis 缓存可以减少对数据库的直接访问,从而减轻数据库的压力,提升整个系统的吞吐量和稳定性。
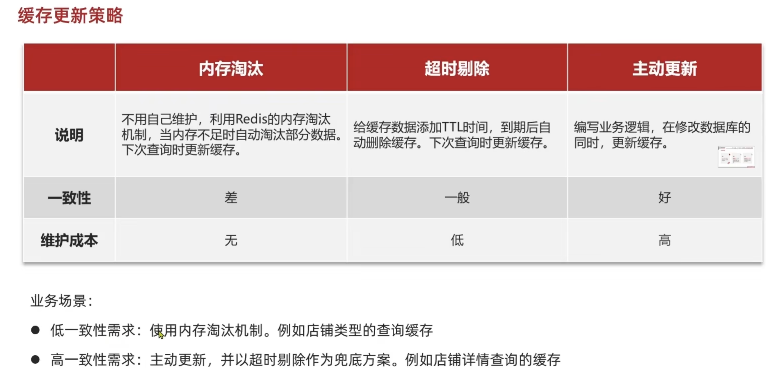
数据库中的数据更新时,如何处理缓存
Cache aside Pattern(缓存旁路模式)
- 更新缓存(双写模式):数据库中的数据更新时,更新对应的缓存。
- **优点:**下次访问可以直接命中缓存,不需要再查询数据库。
- **缺点:**在高并发场景下,并发更新同一个值,容易导致缓存和数据库中的数据不一致;且如果对于某些缓存值的计算比较复杂,但是又不经常访问,这样缓存的利用率就比较低。
- 删除缓存:数据库中的数据更新时,删除对应的缓存,下一次读取缓存时发生缓存缺失,再从数据库读取数据写回缓存(类似于懒加载的思想)。
- **优点:**这样缓存中保留的是经常访问的热点数据
- **缺点:**删除缓存后,之后的访问会触发一次缓存缺失,需要从数据库中取数据再写入缓存。(适用于读多写少的场景)
更新数据时缓存一致性问题
缓存一致性问题是指缓存中的数据和数据库中的数据存在不一致的情况。
双写模式
TODO:https://juejin.cn/post/7190400432294854711#heading-8
Cache aside Pattern
如果是更新数据,就有先删缓存还是先更新数据库的区分(通常我们会选择先更新数据库再删除缓存)
从下图可以看出,无论是先更新数据库还是先删除缓存,都存在数据一致性的问题。
当采用先更新数据库再删除缓存的方法,但是在实际的业务中,发生这种情况的概率是很小很小的,因为数据库的写入通常要比缓存的写入的时间要长得多了,所以很难出现上述的情况,所以概率很小的条件下,先更新数据库再删除缓存是可以接受的。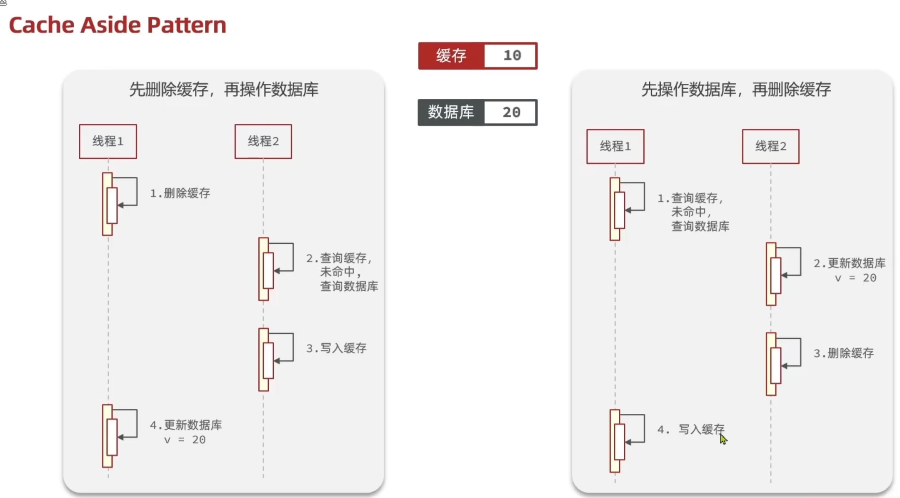
总结:
- 如果选用先删除缓存再更新数据库的方案,那么在读+写的并发操作下,依旧存在数据的不一致性(数据最终一致性),可以通过延迟双删的方式进行优化(延迟双删指先删除一次缓存,等更新完数据库后,延迟一会,再删除一次缓存),优化难点:这延迟一会就很控制。
- 选用先更新数据库再删除缓存的方案,在所有方案中更新数据时数据在缓存和数据库中的一致性效果是最好的,推荐使用该方案(先更新数据库再删除缓存)
- 但是先更新数据库再删除缓存的方案同样存在一些别的问题:如果更新完数据库后删除缓存的过程中出现了问题,此时便会导致缓存中的数据依旧是旧数据,数据库又是新数据,便会带来不一致性,说白了就是这两个操作不是原子操作,依旧会带来问题。
- ⚠️建议给缓存加上过期时间,这样即时出现缓存不一致的情况,缓存的数据也会很快过期,对业务还是能接受的。
如何解决原子性的问题:https://juejin.cn/post/7190400432294854711#heading-10
缓存穿透
用户请求的数据在缓存和数据库中都不存在,若有大量这样的请求,则会给数据库带来巨大的压力
原因:
- 业务误操作,缓存中的数据和数据库中的数据都被误删除了,所以导致缓存和数据库中都没有数据;
- 黑客恶意攻击,故意大量访问某些读取不存在数据的业务
解决方法:
第一种方案,非法请求的限制。在非法请求打入缓存之前,我们对请求对参数进行判断,看是否存在非法值,若存在则进行拦截,返回错误信息给前端
第二种方案,缓存空值或者默认值。 我们可以给这个不存在的 key 也缓存起来,value 为
空字符串或者缺省值(过期时间设置得短一点),这样后续的请求就可以从缓存中取出空值直接返回。- 缺点:造成额外的内存消耗,redis 中会保存一些不存在的 key
第三种方案,使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在;若存在则继续后面的流程,若不存在则直接返回错误信息给前端。
- 优点:速度快
- 缺点:存在误判的可能,查询布隆过滤器说数据存在,并不证明数据库中一定存在这个数据,但是查询布隆过滤器说数据不存在,那么数据库中就一定不存在这个数据
缓存雪崩
什么是缓存雪崩?
通常我们为了保证缓存中的数据与数据库中的数据一致性,会给 Redis 里的数据设置过期时间,当缓存数据过期后,用户访问的数据如果不在缓存里,业务系统需要重新生成缓存,因此就会访问数据库,并将数据更新到 Redis 里,这样后续请求都可以直接命中缓存。
那么,当大量缓存数据在同一时间过期(失效)或者 Redis 故障宕机时,如果此时有大量的用户请求,都无法在 Redis 中处理,于是全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃,这就是缓存雪崩的问题。
解决 大量缓存数据在同一时间过期 的问题
如果要给缓存数据设置过期时间,应该避免将大量的数据设置成同一个过期时间。我们可以在对缓存数据设置过期时间时,给这些数据的过期时间加上一个随机数,这样就保证数据不会在同一时间过期。
当业务线程在处理用户请求时,如果发现访问的数据不在 Redis 里,就加个互斥锁,保证同一时间内只有一个请求来构建缓存(从数据库读取数据,再将数据更新到 Redis 里),当缓存构建完成后,再释放锁。未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
实现互斥锁的时候,最好设置超时时间,不然第一个请求拿到了锁,然后这个请求发生了某种意外而一直阻塞,一直不释放锁,这时其他请求也一直拿不到锁,整个系统就会出现无响应的现象。(不适用高并发情况)
后台更新缓存
业务线程不再负责更新缓存,缓存也不设置有效期,而是让缓存“永久有效”,并将更新缓存的工作交由后台线程定时更新。
事实上,缓存数据不设置有效期,并不是意味着数据一直能在内存里,因为当系统内存紧张的时候,有些缓存数据会被“淘汰”,而在缓存被“淘汰”到下一次后台定时更新缓存的这段时间内,业务线程读取缓存失败就返回空值,业务的视角就以为是数据丢失了。
解决上面的问题的方式有两种。
第一种方式,后台线程不仅负责定时更新缓存,而且也负责频繁地检测缓存是否有效,检测到缓存失效了,原因可能是系统紧张而被淘汰的,于是就要马上从数据库读取数据,并更新到缓存。
这种方式的检测时间间隔不能太长,太长也导致用户获取的数据是一个空值而不是真正的数据,所以检测的间隔最好是毫秒级的,但是总归是有个间隔时间,用户体验一般。
第二种方式,在业务线程发现缓存数据失效后(缓存数据被淘汰),通过消息队列发送一条消息通知后台线程更新缓存,后台线程收到消息后,在更新缓存前可以判断缓存是否存在,存在就不执行更新缓存操作;不存在就读取数据库数据,并将数据加载到缓存。这种方式相比第一种方式缓存的更新会更及时,用户体验也比较好。
解决 Redis 故障宕机 的问题
**事前:**构建 Redis 缓存高可靠集群
如果 Redis 缓存的主节点故障宕机,从节点可以切换成为主节点,继续提供缓存服务,避免了由于 Redis 故障宕机而导致的缓存雪崩问题
**事中:**我们可以在业务服务中增加 服务降级、熔断限流 的机制,在 Redis 实例已经故障时,避免大量的请求打到数据库层。
一是对 Redis 的访问做资源隔离,在 Redis 故障时,进行熔断,不再访问 Redis 实例,直接返回预定义信息或错误信息,避免长时间阻塞占用应用资源,进而导致系统雪崩。待 Redis 恢复服务后,再将请求发送到 Redis 缓存。
二是对请求进行限流,在业务系统的请求入口控制每秒进入系统的请求数,避免过多的请求被发送到数据库,防止引发连锁的数据库雪崩,甚至是整个系统的崩溃。
**事后:**在 Redis 重启后,需要快速恢复数据,这就需要事前开启了 Redis 的 AOF 和 RDB 持久化机制。并且做好定期备份,防止 AOF 和 RDB 文件损坏或丢失
缓存击穿
我们的业务通常会有几个数据会被频繁地访问,比如秒杀活动,这类被频地访问的数据被称为热点数据。
如果缓存中的某个热点数据突然过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮,这就是缓存击穿的问题(也叫热点 Key 问题)。 缓存击穿问题和缓存雪崩问题很类似,可以认为缓存击穿问题是缓存雪崩问题的一个子集
解决方法
- 互斥锁方案,保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。(在缓存重建的时候会降低并发量)
- 不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间;
Redis 实现分布式锁
实现思路
利用 sex nx ex 获取锁,并设置过期时间(兜底的方案,如果程序中没有释放锁,时间到期了会自动释放),value 为一个随机值(这里使用 uuid+线程 id)
释放锁的时候先判断这个获取的 value 与当前自己的标识是否一致,一致才删除,不一致则说明这个锁不是自己的,则不删除(防止误删别人的锁)
我们需要保证释放锁的时候的一个原子性,可以编写一个释放锁的 lua 脚本,Java 中调用这个 lua 脚本来释放锁
代码如下:
java
@AllArgsConstructor
@NoArgsConstructor
@Getter
@Setter
@Service
public class Lock implements ILock {
private static final String LOCK_PREFIX = "lock:";
private String name;
private StringRedisTemplate stringRedisTemplate;
private final String ID_VALUE = UUID.randomUUID().toString(true) + Thread.currentThread().getId();
private static DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
static {
// 设置lua脚本
redisScript.setLocation(new ClassPathResource("lua/lock.lua"));
}
@Override
// 获取锁
public boolean tryLock(long timeout) {
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent(LOCK_PREFIX + name, ID_VALUE, timeout, TimeUnit.SECONDS);
// 获取到锁
// 因为上述是包装类,所以如何直接return lock的话可能会返回一个null,然后自动拆箱的时候会出现异常
return BooleanUtil.isTrue(lock);
}
//释放锁
@Override
public void unlock() {
// 执行lua脚本, 只有相匹配的时候才会释放锁,防止释放别人的锁
stringRedisTemplate.execute(redisScript, List.of(LOCK_PREFIX + name), ID_VALUE);
}
}释放锁的 lua 脚本
lua
if (redis.call("get", KEYS[1]) == ARGV[1]) then
return redis.call("del", key)
end
return 0调用
java
// 传入过期时间
boolean tryLock = lock.tryLock(1200);
// 没有获取到锁
if (!tryLock) {
return Result.fail("不能重复下单");
}
// 获取到锁了
try {
IVoucherService currentProxy = (IVoucherService) AopContext.currentProxy();
// 返回订单id
return currentProxy.createSecKillOrder(id, userId);
} finally {
// 释放锁
lock.unlock();
}存在的问题

解决不可重入的问题
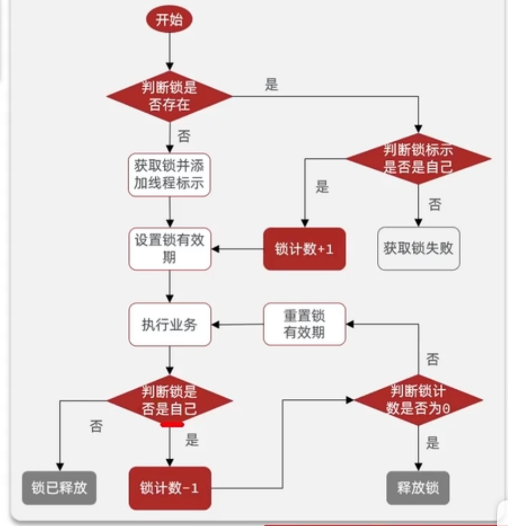
上述我们在 redis 中存的是字符串,要想实现可重入锁,可以采用 hash 结构,hkey 为当前线程的标识,hvalue 为重入的次数。大概是这样的一个结构
思路:
在获取锁的时候,首先根据 key 判断锁是否存在,若不存在则表示当前线程没有获取到锁,使用 hset 设置 value
若有这个 key,则表示当前线程已经获取到锁了,再根据 hkey(线程标识符)判断这个锁是不是自己的,
若是自己的,则使用 hincyby 命令将 vlaue+1
若不是自己的,则表示获取锁失败,return
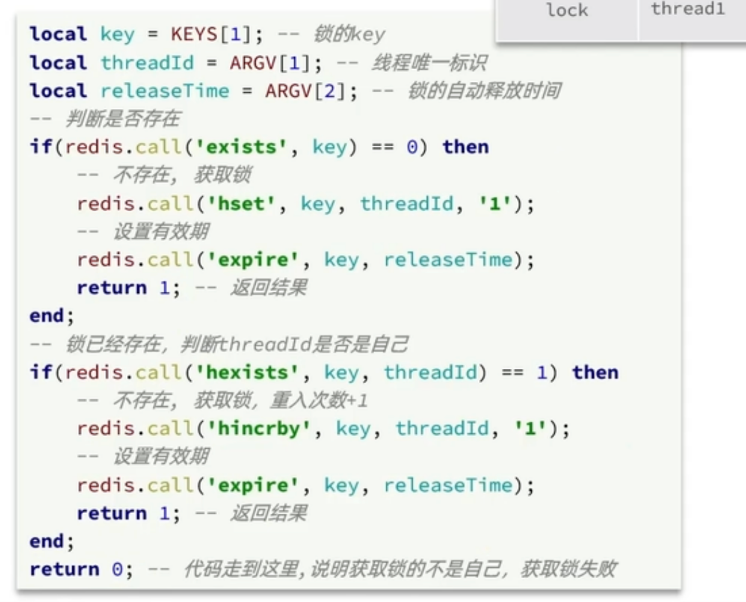
释放锁的时候,判断锁是否还被自己持有,若不是,则直接 return(说明过期了)
若是,则使用 hincrby 将 value–1,再判断是否>0 ,
若>0,则不能释放锁, 若<= 0,则释放锁

解决可重试问题
Redisson 利用信号量和 PubSub 功能实现了锁的重试,在创建 RedissonClient 时,我们可以设置重试的时间
当我们锁获取失败的时候,判断剩余的重试时间是否 >0.
若<= 0,则不会进行重试了,直接返回 false(获取锁失败)
若 > 0 , 则会订阅锁释放的消息,当有锁释放时,会 publish 一条消息,此时会进行重新获取锁。重复这样的逻辑,直到剩余的 重试时间<=0
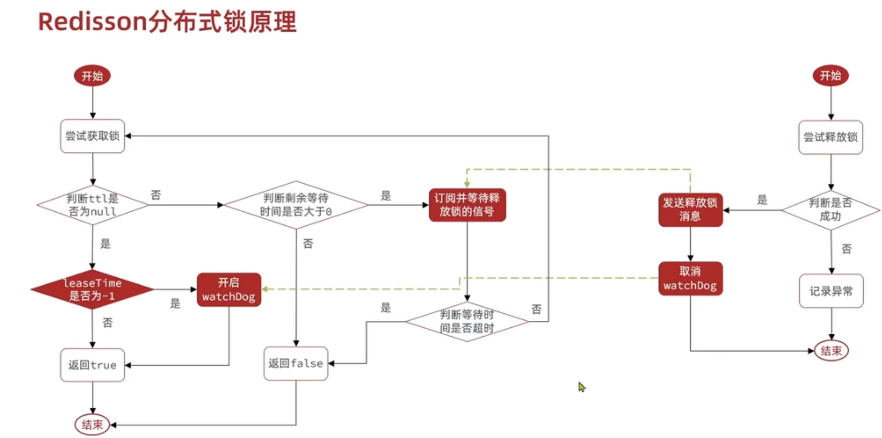
解决超时释放的问题(看门狗机制)
锁都设置了超时时间(以防止锁一直释放不掉,导致程序卡死,作为一种兜底的方案)。
当超过了有效时间,锁就自动释放了(即 redis 里面的数据过期了),有时候可能是因为业务计算量比较大导致的,而不是因为意外导致没有把锁释放掉。这时候锁释放掉是我们不想看到的,因此 Redisson 设置了一个看门狗的机制,原理就是设置一个定时器,每隔一段时间(有效时间/3=10s)就会重置超时时间。当锁释放时,会取消定时器。
解决主从一致性问题
发生的原因:
当 redis 搭建了主从集群,这时候主从同步存在延迟,这时候我们的一个线程获取到了锁,但是这时候主节点宕机了,锁的数据还没同步给从节点,之后会选举一个从节点作为主节点,这时候主节点中就没有锁的信息,其他线程就能获取到锁。
解决方法:
采用联锁的方式,我们可以部署多个 redis 节点(非主从关系),若需要保证高可用,可以为这些 redis 部署一个从节点。当获取锁的时候,需要从每个 redis 节点中都获取锁,只有每个 redis 节点的锁都获取成功,这个锁才获取成功。这样即使有某个 redis 节点挂了,其他的线程也不能获取到锁。
三种方案的优缺点

Redis 实现消息队列
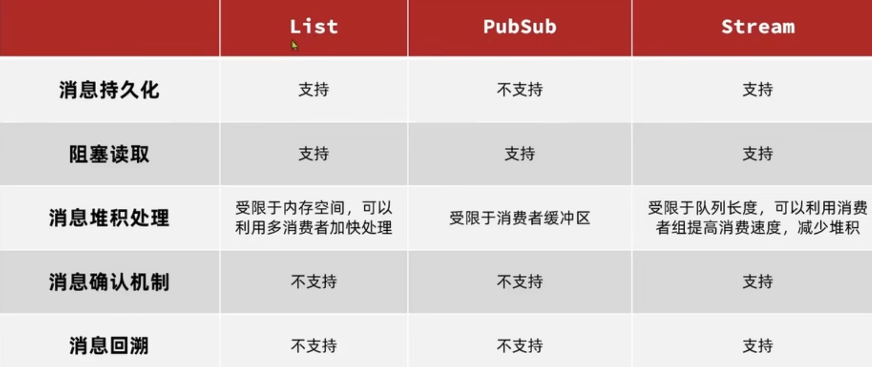
List 实现消息队列
可以使用 LPUSH 和 BRPOP 来实现消息队列, 生产者使用 LPUSH 往 List 中放消息,使用 BRPOP 从 list 中取出消息
优点:
- 使用的是 Redis 的数据结构,可以用 Redis 的持久化机制,数据安全有保证
- 可以满足消息的有序性
缺点:
- 只能读取一条消息,当同时有多个消息时,其他消息会丢失
- 只支持单消费者
Pub/Sub 实现消息队列
使用 Redis 的PSUBSCRIBE 、SUBSCRIBE 来订阅频道, 使用PUBLISH来发布消息
优点:
支持多个生产者,多个消费者
缺点:
不支持数据持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
无法避免消息丢失
消息堆积有上限,超出时数据会丢失
基于 Stream 的消息队列
基本命令
XADD
向 stream 中添加 message
sh
XADD x1 * name zwc age 18
XREAD
从 stream 中读取消息,一个消息可以被多次读取
shell
XREAD Block 0 Streams x1 0
XGROUP CREATE

创建消费者组
shell
XGROUP CREATE x1 g1 0创建一个名为 g1 的消费者组,从 x1 中读取消息(从头消费),若为 $ ,则表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略。

XREADGROUP
多个消费者消费消息
有 ack 机制,保证消息至少被消费一次
可以阻塞读取
shell
XREADGROUP Group g1 c1 block 0 Streams x1 0
建议:正常情况我们使用 > 开始读取下一个未消费的消息
当 redis 宕机之后我们可以使用 0 ,从 pending-list 中读取已消费但未确认的消息,之后再使用> 开始读取下一个未消费的消息
各种方案的比较
Feed 流
Feed 流产品一般有 2 种模式:
- Timeline:简单地按内容发布时间排序,常用语好友或者关注,例如朋友圈,twitter
- 智能排序:利用智能算法推送用户感兴趣的信息来吸引用户。例如抖音,快手等等
Timeline 模式
Timeline 模式的实现方案有 3 种:
- 拉模式
- 推模式
- 推拉模式
拉模式
也叫做读扩散。简单来说就是每个用户发送的“动态”存放在一个地方(发件箱),用户想要读取它关注的列表的“动态”时,就从发件箱拉下来即可
推模式
也叫做写扩散。 简单来说就是我发了条“动态”,那么这条动态会存放在我的每一个粉丝的收件箱中,用户想要读取它关注的列表的“动态”时,从收件箱中读取即可
推拉结合模式
也叫做读写混合,兼具推和拉两种模式的优点。简单来说:
- 普通用户发的动态会被推送到他的所有粉丝收件箱中。
- 如果是大 V,它的粉丝很多,那么他是直接将“动态”先写入到一份到发件箱里一份,然后再直接写一份到活跃粉丝收件箱里边去。
当用户想要读取它关注的列表的动态时,如果是活跃用户,那么大 V 和普通的人发的都会直接写入到自己收件箱里边来,直接从收件箱读取即可;而如果是普通的用户,由于他们上线不是很频繁,所以等他们上线时,再从发件箱里边去拉信息。
两种模式的比较
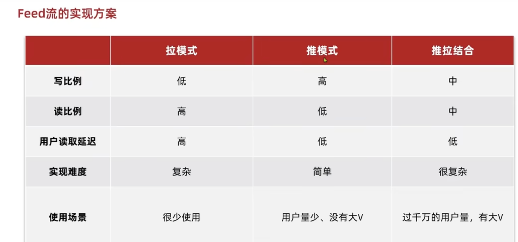
分页的方式
普通的分页 和滚动分页
普通分页的问题
在 feed 流中,使用普通的那种(根据排名)分页的方式,当粉丝在查看东西时,若此时其他博主发送了一条新的 blog,这时候查询就会出现问题,会查询到一条上一次相同的数据
滚动分页
滚动分页是这一次查询是从上一次的最后一条数据开始查询,因此若突然其他博主发了一篇 blog,也不会有影响
可以使用 redis 的ZREVRANGEBYSCORE 命令实现
Redis 持久化
RDB
什么是 RDB?
RDB 全称 Redis Database Backup file(Redis 数据备份文件),也叫 Redis 数据快照。简单来说就是把内存中的所有数据都记录到磁盘中,当 redis 实例故障重启后,会从磁盘中读取快照文件,恢复数据。
执行 RDB
save命令,由 redis 主进程来执行 RDB,会阻塞所有命令bgsave命令,开启子进程执行 RDB,避免主进程受到影响执行 shutdown 命令时会触发
bgsave主从复制时,从节点要从主节点进行全量复制时也会触发 bgsave 操作,生成当时的快照发送到从节点;
redis.conf 中配置
save m n,即在 m 秒内有 n 次修改时,自动触发 bgsave 生成 rdb 文件;

bagsave 的基本流程?
- redis 客户端执行 bgsave 命令或者自动触发 bgsave 命令;
- 主进程判断当前是否已经存在正在执行的子进程,如果存在,那么主进程直接返回;
- 如果不存在正在执行的子进程,那么就 fork 一个新的子进程进行持久化数据(这里就是复制一个主进程的页表),fork 过程是阻塞的,fork 操作完成后主进程即可执行其他操作;
- 子进程先将数据写入到临时的 rdb 文件中,待快照数据写入完成后再原子替换旧的 rdb 文件;
- 同时发送信号给主进程,通知主进程 rdb 持久化完成,主进程更新相关的统计信息(info Persitence 下的 rdb_*相关选项)。
那么将内存中的数据同步到硬盘的过程可能就会持续比较长的时间,而实际情况是这段时间 Redis 服务一般都会收到数据写操作请求。那么如何保证数据一致性呢?
- RDB 中的核心思路是 Copy-on-Write,首先 fork 一个子进程进行持久化数据的操作(复制主进程的页表),之后当子进程在进行持久化数据时,若主进程需要修改某一块数据,那么这块数据就会被复制一份,生成该数据的副本,然后子进程就将副本数据写入 RDB 文件中,主进程仍然可以直接修改原数据
AOF
什么是 AOF?
AOF 全称
Append Only File,会记录每次(增删改)的命令到 aof 文件中,当 redis 重启时,会读取 aof 文件中的命令重新执行,防止数据的丢失。Redis7.0 之后的变化
redis7.0 之前是只有一个 aof 文件的
redis7.0 之后采用了 Multi Part AOF,MP-AOF 就是将原来的单个 AOF 文件拆分成多个 AOF 文件。在 MP-AOF 中,我们将 AOF 分为三种类型,分别为:
BASE:表示基础 AOF,它一般由子进程通过重写产生,该文件最多只有一个。INCR:表示增量 AOF,它一般会在 AOFRW 开始执行时被创建,该文件可能存在多个。HISTORY:表示历史 AOF,它由 BASE 和 INCR AOF 变化而来,每次 AOFRW 成功完成时,本次 AOFRW 之前对应的 BASE 和 INCR AOF 都将变为 HISTORY,HISTORY 类型的 AOF 会被 Redis 自动删除。为了管理这些 AOF 文件,引入了一个
manifest(清单)文件来跟踪、管理这些 AOF。同时,为了便于 AOF 备份和拷贝,我们将所有的 AOF 文件和 manifest 文件放入一个单独的文件目录中,目录名由 appenddirname 配置(Redis 7.0 新增配置项)决定。
开启 AOF:
AOF 默认是关闭的,可以通过配置
appendonly yes开启,通过配置appendfilename xxxx设置 aof 文件名称AOF 的命令记录的时机
默认为
everysec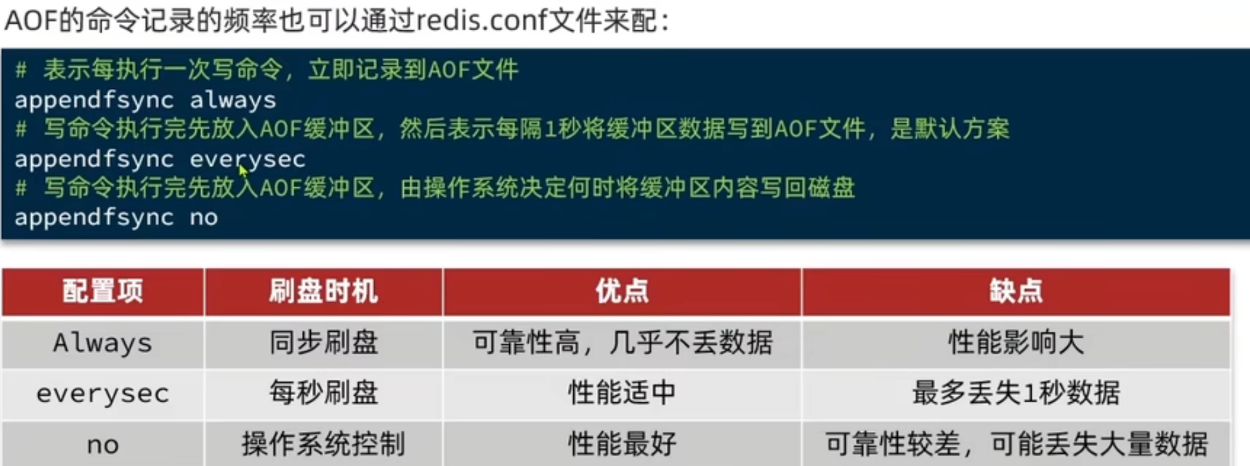
AOF 重写
由于 AOF 记录的是操作的命令,所以 AOF 文件会比 RDB 文件大的多,并且 AOF 会记录同一个 key 多多次写操作,但只有最后一次写操作才有意义。通过重写,会修改 aof 文件的内容,用最少的命令达到相同的效果
手动重写:执行
BGREWRITEAOF命令自动重写:在 redis.conf 中配置
yml# 重写触发配置 # AOF文件比上次重写后的文件 增长超过100%则触发重写 auto-aof-rewrite-percentage 100 # AOF文件体积超过64mb则触发重写 auto-aof-rewrite-min-size 64mb在重写 AOF 文件时的整个过程
- Redis7.0 之前
- fork 一个子进程处理重写任务
- 子进程开始向一个临时文件中重写 AOF
- 父进程除了会将写命令写入旧的 aof 文件中,还会写一份到
aof_rewrite_buf中进行缓存(因此即使重写失败也没什么损失) - 当子进程完成重写任务,父进程收到一个信号,追加
aof_rewrite_buf缓冲区的命令到子进程创建的新 AOF 文件末尾 - TODO: 管道技术
- 最后修改临时的 AOF 文件名,此时原来的 aof 文件会被覆盖
- Redis7.0 之后
- fork 一个子进程处理重写任务
- 子进程执行重写的逻辑产生一个新的 base.aof 文件,父进程会开启一个新的 incr.aof 文件继续写入(重写期间父进程接收到的写命令会保存在这里)。新生成的 BASE AOF 和新打开的 INCR AOF 就代表了当前时刻 Redis 的全部数据
- 重写结束之后,主进程会更新 manifest 文件,将新生成的 base aof 和 incr aof 信息加入进去,并将之前的 base aof 和 incr aof 标记为 history(这些 history aof 会被 redis 异步删除)。一旦 manifest 文件更新完成,表示整个 aof 重写流程结束
- Redis7.0 之前
Reference
Redis 7.0 Multi Part AOF 的设计和实现
混合模式
开启混合模式
yml# 必须先开启AOF appendonly yes # 开启混合模式 aof‐use‐rdb‐preamble yes混合模式基本原理
Redis7.0 之前
Redis7.0 之前只有一个aof 文件,在混合模式下,这个 aof 文件的头部为
rdb的数据(保存的是内存的快照),尾部为aof日志(记录增量的 aof 写命令)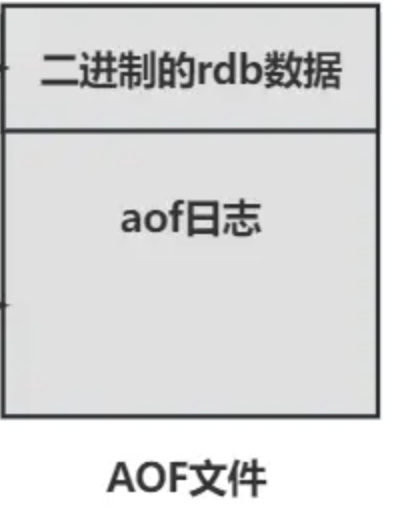
混合模式持久化是通过 bgrewriteaof 命令操作的
- fork 一个子进程,创建一个临时的 aof 文件,将当前内存的数据快照写入 aof 文件的头部(和 rdb 的原理一样)
- 写入 rdb 的过程中,若有新的写操作,则将写命令追加到 aof 文件末尾
- 完成重写之后重命名文件名覆盖之前的 aof 文件
Redis7.0 之后
- 在 7.0 之后,混合模式下会有
appendonlydir文件夹,一般包含一个base.rdb文件,类似appendonly.aof.1.base.rdb;一个/多个incr.aof文件,类似appendonly.aof.4.incr.aof; 还有一个清单文件appendonly.aof.manifest - 和 7.0 之前类似,也是基于 bgrewriteaof 命令操作的
- fork 一个子进程,创建一个新的 base.rdb 文件,和新的 incr.aof 文件,将当前的快照信息写入新的 base.rdb 文件(重写期间父进程接收到的写命令保存到新的 incr.aof),新生成的 base.rdb 和新生成的 incr.aof 文件就代表了当前时刻 Redis 的全部数据
- 重写结束之后,主进程会更新 manifest 文件,将新生成的 base.rdb 和 incr.aof 的文件信息加入进去,并将旧的 base.rdb 和 incr.aof 标记为 history(这些 history aof 会被 redis 异步删除)。一旦 manifest 文件更新完成,表示整个 aof 重写流程结束
- 在 7.0 之后,混合模式下会有
混合模式下恢复数据
先将 base.rdb 文件中的数据加载到 redis,然后再重放 incr.aof 日志,重启效率大幅得到提升
恢复数据的优先级
若开启了 AOF,则优先加载 AOF 文件恢复数据,若没有开启 AOF/AOF 文件不存在,则加载 RDB 文件恢复数据。
原因:因为 AOF 保存的数据更完整,AOF 基本上最多损失 1s 的数据。
RDB 和 AOF 的优缺点
RDB
优点:
- RDB 文件会压缩,文件体积相对 AOF 文件较小
- Redis 加载 RDB 文件恢复速度要远快于 AOF 方式
缺点:
- RDB 执行间隔长,若期间 redis 宕机了,则丢失的数据比较多
- 每次调用 bgsave 的时候都需要 fork 子进程,频繁执行成本较高
- RDB 文件是二进制的,没有可读性,而 AOF 文件在了解其结构的情况下可以手动修改文件或者补全
AOF
优点:
plain 1. 可靠性比较高,最多丢失 1s 钟的数据
系统资源占用比较低,主要是占用 io 资源,但是 AOF 重写的时候会占用比较多的 cpu 和磁盘资源
缺点:
plain 1. aof 文件会比较写操作的命令,所以文件体积比较大
宕机恢复速度比 RDB 慢
Redis 主从
概述
⚠️说明: REPLICAOF命令和SLAVEOF命令一样,REPLICAOF 命令是 5.0 之后的,下面全部使用REPLICAOF命令
redis 的主从结构默认就支持读写分离,即主节点可读可写,从节点只读
redis 配置主从很简单,使用 redis-cli 登录上需要作为 salve 结点的 redis,使用
REPLICAOF命令来设置这个哪个节点作为当前结点的 master(如此时当前结点已经是 salve 结点,则会修改其 master 结点)
例如REPLICAOF 172.18.0.4 6379
REPLICAOF NO ONE命令会停止复制,把结点改为主结点。(可以用于当 master 挂掉时,使用该命令设置某个从节点设置为 master,这时这个 master 是没有任何 salve 结点的,需要手动重新配置所有原从节点指向新的主节点)
docker-compose 搭建 redis 主从
yml
version: '3.8'
services:
redis-master:
image: redis:7.2.5
container_name: redis-master
ports:
- "7777:6379"
volumes:
- redis-master-data:/data
command: ["redis-server", "--appendonly", "yes"]
redis-slave1:
image: redis:7.2.5
container_name: redis-slave1
ports:
- "7778:6379"
depends_on:
- redis-master
volumes:
- redis-slave1-data:/data
command: ["redis-server", "--appendonly", "yes", "--slaveof", "redis-master", "6379"]
redis-slave2:
image: redis:7.2.5
container_name: redis-slave2
ports:
- "7779:6379"
depends_on:
- redis-master
volumes:
- redis-slave2-data:/data
command: ["redis-server", "--appendonly", "yes", "--slaveof", "redis-master", "6379"]
volumes:
redis-master-data:
redis-slave1-data:
redis-slave2-data:主从同步的原理
全量同步
- salve 节点请求增量同步(发送 replId 和 offset)(会先尝试增量同步,被拒绝之后才会全量同步)
- master 节点判断 replid 是否与自己的一致,发现不一致,拒绝增量同步,返回自己的 replId 和 offset(replId 一致表示在同一个数据集中)
- master 节点执行 bgsave,生成 RDB,发送 RDB 到 salve 节点(master 将 bgsave 期间的命令记录在
replication buffer) - salve 节点清空本地数据,加载 master 的 RDB 文件
- master 将
replication buffer中的命令持续发送给 salve,salve 执行接收到的命令并执行,保持与 master 之间的同步 - 待同步完毕后,主从之间会保持一个长连接,主节点会通过这个连接将后续的写操作传递给从节点执行,来保证数据的一致。
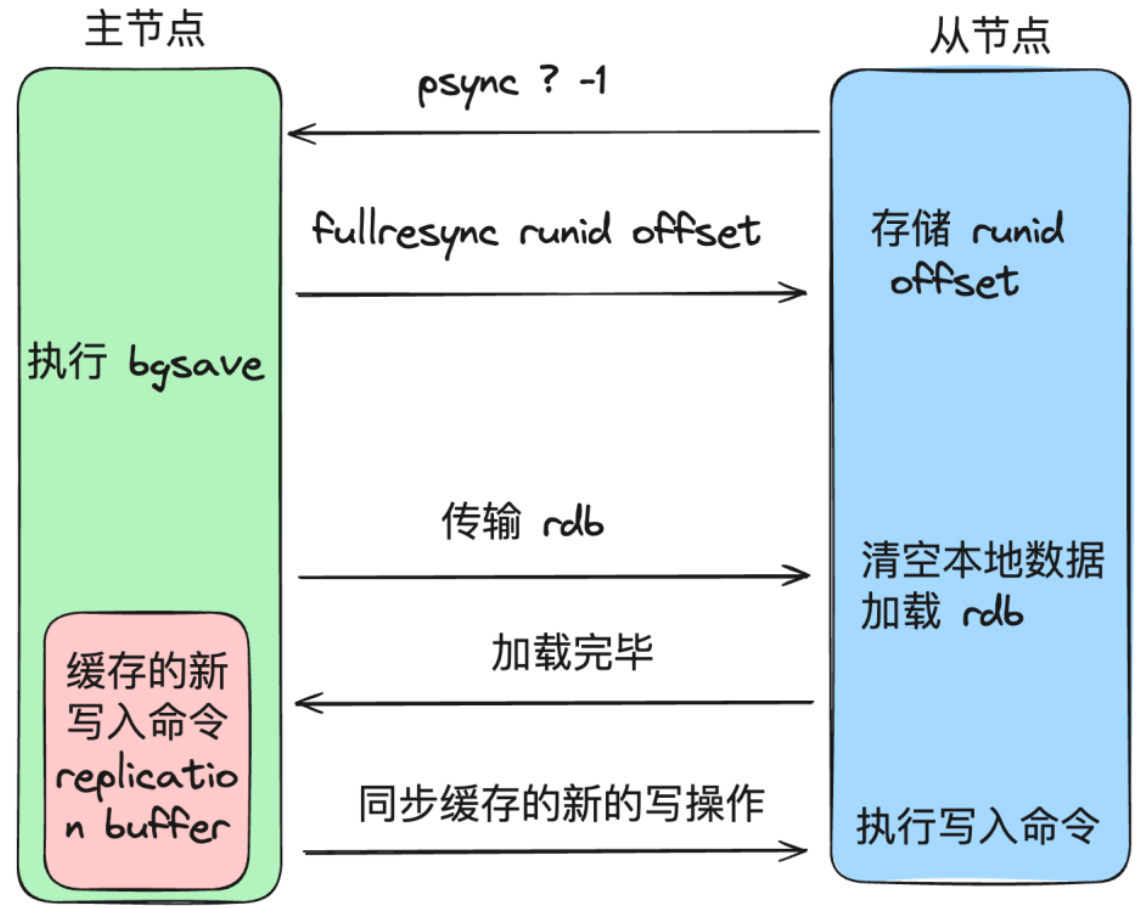
增量同步
- 网络断了之后,主从库会采用增量复制的方式继续同步。master 节点判断 replid 和自己的是否一致,发现一致,则根据 slave 发送过来的 offset,且根据 offset 判断数据还在
repl_backlog_buffer中,则说明可以进行增量同步**(如果根据 offset 判断数据已经被覆盖了,此时只能触发全量同步!)**。于是就去repl_backlog_buffer查找对应 offset 之后的命令数据,写入到replication buffer中,最终将其发送给 slave 节点。slave 节点收到指令之后执行对应的命令,一次增量同步的过程就完成了。
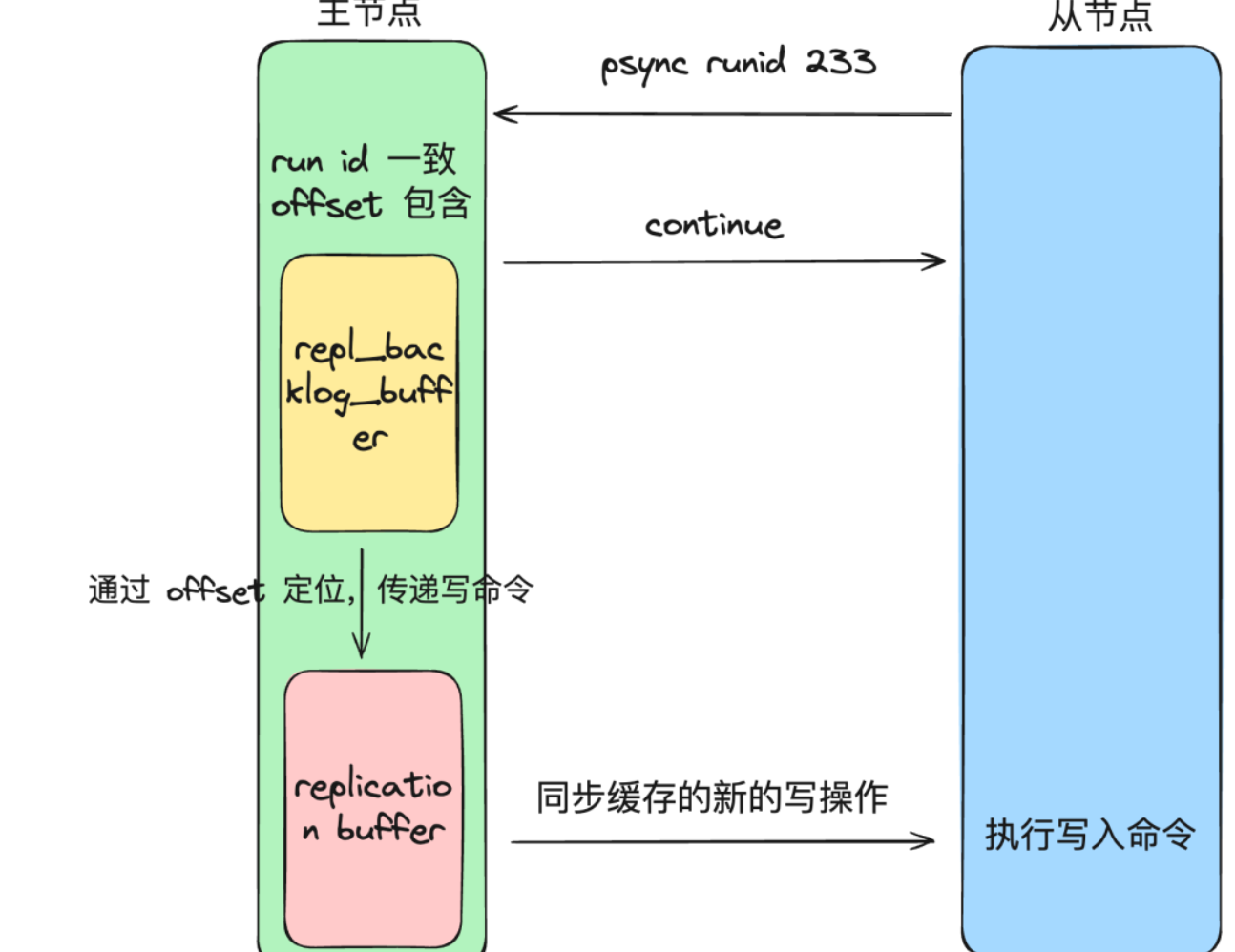
replId 和 offset 的作用
master 节点根据 salve 发送过来的 replid 和自己的是否一致来判断 salve 是不是第一次来同步数据,若不一致,则是第一次同步数据;否则则不是第一次同步数据

replication buffer 和 repl backlog buffer 的区别
repl_backlog_buffer
不管在什么时候 master 都会将写指令操作记录在 repl_backlog_buffer 中,因为内存有限, repl_backlog_buffer 是一个定长的环形数组,如果数组内容满了,就会从头开始覆盖前面的内容,用于从服务器重新连接时进行增量同步。
replication buffer
因为不同的从节点同步速度不一样,主节点会为每个从节点都创建一个 replication buffer,它用于实时传输写命令,且大小是动态的,因为对于同步速度较慢的从服务器,需要更多的内存来缓存数据。
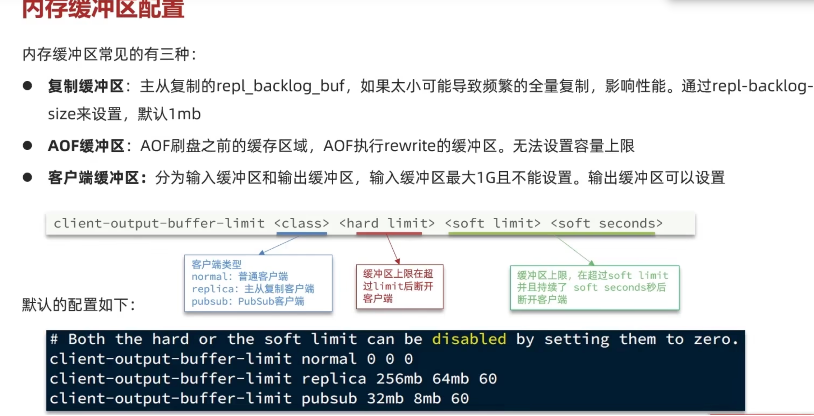
可以通过 client-output-buffer-limit 间接控制
client-output-buffer-limit slave 256mb 64mb 60
上述配置表示,如果从服务器的输出缓冲区大小超过 256 MB 且在 60 秒内未恢复到 64 MB 以下,Redis 将断开与从服务器的连接。
什么时候会做增量同步,什么时候会做全量同步?
- master 判断 salve 的 replId 与自己的不一致时,说明 salve 是第一次做数据同步,此时是全量同步
- repl_baklog 在底层是一个数组,在代码层面实现了循环数组(存数据和取数据时 % 数据长度 即可实现),因此 repl_baklog 写满之后会覆盖最早的数据。当 salve 断开太久,导致数据被覆盖了,此时只能做全量同步,不能做增量同步。(master 的 offset-salve 的 offset > 数据长度 则表示有数据被覆盖了)
- 不是第一次同步数据时就是增量同步,或者当 salve 断开的时间不是很久,没有数据被覆盖(master 的 offset-salve 的 offset <= 数据长度),则也是增量同步
主从集群的优化
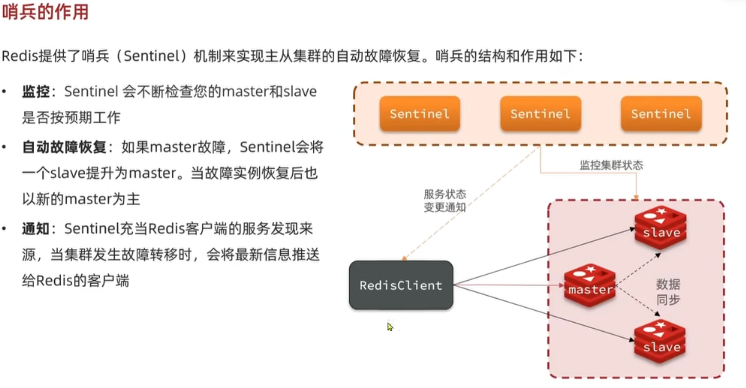
Sentinel(哨兵)
Sentinel 的作用
- **监控:**Sentinel 会不断检查您的 master 和 slave 是否按预期工作
- **自动故障恢复:**如何 master 故障,Sentinel 会将一个 slave 提升为 master。当原来的 master 恢复后,会作为新的 master 的 slave
- **通知:**Sentinel 充当 Redis 客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给 Redis 客户端
如何判断一个 Redis 实例是否健康
- 每隔一秒向 Redis 实例发送一次 ping 命令,如果超过一定时间没有响应则认为是主观下线(即该 Sentinel 认为这个 Redis 实例下线了)
- 如果大多数 Sentinel(这个数量称为
quorum,可以配置,建议配置为超过 2/N +1)都认为某个 Redis 实例主观下线,则判定为客观下线(即真的宕机了)
选举新的 master
发现 master 故障时,需要在 slave 中选择一个作为新的 master,选择依据是:
- 先判断 slave 节点与 master 节点时间长短,如果超过了指定值(down-after-milliseconds *10),则会排除该 slave 节点
- 再判断 slave 节点的 slave-priority,越小优先级越高(0 则表示永不参与选举)
- 若 slave-priority 一样,则判定 slave 节点的 offset 值,offset 越大说明数据越新(丢失的数据就越小)
- 若 offset 一致,则随便选一个 slave 即可,这里会选择 slave 的 id 更小的作为 master
故障转移的过程
当选中了其中一个 slave 作为新的 master 之后(假设为 slave1),故障转移的步骤如下:
- sentinel 给 slave1 节点发送
slave no one命令,让该节点成为 master - sentinel 给其他的 slave 发送
slaveof [host][port]命令,让这些 slave 成为新的 master 的从节点,开始从新 master 上同步数据。 - 最后,sentinel 将故障节点标记为新的 master 的 slave(修改其配置),当故障节点恢复后会自动成为新的 master 的 slave
docker-compose 搭建哨兵集群
yml
version: '3.8'
services:
redis-master:
image: redis:7.2.5
container_name: redis-master
ports:
- "7777:6379"
volumes:
- redis-master-data:/data
command: ["redis-server", "--appendonly", "yes"]
redis-slave1:
image: redis:7.2.5
container_name: redis-slave1
ports:
- "7778:6379"
depends_on:
- redis-master
volumes:
- redis-slave1-data:/data
command: ["redis-server", "--appendonly", "yes", "--slaveof", "redis-master", "6379"]
redis-slave2:
image: redis:7.2.5
container_name: redis-slave2
ports:
- "7779:6379"
depends_on:
- redis-master
volumes:
- redis-slave2-data:/data
command: ["redis-server", "--appendonly", "yes", "--slaveof", "redis-master", "6379"]
redis-sentinel1:
image: redis:7.2.5
depends_on:
- redis-master
- redis-slave1
- redis-slave2
container_name: redis-sentinel1
volumes:
- /Users/leftover/Desktop/redis_test/redis-sentinel.conf:/usr/local/etc/redis/sentinel.conf
ports:
- "27001:26379"
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
redis-sentinel2:
image: redis:7.2.5
container_name: redis-sentinel2
volumes:
- /Users/leftover/Desktop/redis_test/redis-sentinel.conf:/usr/local/etc/redis/sentinel.conf
depends_on:
- redis-master
- redis-slave1
- redis-slave2
ports:
- "27002:26379"
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
redis-sentinel3:
image: redis:7.2.5
container_name: redis-sentinel3
volumes:
- /Users/leftover/Desktop/redis_test/redis-sentinel.conf:/usr/local/etc/redis/sentinel.conf
depends_on:
- redis-master
- redis-slave1
- redis-slave2
ports:
- "27003:26379"
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
redis-master-data:
redis-slave1-data:
redis-slave2-data:yml
#/Users/leftover/Desktop/redis_test/redis-sentinel.conf
# bind 127.0.0.1 192.168.1.1
#
# protected-mode no
# port <sentinel-port>
# docker对外开放的端口
port 26379
# 让服务后台运行(因为使用docker启动时使用了-d参数,所以需要设置为no, 非docker设置为yes)
daemonize no
# When running daemonized, Redis Sentinel writes a pid file in
# /var/run/redis-sentinel.pid by default. You can specify a custom pid file
# location here.
pidfile /var/run/redis-sentinel.pid
# Specify the log file name. Also the empty string can be used to force
# Sentinel to log on the standard output. Note that if you use standard
# output for logging but daemonize, logs will be sent to /dev/null
logfile ""
# sentinel announce-ip <ip>
# sentinel announce-port <port>
# 这两个参数可以强制slave向master声明任意IP和端口对,docker内部网络与外部不同
# 基于docker所构建的redis集群在docker容器内是能够访问的,但是在容器外或者两个无关联的容器间,是无法访问的
# 使用这两个参数后,从节点发送给主节点的ip和端口信息就是在这里设定好了。
# sentinel announce-ip 1.2.3.4
# dir <working-directory>
# Every long running process should have a well-defined working directory.
# For Redis Sentinel to chdir to /tmp at startup is the simplest thing
# for the process to don't interfere with administrative tasks such as
# unmounting filesystems.
dir /tmp
sentinel resolve-hostnames yes
# 这里配置的是监控的redis的地址,mymaster为默认的主节点名字,后面的2为客观掉线的票数,一般为集群数除二
sentinel monitor mymaster redis-master 6379 2
# sentinel auth-pass <master-name> <password>
# sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# sentinel down-after-milliseconds <master-name> <milliseconds>
# Default is 30 seconds.
# 超过5秒master还没有连接上,则认为master已经停止,5000ms,默认30秒
sentinel down-after-milliseconds mymaster 5000
# aclfile /etc/redis/sentinel-users.acl
# requirepass <password>
# sentinel parallel-syncs <master-name> <numreplicas>
#
# How many replicas we can reconfigure to point to the new replica simultaneously
# during the failover. Use a low number if you use the replicas to serve query
# to avoid that all the replicas will be unreachable at about the same
# time while performing the synchronization with the master.
sentinel parallel-syncs mymaster 1
# sentinel failover-timeout <master-name> <milliseconds>
# 故障转移超时时间 默认3分钟
# Default is 3 minutes.
sentinel failover-timeout mymaster 180000分片集群
概述
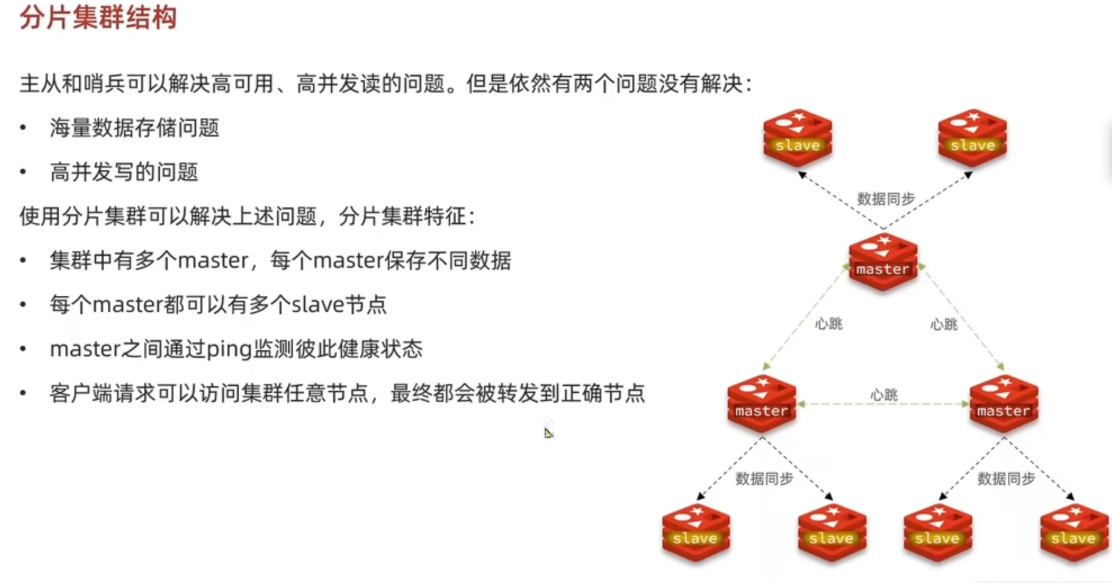
本地搭建分片集群
创建每个 redis 实例对应的配置文件 redis-cluster-[num].conf(一个 redis 实例对应一个配置文件)
ymlport 6001 # 开启集群功能 cluster-enabled yes # 集群的配置文件名称,不需要我们创建,由redis自己维护(自行修改) cluster-config-file /tmp/6001/nodes.conf # 节点心跳失败的超时时间 cluster-node-timeout 5000 # 持久化文件存放目录(自行修改) dir /tmp/6001 # 绑定地址 bind 0.0.0.0 # 让redis后台运行 daemonize no # 保护模式 protected-mode no # 数据库数量 databases 1 # 日志 (自行修改) logfile /tmp/6001/run.log创建每个 redis 实例对应的数据的存放文件夹
cd /tmp && mkdir 6001 6002 6003 6004 6005 6006启动这 6 个 redis 实例,
redis-server [配置文件的路径]之后运行下面的命令创建集群
shell
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006- redis-cli –cluster 代表集群操作命令 ,create 代表创建集群
- --cluster-replicas 是指每个 master 有多少个 slave 节点
- 这里前三个会成为 master,后三个为 slave
- 再执行
redis-cli -p 6002 cluster nodes查看集群状态
总结:先把所有的 redis 实例启动起来,需要设置--cluster-enabled 为yes,之后连接上一个集群,执行集群创建的命令即可
散列插槽

如何将同一类数据固定地保存在同一个 redis 实例?
这一类数据使用相同的有效部分,例如 key 都以{typeId}为前缀
集群伸缩
新增节点 以及重新分配插槽
- 起一个新的 redis 实例,
127.0.0.1:6007 - 将新的 redis 实例添加到集群中
redis-cli --cluster add-node 127.0.0.1:6007 127.0.0.1:6001(随便填写集群中的一个实例即可)(默认为 master),可以使用--cluster-slave --cluster-master-id <arg>设置为 slave,并且指定 master - 重新分配插槽到新的节点,
redis-cli --cluster reshard 127.0.0.1:6001(填写集群中的一个 redis 实例的 ip:port 即可,按提示操作)
删除节点
- 删除节点之前需要把该节点上的插槽转移到别的节点上
- 再删除节点,
redis-cli --cluster del-node 127.0.0.1:6007 node_id
故障转移
集群模式下默认支持故障转移,即当 master 宕机时,会选择一个 slave 作为新的 master
执行
cluster failover命令可以让当前节点成为 master,原来的 master 成为 slave(手动故障转移)cluster failover也可以用来做无感知的数据迁移(非常快就可以完成切换),即让新 redis 实例成为被迁移对象 slave,然后登录新的 redis 实例,执行cluster failover命令,这时候新的 redis 成为了 master,原来的 redis 则成为了 slave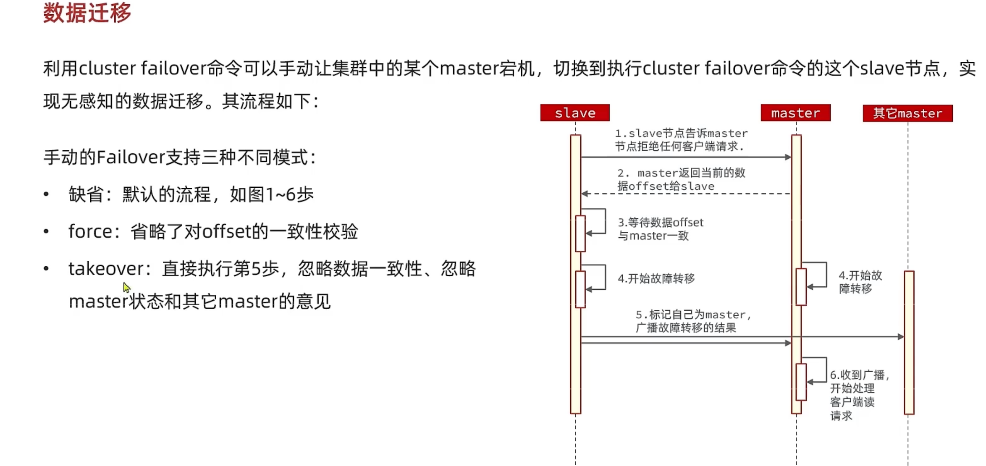
Java 使用分片集群
- 配置集群的 ip,port
yml
server:
port: 8081
spring:
data:
redis:
cluster:
nodes:
- 127.0.0.1:6001
- 127.0.0.1:6002
- 127.0.0.1:6003
- 127.0.0.1:6004
- 127.0.0.1:6005
- 127.0.0.1:6006代码中就和没使用分片集群一样,不需要变,需要注意分片集群的多键操作问题
分片集群的缺点
分片集群上不允许执行多键操作,因为不同的 key 会可能会放到不同的插槽中,当涉及到 mset,pipeline,transactions ,lua script 等多键操作时,以下是两种解决方法
- 不能使用多键操作、事务或涉及多个键的 Lua 脚本。键的访问是独立的(即使通过事务或 Lua 脚本将关于同一键的多个命令组合在一起进行访问)。
- 可以使用具有相同 哈希标记的键来使用涉及多个键的多键操作、事务或 Lua 脚本,这意味着一起使用的键都具有
{...}恰好相同的子字符串。例如,以下多键操作是在同一个哈希标记的上下文中定义的:SUNION {user:1000}.foo {user:1000}.bar,这时候就会被重定向到一个 redis 中
多级缓存
概述
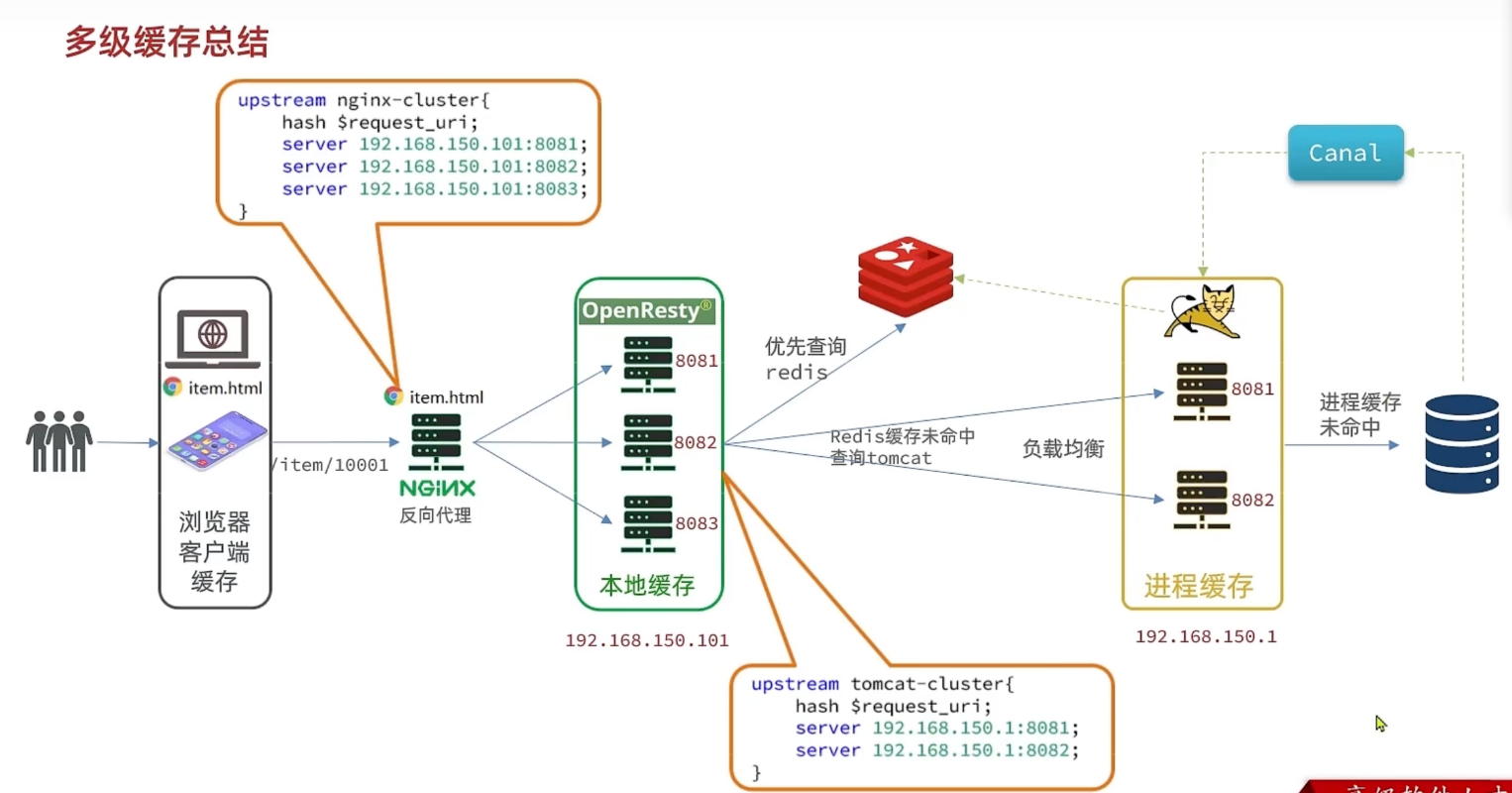
分布式缓存和进程缓存的区别

进程缓存
在 jvm 内部做的缓存,即使用代码编写缓存,这里可以采用caffeine工具来构建缓存,即在查询数据库时,会先判断是否存在缓存,不存在则查询数据库,再把数据写入缓存,存在则直接返回缓存数据
Nginx 本地缓存
使用(openresty)[https://openresty.org/cn/]实现
canal
Bigkey 问题
优雅地设置 key 结构
- 遵循基本的格式:[业务名称]:[数据名]:[id]
- 长度不超过 44B
- 不包含特殊字符,防止出现意外
这样做的优点:
- 可读性强
- 避免 key 的冲突
- 更节省内存:key 是 string 类型,底层编码包含 int、embstr 和 row 三种。在全是数字的情况下会采用 int 存储;embstr 在小于 44B 时使用,采用连续内存空间,内存占用更小;raw 在大于 44B 时使用
什么是 BigKey

BigKey 的危害

如何发现 BigKey
redis-cli –bigkeys
利用 redis-cli 提供的–bigkeys 参数,可以遍历分析所有 key,并返回 key 的整体统计信息与每种数据类型的 top1 的 bigkey
**缺点:**只能返回每种数据类型 top1 的 bigkey,且只有内存信息,没有长度信息
scan 扫描
自己编程,利用 scan 命令扫描 redis 中的所有 key,利用 strlen,hlen 等命令分析 key 的长度(不建议使用 memory usage,由于 redis 为单线程,此命令比较耗时,在 key 比较多的时候尽量不使用 memory usage)
利用第三方分析 rdb 的工具(由于分析的是 rdb,因此不会影响 redis 的运行,but 数据不是最新的,不过也能接受),例如redis-rdb-tools(很久没维护了,不推荐),redis-rdb-cli(推荐)(我这里使用的 redis 为 7.2.5,jdk 是 11,redis-rdb-cli 的版本为 0.9.5)(这里版本的问题比较大,redis、jdk、redis-rdb-cli 的版本都很关键)
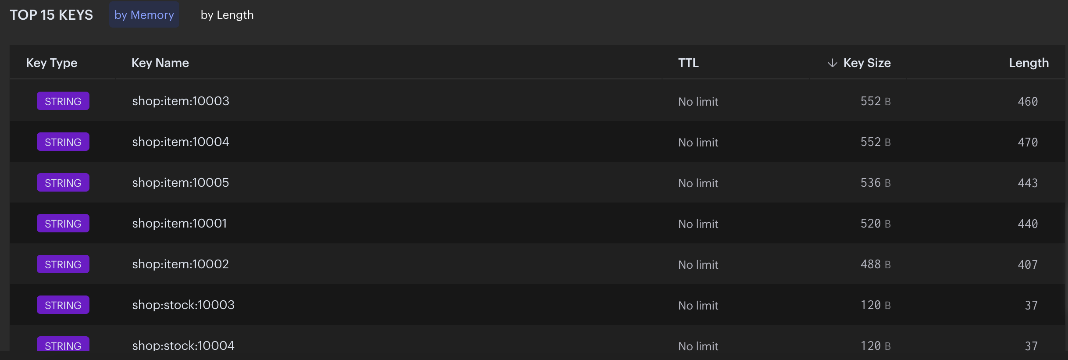
shell# 找到前50的key,并输出到对应的文件中 cd xxx/redis-rdb-cli/bin ./rct -f mem -s /opt/homebrew/var/db/redis-stack/dump.rdb -o /Users/leftover/Desktop/dump.mem -l 50 ## 输出结果类似这样子(个人觉得还是比较不错的,内存和长度都展示出来了) database,type,key,size_in_bytes,encoding,num_elements,len_largest_element,expiry 0,string,"shop:item:10001","512 B",string,1,"440 B","" 0,string,"age","48 B",string,1,"8 B","" 0,string,"shop:stock:10002","112 B",string,1,"39 B","" 0,string,"shop:item:10002","512 B",string,1,"407 B","" 0,string,"shop:stock:10004","112 B",string,1,"37 B","" 0,string,"shop:stock:10005","112 B",string,1,"39 B","" 0,string,"shop:item:10004","576 B",string,1,"470 B","" 0,string,"name","104 B",string,1,"45 B","" 0,string,"shop:stock:10003","112 B",string,1,"37 B",""如果你使用了云服务的 redis,则他们自带 bigkey 的分析的服务,可以很直观的看到 key 的内存占用以及长度
使用 redis 官方的redis-insight,可以下载 redis-stack(自带 redis-insight),也可以单独下载 redis-insight
如何解决 BigKey
- 删除 BigKey
- Redis 4.0 及之后版本:您可以通过UNLINK命令安全地删除大 Key 甚至特大 Key,该命令能够以非阻塞的方式,逐步地清理传入的 Key。
- Redis 4.0 之前的版本:建议先通过SCAN命令读取部分数据,然后进行删除,避免一次性删除大量 key 导致 Redis 阻塞。
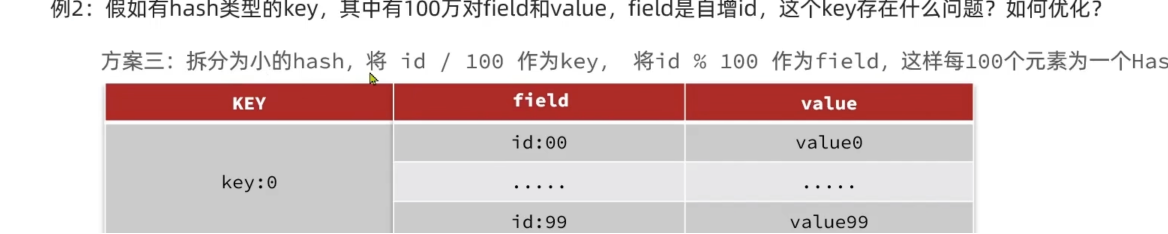
将一个 Big Key 拆分为多个 key-value 这样的小 Key,并确保每个 key 的成员数量或者大小在合理范围内,然后再进行存储,通过 get 不同的 key 或者使用 mget 批量获取。

使用监控工具及时发现大 Key,并设置告警通知。
在存入 redis 之前对数据进行压缩,取数据时解压缩(压缩和解压缩需要时间,耗费 cpu)
Transaction (事务)
事务相关的命令
- multi:开启一个事务
- exec:执行事务中的命令
- discard:取消事务,放弃事务中的所有命令
- watch:监控一个/多个 key,如果事务执行前,这些 key 被其他命令更改过,那么事务将终止(exec 会返回 nil,表示事务被打断了)
- unwatch:取消对所有 key 的监控(在 exec 调用时或者客户端断开连接,所有 key 都是 unwatched)
Redis 事务和数据库事务的区别
Redis 中开启一个事务之后,命令会被添加到一个队列中,当调用 exec 命令时,一依次执行队列中的所有命令,若有命令失败也不会终止,返回最后所有命令的执行结果
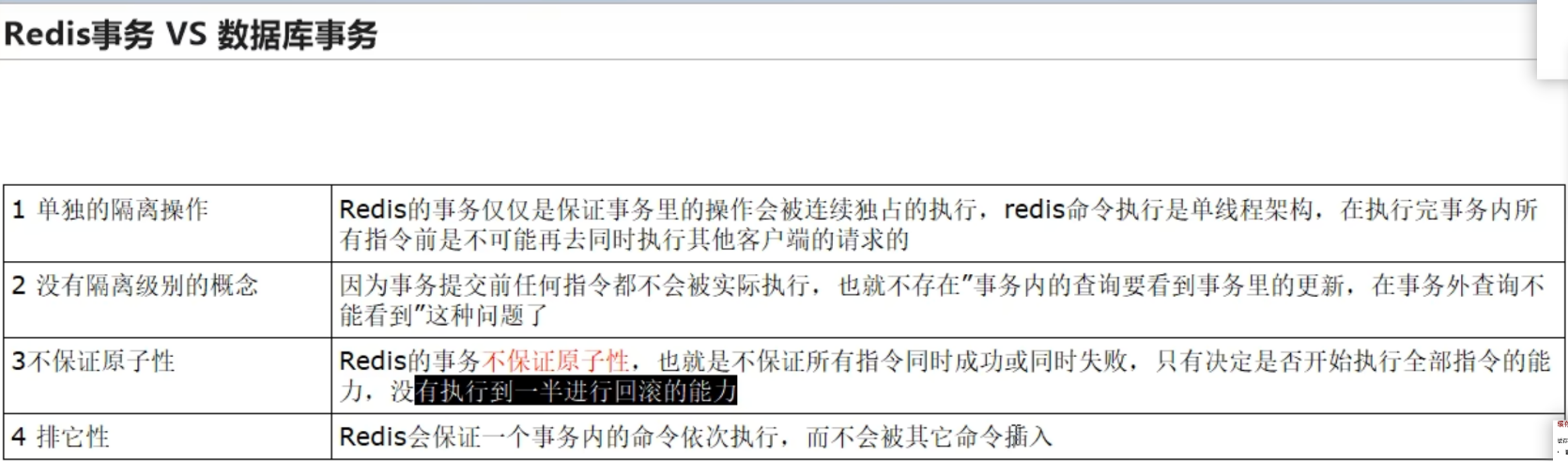
事务失败的场景
- 命令没有添加到 queue 时失败了(命令名称错误,命令参数错误,内存溢出了……),这时候会取消整个事务
- 执行 exec 之后,事务执行过程中出现了错误,其他命令会正常执行,不会回滚
watch 监控
watch 为 redis 事务提供了一种乐观锁的机制,即可以在事务之前监控某个 key,若事务 exec 之前,key 的内容被修改过,则事务将会被终止,返回 nil
shell
# 第一个客户端
127.0.0.1:6379> get balance
"100"
127.0.0.1:6379> WATCH balance
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> set balance 200
QUEUED
127.0.0.1:6379(TX)> set name hhh
QUEUED
# 另一个客户端
127.0.0.1:6379> set balance 300
OK
# 回到第一个客户端
127.0.0.1:6379(TX)> EXEC
(nil) # 事务被abort,exec命令return nil
127.0.0.1:6379> get name
"zwc" # 没有修改之前的值
127.0.0.1:6379> get balance
"300"lua 脚本和事务
lua 脚本也具有原子性,使用事务能做的事情,在 lua 脚本上也能做到,并且 lua 脚本更快、更简单
Pipeline
为什么使用 Pipeline?
当我们要执行大量的命令时,如果一条一条地向 redis 发送命令执行,这时候整体的执行时间约等于 网络传输的时间(redis 执行命令特别快,网络传输的时间远大于 redis 执行命令的时间),这时候就可以一次性发送多条命令给 redis(只需网络传输一次),这时候执行的时间就大大的缩短了。
也不要一次性发太多的命令,否则会占满带宽,导致网络拥堵
MSET,HSET,SADD,ZADD,LPUSH 等命令和 pipeline 的区别
HSET,SADD,ZADD,LPUSH 都只能向同一个 key 中添加元素
MSET,HSET,SADD,ZADD,LPUSH 命令是原子性的,redis 执行的一次性添加多个元素的
pipeline 则更灵活,可以执行不同的命令,向不同的 key 添加元素,但是 pipeline 多个命令之间不具备原子性
集群下的批处理

这里说一下图片中的第三种:并行slot,即将先在代码中计算出 key 对应的插槽,把相同插槽的 key-value 放一起执行。因为会分成很多组,这里可以开启多个线程向 redis 发送多个 mset 命令或者 pipeline,这样就可以达到并行执行各组命令的效果了.因此因此总耗时约为 1 次网络传输的时间+N 次执行命令的时间
spring-data-redis 的 multiSet 方法就是采用的这种实现
spring-redis-data 中使用 pipeline
Spring boot 下使用 Redis 管道(pipeline)进行批量操作
java
// stringRedisTemplate.executePipelined((RedisCallback<Object>) connection -> {
// for (int i = 0; i < 100000; i++) {
//
// connection.set(("user:key" + i).getBytes(StandardCharsets.UTF_8), "zwc".getBytes());
// }
// System.out.println(111);
// return null;
// });
stringRedisTemplate.executePipelined(new SessionCallback<Object>() {
@Override
public Object execute(RedisOperations operations) throws DataAccessException {
for (int i = 0; i < 100000; i++) {
operations.opsForValue().set("user:" + i, "zwc");
}
return null;
}
});Redis 服务端优化
持久化优化

慢查询优化
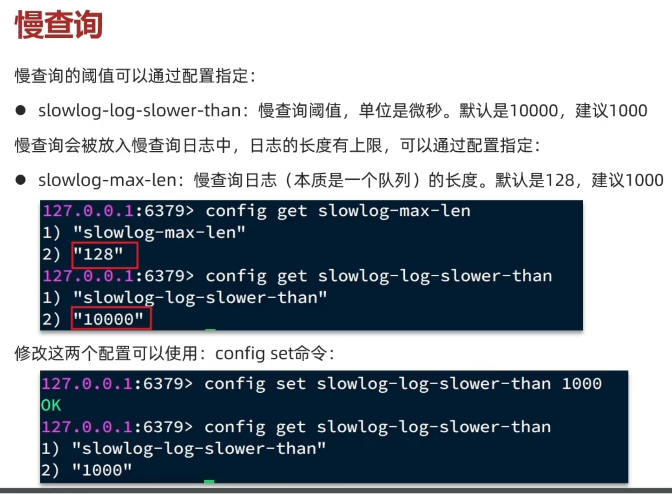
在 Redis 执行时耗时超过某个阈值的命令,称为慢查询
slowlog-log-slower-than: 慢查询阈值,单位 us,默认 10000,建议 1000,因为 Redis 非常快,一般一条命令 50us 左右就可以执行完
slowlog-max-len:设置慢查询日志(本质上是一个队列)的长度。默认是 128
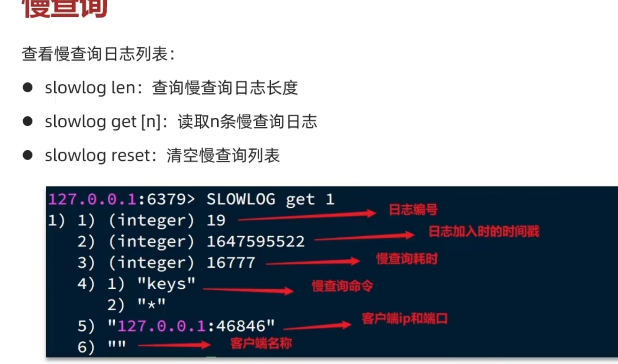
也可以使用Redis-Insight来查看慢查询的日志
命令与安全

内存安全和配置

查看 Redis 目前的内存分配状态
info memory
memory xxx(使用 help memory 来查看帮助)
选择分片集群还是主从
集群的问题
集群完整性问题
在 Redis 的默认配置中,如果发现任意一个插槽不可用,则整个集群都会对外停止服务。
举个例子:假设我们部署了一个集群 6 个节点,3 主 3 从,插槽是分配在这三个主节点上,当一个 master 以及它的从节点都挂了(由于从节点也挂了,所以不能故障转移了),这时候这个 master 上的插槽就不能用了,因此整个集群都会停止服务(即使其他 master 没宕机),这样子的话我们整个业务都崩掉了
我们可以通过修改
cluster-require-full-coverage为 no(默认 yes) ,来改变这个行为(即就算有插槽不能用了,也继续对外提供服务)。当然这样做有一个缺点,当我们代码中的有些 key 映射到了这些不可用的插槽上时,会报错。不过这样子至少可以保证部分服务可用集群带宽问题

客户端性能问题
由于用了集群,需要对 key 进行 hash,重定向等操作,性能会低一点
lua 脚本,事务,pipeline 等多键操作的问题
建议
单体 Redis(主从 Redis)已经能达到万级别的 QPS,并且也具备很强的高可用性。因此如果主从能满足业务需求的情况下,尽量不搭建 Redis 集群
Redis 数据结构原理
简单动态字符串(Simple Dynamic String)SDS

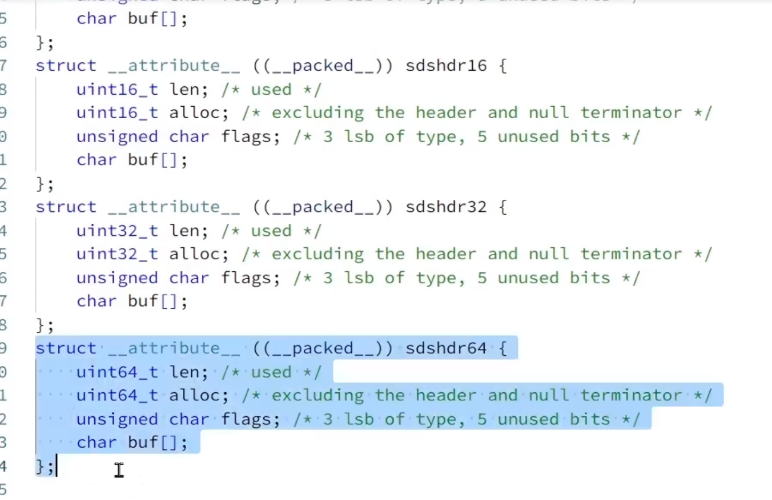
SDS 是一个结构体:

len:字符串数组的长度(单位 Byte)
alloc: 当前字符串总共申请的字节数(因为有 SDS 中有一个内存预分配的策略,因此申请字节数长度会比真正需要的字节数大)
flags:标记不同 SDS 的头类型,用来控制 SDS 头大小(为了节省空间,redis 会根据字符串的长度不同,会采用不同类型的 SDS)
以下是其中一些:支持字符串长度为 2^5(已弃用)(flag=0), 字符串长度为 2^8 (flag=1), 字符串长度为 2^16 (flag=2), 字符串长度为 2^32 (flag=3), 字符串长度为 2^64(flag=4) 来适应存储的长度的字符串
内存预分配

为什么是二进制安全呢?c 语言中默认字符串结束的标识是
\0,因此如果采用 c 语言中的这中方式,那我们就不能存储\0,所以 c 语言中的字符串是非二进制安全的;而 Redis 是根据结构体中 len 字段来获取字符串的内容的,不是根据\0来判断字符串的结束,所以是二进制安全的(可以存储\0)对于二进制安全,可以阅读什么,你还不懂 Redis 二进制安全吗?
IntSet
IntSet 是 Redis 中 set 集合的一种实现方式,基于整数数组来实现,并且具备
长度可变,元素唯一,有序等特征。具备类型升级机制,可以节省内存空间(根据数组中最大的元素的大小来决定使用哪种 encoding)
底层采用的是二分查找的方式来查询元素是否存在以及元素应该插入的位置

- encoding : 数组的编码方式,即每个元素占多少个 Byte,有三种:16 位(2B),32 位(4B),64 位(8B)
- length:数组的长度
- contents 是真正存储元素的地方,
int8_t contents[]并不代表数组的每个元素占 1B,数组元素的真正大小由 encoding 来维护
- IntSet 的类型升级

说明:只有当新添加的元素 > 数组中的所有元素 或者 当新添加的元素 < 数组中的所有元素 时,才可能触发 IntSet 升级,由于元素可能为负数,所以新元素可能添加到数组开头或者末尾
Dict
Dict 由三部分组成:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)
DictHashTable 的数据结构:
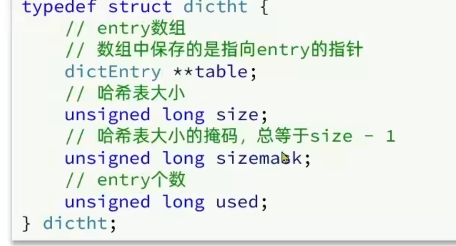
size: 哈希表的大小(即数组长度,总是为 2^n)
sizemask:哈希表大小的掩码(size-1)
和 jdk 的 hashMap 类似,要储存的数组的位置 = 将要储存的字段进行 hash 得到的结果 & sizemask,因此 size 必须为 2^n
used: entry 的个数(entry 的个数和 ht 的长度无关,使用的是拉链法解决冲突,因此 used 可能 > size )
DictEntry 的数据结构:

v: 表示 value,使用的是 union 类型(即 value 的类型可以是[
指针、无符号64位整数、有符号64位整数、double类型]中的任意一个)next:使用拉链法解决冲突,next 指向下一个具有相同 hash bucket 的 entry
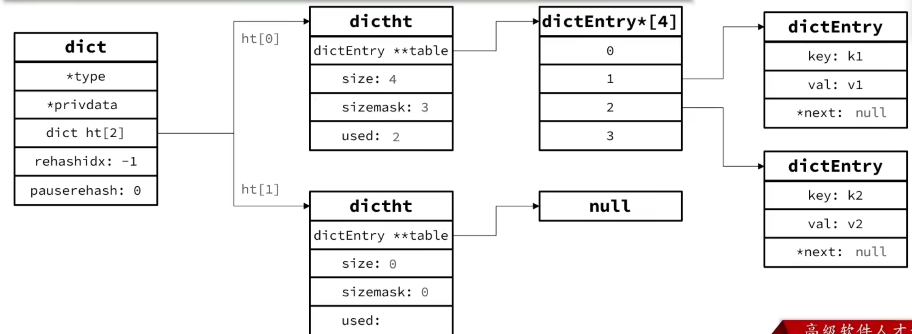
Dict 的数据结构

整个的结构:
Dict 的扩容
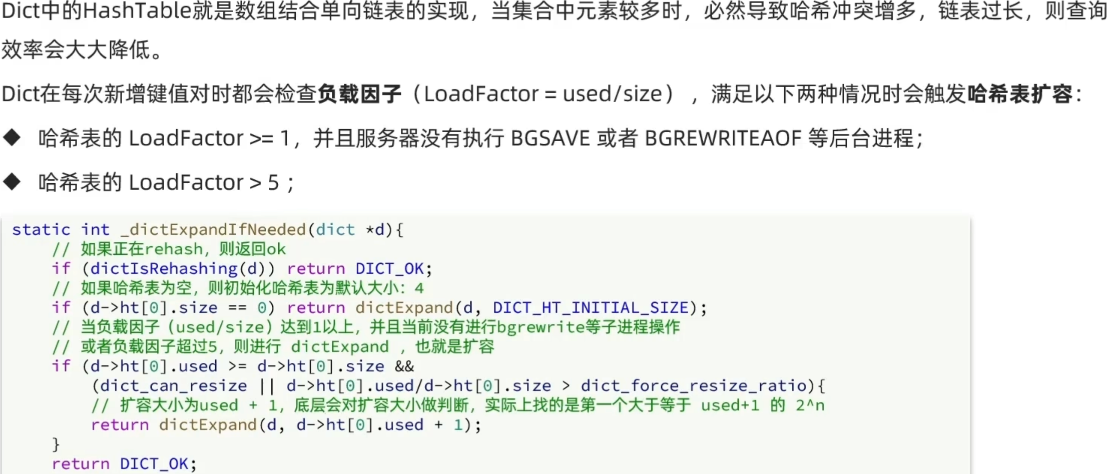
Dict 的收缩
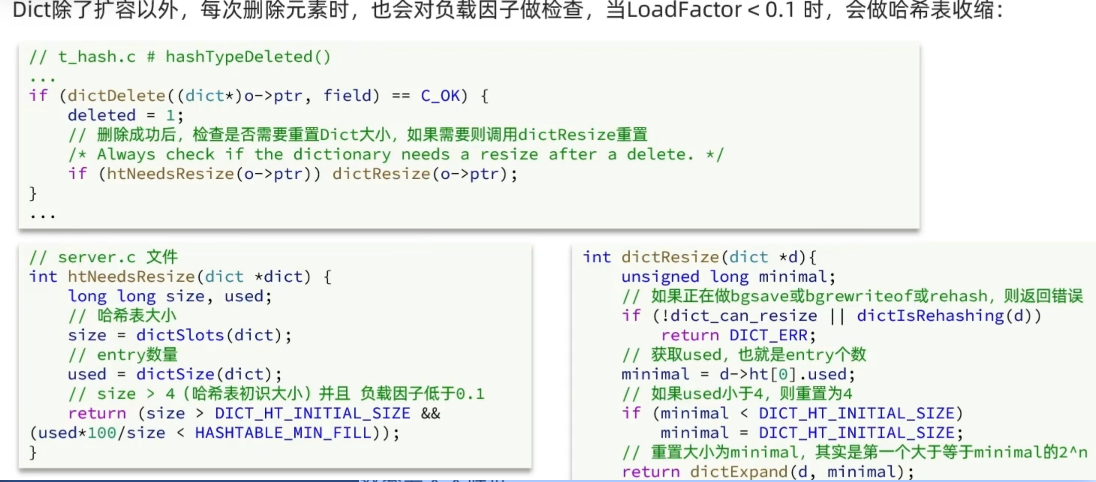
Dict 的渐进式 rehash


ZipList
- ZipList 是一种特殊的“双端链表”,由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作,时间复杂度位 O(1),由于 ziplist 的内存是连续的,因此 ziplist 的元素个数不能太多,否则不好申请大片连续的内存空间
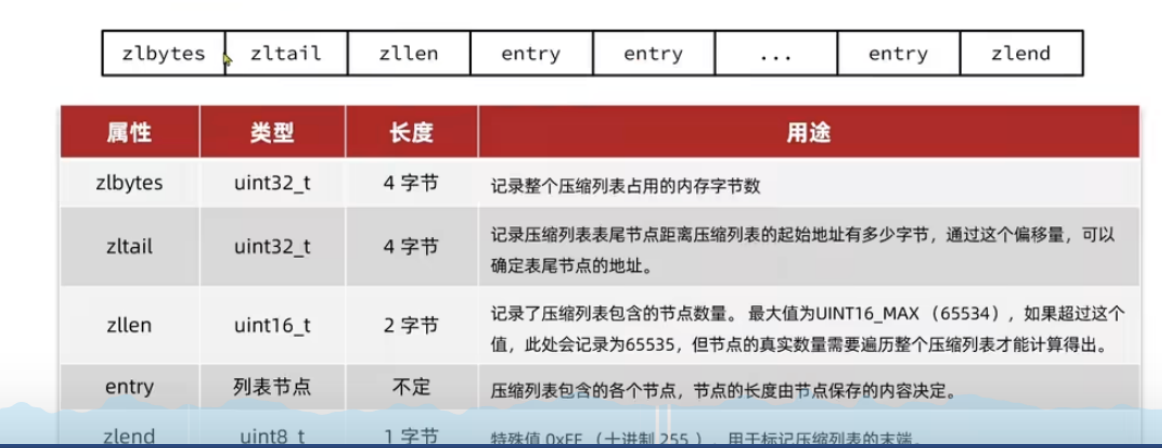
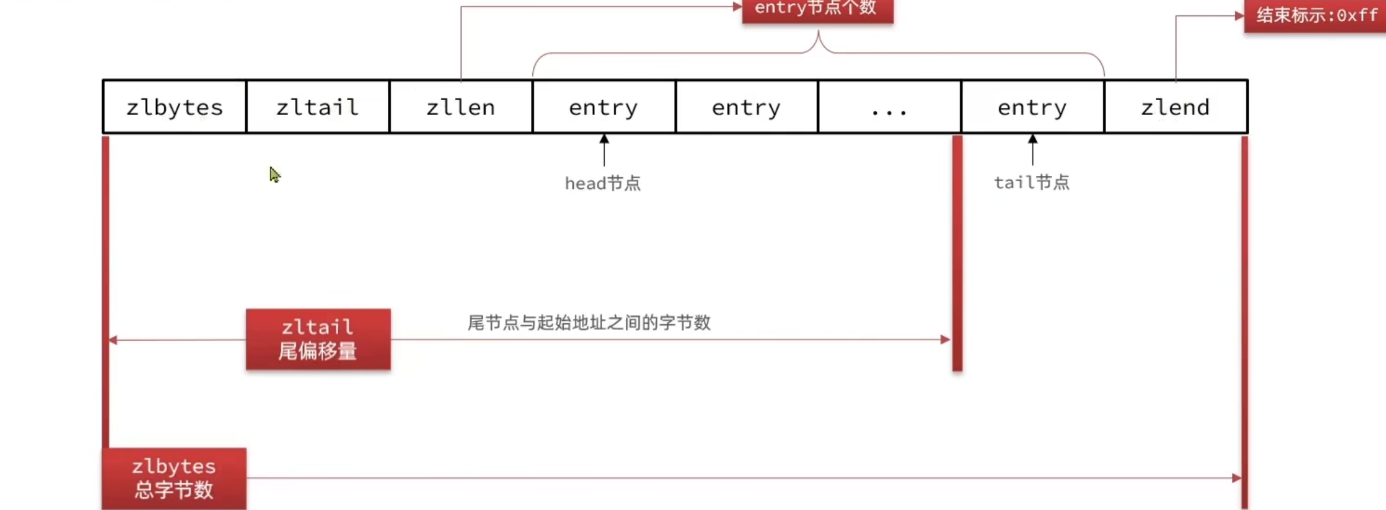
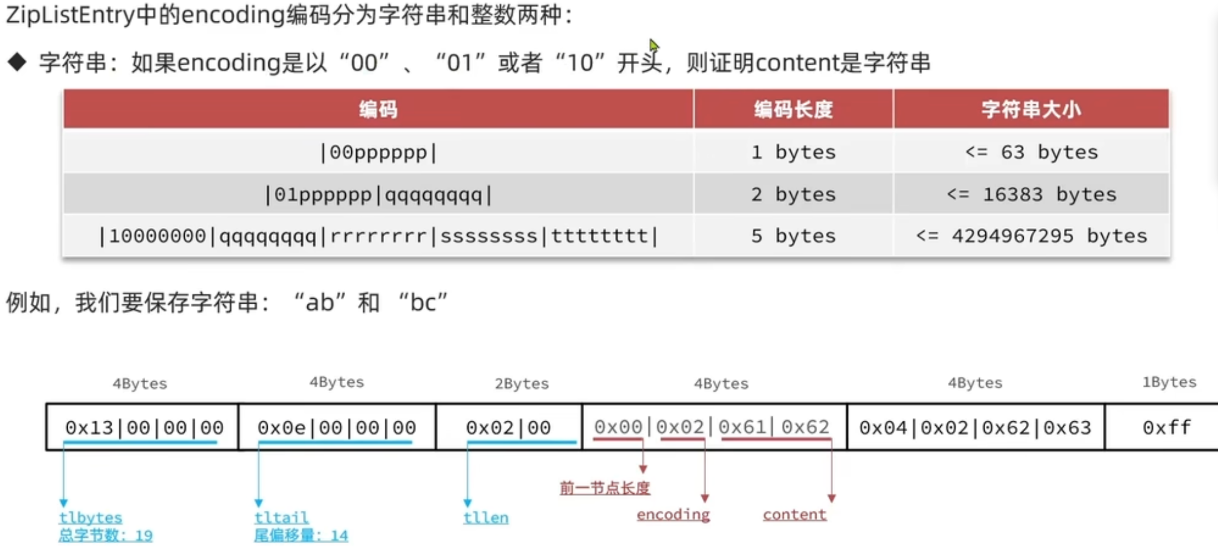
ZipListEntry

entry 中存储的是 string
entry 中存储的是整数
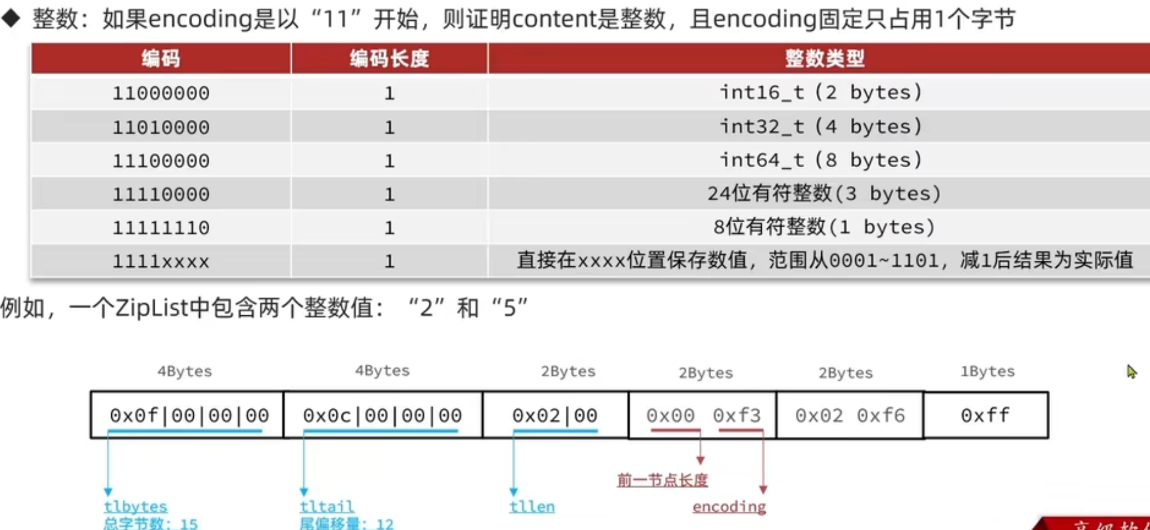
说明:当我们存储的数字为 0~12 时,这时候会把真正的内容存储在 encoding 中,content 字段中就不会存储内容了,这样节省了内存空间
就是上图的最后一种情况,由于 encoding 以 1111 开头的编码已经占用了 2 个,因此我们只能用 0001 - 1101 区间来存储 0-12(即 0 对应 0001,减 1 之后就是实际值)
ZipList 的特征:
- ziplist 可以看作是一种连续内存空间的“双向链表”
- 列表的节点不是通过指针连接,而是记录上一节点和本节点的长度来寻址,内存占用低
- 如果链表数据过多,会占用大片的连续内存空间,若查询链表中间的元素,需要耗费比较多的时间
- 增加/删除较大数据时,可能发生连锁更新问题
ZipList 的连锁更新问题
虽然概率比较小,但是还是可能会发生

Listpack
为什么需要 listpack,listpack 解决了什么问题?
Listpack 可以说是用来替代 ziplist 的,zipList 是一种特殊的双向链表(不使用指针来找到它前一个或者后一个元素),它的 entry 是使用 prebious_entry_length 记录前一个节点的长度,从而实现从后往前遍历,使用 encoding 来记录当前节点的数据类型和长度,从而知道当前节点的长度,实现从前往后遍历。因为使用prebious_entry_length 记录前一个节点的长度,因此它有连锁更新的问题
在 Listpack 中,每一个 entry 只记录自己的长度,因此在新增或者修改元素时,只会涉及当前 entry 的更新,而不会影响到别的 entry,从而避免了连锁更新
Listpack 的 entry 的结构

为了节省内存,有一些小的数字/字符串会直接存储在 encoding-type 中,不会使用 element-data 存储
encoding-type:变长的字段,其主要的作用就是记录数据的类型以及数据的长度,具体可以看官方文档
element-data:存储数据
element-tot-len:表示 entry 的大小(即 encoding-type 和 element-data 的长度),用于从后往前遍历。
该变量是可变长的,如果 entry 比较小,可能
element-tot-len只使用 1B,如果 entry 比较大,就会逐渐增加字节数该字段是从右往左解析的,例如 element-tot-len 为 0000011 1110100 ,则从最后面的 0 开始解析。
每个字节第一个 bit 表示是否结束,0 表示结束,1 表示没结束,因此只有 7bit 真正有用
例如需要存储长度为 500 的 entry,500 的二进制 111110100
因此 element-tot-len 为: 0000011 1110100
Listpack 如何进行遍历
从左往右遍历
根据encoding-type 可以知道 encoding-type 和 element-data 的总字节数,从而可以计算出 element-tot-len 的字节数,因此可以得到当前整个 entry 的字节数,从而找到下一个 entry
c
static inline uint32_t lpCurrentEncodedSizeUnsafe(unsigned char *p) {
if (LP_ENCODING_IS_7BIT_UINT(p[0])) return 1;
if (LP_ENCODING_IS_6BIT_STR(p[0])) return 1+LP_ENCODING_6BIT_STR_LEN(p);
if (LP_ENCODING_IS_13BIT_INT(p[0])) return 2;
if (LP_ENCODING_IS_16BIT_INT(p[0])) return 3;
if (LP_ENCODING_IS_24BIT_INT(p[0])) return 4;
if (LP_ENCODING_IS_32BIT_INT(p[0])) return 5;
if (LP_ENCODING_IS_64BIT_INT(p[0])) return 9;
if (LP_ENCODING_IS_12BIT_STR(p[0])) return 2+LP_ENCODING_12BIT_STR_LEN(p);
if (LP_ENCODING_IS_32BIT_STR(p[0])) return 5+LP_ENCODING_32BIT_STR_LEN(p);
if (p[0] == LP_EOF) return 1;
return 0;
}
unsigned char *lpSkip(unsigned char *p) {
// 计算出当前元素的encoding-type 和 element-data 的总字节数
unsigned long entrylen = lpCurrentEncodedSizeUnsafe(p);
// lpEncodeBacklen 函数是计算当前元素的 element-tot-len 的字节大小,1-5B
// 从而得到当前整个entry的总字节数
entrylen += lpEncodeBacklen(NULL,entrylen);
p += entrylen;
return p;
}
/* If 'p' points to an element of the listpack, calling lpNext() will return
* the pointer to the next element (the one on the right), or NULL if 'p'
* already pointed to the last element of the listpack. */
unsigned char *lpNext(unsigned char *lp, unsigned char *p) {
assert(p);
// 找到下一个元素
p = lpSkip(p);
// 做一些edge case 的判断
if (p[0] == LP_EOF) return NULL;
lpAssertValidEntry(lp, lpBytes(lp), p);
return p;
}从右往左遍历
我们通过对上一个元素的 element-tot-len 的每个字节,从而可以得到 element-tot-len 占用的字节数 以及根据 element-tot-len 的内容可以得到 encoding-type 和 element-data 的字节数,从而完成从右往左遍历
c
unsigned char *lpPrev(unsigned char *lp, unsigned char *p) {
assert(p);
if (p-lp == LP_HDR_SIZE) return NULL;
// 指向前一个entry的最后一个字节
p--;
// 从右往左遍历 element-tot-len ,计算出encoding-type 和 element-data 的总字节数
uint64_t prevlen = lpDecodeBacklen(p);
// lpEncodeBacklen 函数的作用是根据计算出的encoding-type 和 element-data 的总字节数得出 element-tot-len的字节数(1B-5B)
// 从而得到了前一个entry的总字节数
prevlen += lpEncodeBacklen(NULL,prevlen);
// 将指针移动到上一个元素的开头(因为最初的时候-1,因此这里要少减一个字节)
p -= prevlen-1;
lpAssertValidEntry(lp, lpBytes(lp), p);
return p;
}
static inline uint64_t lpDecodeBacklen(unsigned char *p) {
uint64_t val = 0;
uint64_t shift = 0;
do {
val |= (uint64_t)(p[0] & 127) << shift;
if (!(p[0] & 128)) break;
shift += 7;
p--;
if (shift > 28) return UINT64_MAX;
} while(1);
return val;
}
static inline unsigned long lpEncodeBacklen(unsigned char *buf, uint64_t l) {
if (l <= 127) {
if (buf) buf[0] = l;
return 1;
} else if (l < 16383) {
if (buf) {
buf[0] = l>>7;
buf[1] = (l&127)|128;
}
return 2;
} else if (l < 2097151) {
if (buf) {
buf[0] = l>>14;
buf[1] = ((l>>7)&127)|128;
buf[2] = (l&127)|128;
}
return 3;
} else if (l < 268435455) {
if (buf) {
buf[0] = l>>21;
buf[1] = ((l>>14)&127)|128;
buf[2] = ((l>>7)&127)|128;
buf[3] = (l&127)|128;
}
return 4;
} else {
if (buf) {
buf[0] = l>>28;
buf[1] = ((l>>21)&127)|128;
buf[2] = ((l>>14)&127)|128;
buf[3] = ((l>>7)&127)|128;
buf[4] = (l&127)|128;
}
return 5;
}
}巨人的肩膀
深入分析 redis 之 listpack,取代 ziplist?
QuickList
ZipList 虽然节省内存,但是必须申请连续的内存空间,因此不能存储大量的元素,而且 ZipList 有连锁更新的问题,影响性能。而 QuickList 就是解决这些问题而提出的一种新的数据结构
它是一个双端链表,不过链表的每一个节点都是一个 ZipList,因此 QuickList 可以存储大量的元素,虽然每个节点是 ZipList,也会有连锁更新问题,但是由于其元素较少,因此性能影响小。
压缩首尾节点
配置
list-compress-depth来设置(默认为 0,不压缩)
控制每个 ZipList 的大小
使用
list-max-ziplist-size(默认值为-2)来限制 ziplist 的大小
QuickList 和 quickListNode 的结构体

QuickList 的特点
- quickList 是一个节点为 ZipList 的双端链表
- 节点采用 ZipList,解决了传统链表内存占用比较大的问题
- 控制了 ZipList 的大小,解决连续内存空间申请效率的问题
- 中间节点可以压缩,进一步节省了内存
SkipList
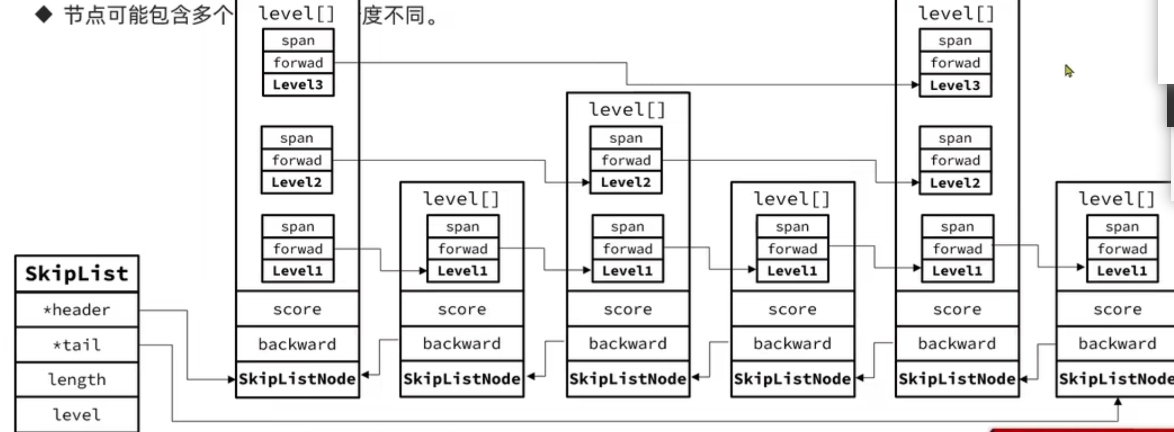
SkipList 首先是双向链表,与传统链表的差异:
元素按 score 升序排序
即一个节点可能包含多个指针(正向指针),指针跨度不同
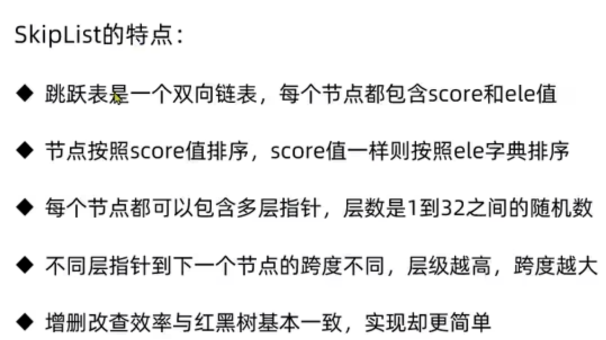
特点
skiplist 的结构体
c// 跳表node typedef struct zskiplistNode { sds ele; double score; // 指向后一个元素 struct zskiplistNode *backward; // 指向前面的元素,根据跨度的不同,指向的元素不同 struct zskiplistLevel { struct zskiplistNode *forward; unsigned long span; } level[]; } zskiplistNode; // 跳表 typedef struct zskiplist { struct zskiplistNode *header, *tail; unsigned long length; int level; } zskiplist;
RedisObject
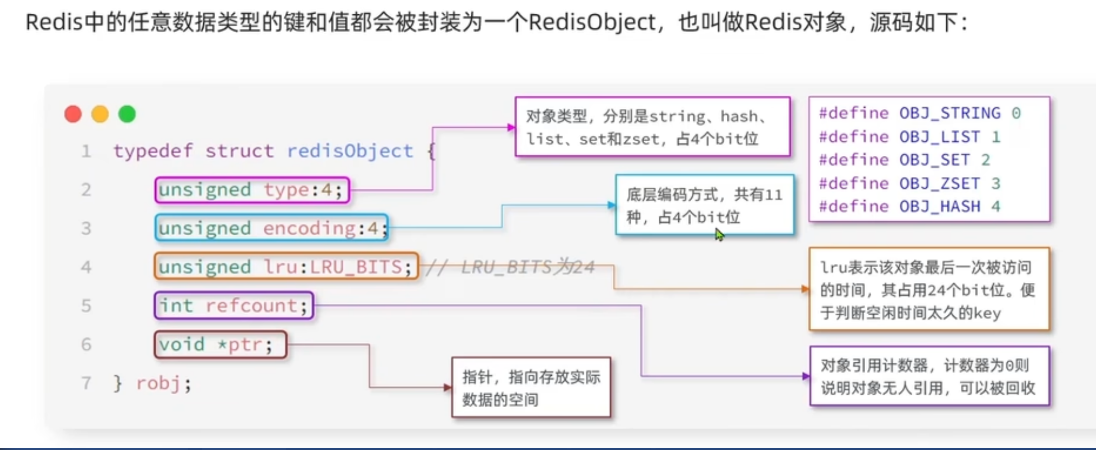
- type: 表示对象的类型(string,list,set,zset,hash),占 4bit
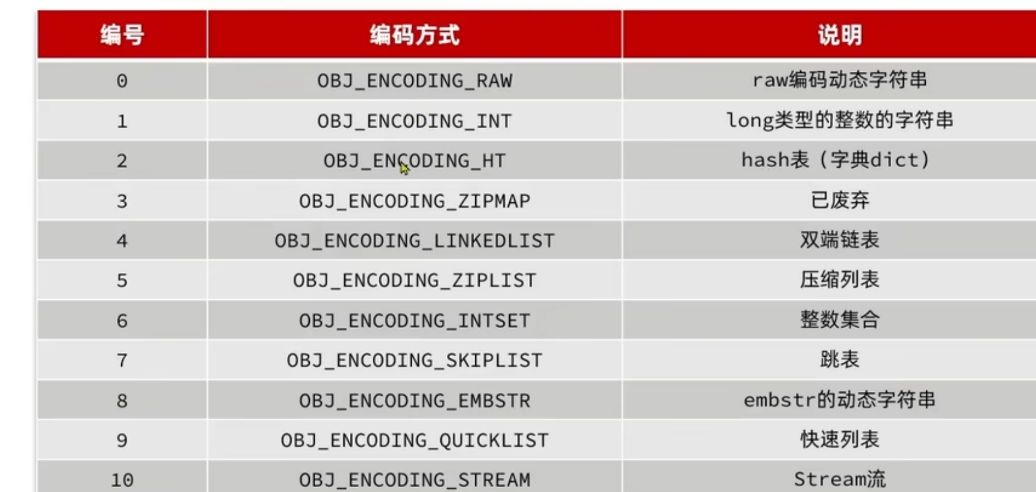
- encoding:表示底层编码方式(例如 skiplist,ziplist,ht,int,row,embstr……),占 4bit。 7.0 之后新增了 listpack
Redis5 种数据结构
string
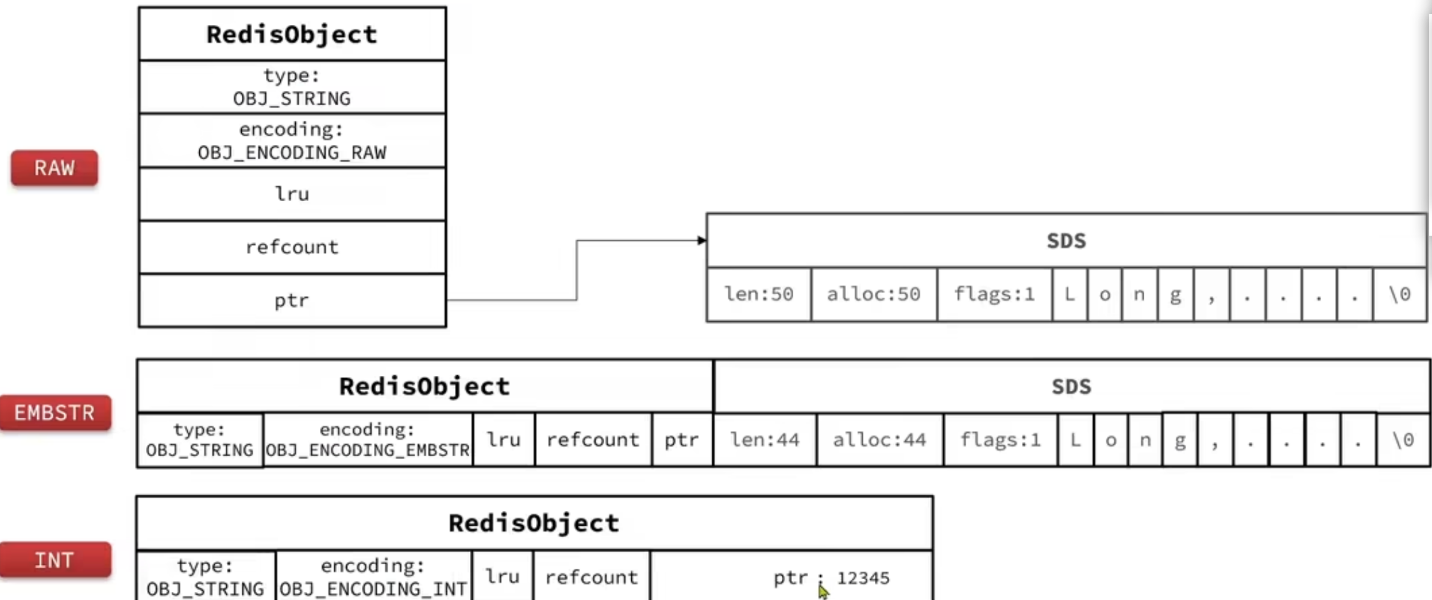
string 类型会根据不同的字符串长度,以及类型选择不同的编码类型。
- 存储的是数值型:若大小在 long 类型的范围内,则采用 int 编码方式;直接将数据保存在 RedisObject 的 ptr 指针位置(刚好 8B),不需要 SDS
- 长度<=44B:采用 embstr 编码,此时 RedisObject 的头部和 SDS 是连续的一段空间,申请内存时只需要调用一次内存分配函数
- 长度>44B: 采用 raw 方式编码,基于 sds 实现,存储上线为 512mb
三种编码方式的内存图
List
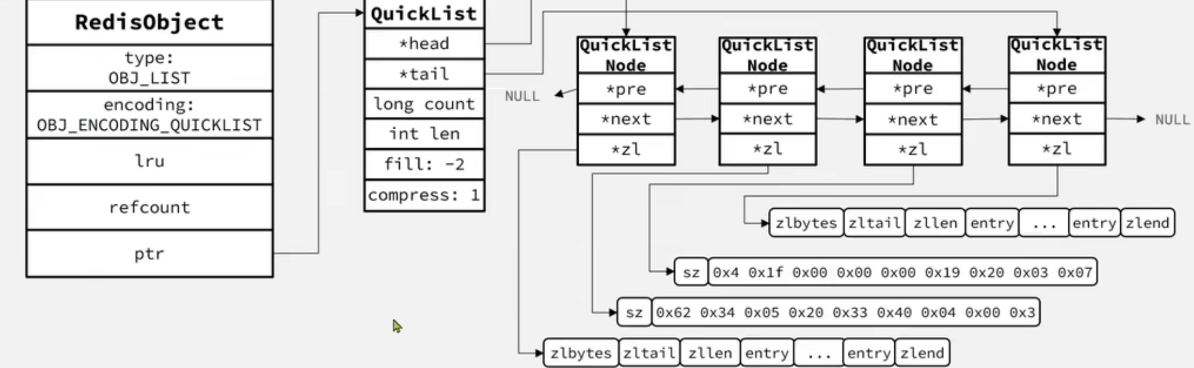
- Redis 的 list 结构类似一个双端链表,可以从首尾操作 list 中的元素。
3.2 版本之前,采用 ziplist+linkedList 来实现 list,当元素数量小于 512 且 元素大小均< 64B 时采用 ziplist 编码方式,超过则采用 LinkedList
3.2 版本之后,统一采用 QuickList 编码方式
7.x 之后,可以通过
list-max-listpack-size(默认-2)来设置单个 listpack 的元素数量/大小shell# -5: max size: 64 Kb # -4: max size: 32 Kb # -3: max size: 16 Kb # -2: max size: 8 Kb # -1: max size: 4 Kb # > 0 :表示元素的数量首先 list 会采用 listpack 的编码方式,当其不能采用单个 listpack 时(根据上面的配置决定),会转化为 quicklist(listpack+linkedlist),当 list 中的元素过少时,又会转化为 listpack
cvoid pushGenericCommand(client *c, int where, int xx) { int j; robj *lobj = lookupKeyWrite(c->db, c->argv[1]); if (checkType(c,lobj,OBJ_LIST)) return; if (!lobj) { if (xx) { addReply(c, shared.czero); return; } // 创建listpack lobj = createListListpackObject(); dbAdd(c->db,c->argv[1],lobj); } ... }
内存图(quicklist6.x 版本)
set
set 的特点是元素唯一,无序的,可以求交集、并集、差集
采用的编码方式:
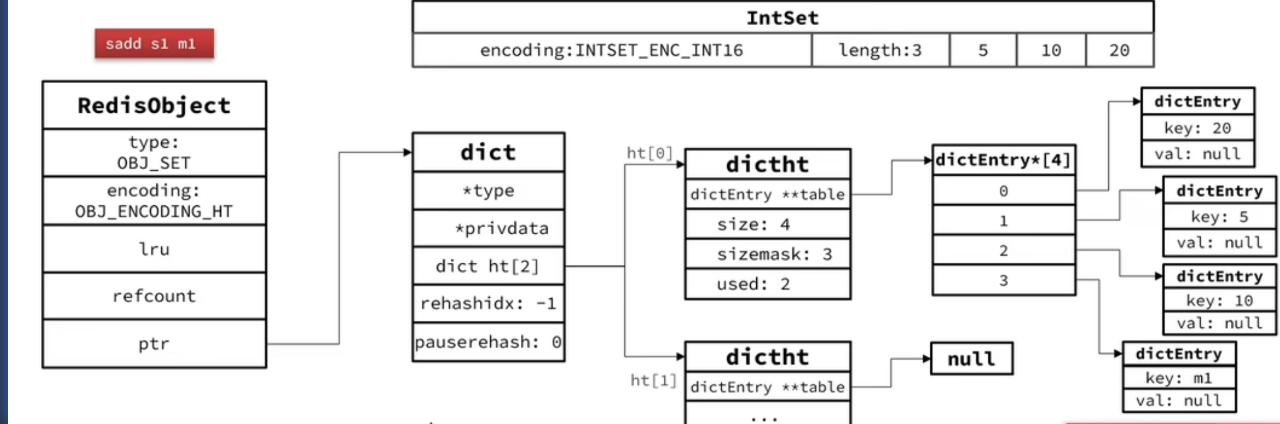
- 当 set 集合中存储的元素都是整数,并且元素数量<=
set-max-intset-entries(默认 512)时,set 会采用 intset 的编码方式,以节省内存空间 - 7.x 版本之后的版本,当元素的<=
set-max-listpack-entries(默认 128) 时,采用 listpack 的编码方式。7.x 之前则没有这个判断 - 否则采用 HT 编码方式(dict),dict 中的 key 用来存储元素,value 统一为 null。这里和 jdk 的 hashset 的设计方式类似
crobj *setTypeCreate(sds value, size_t size_hint) { // intset if (isSdsRepresentableAsLongLong(value,NULL) == C_OK && size_hint <= server.set_max_intset_entries) return createIntsetObject(); // listpack if (size_hint <= server.set_max_listpack_entries) return createSetListpackObject(); //ht robj *o = createSetObject(); dictExpand(o->ptr, size_hint); return o; }- 当 set 集合中存储的元素都是整数,并且元素数量<=
内存结构(7.x 之前)
zset
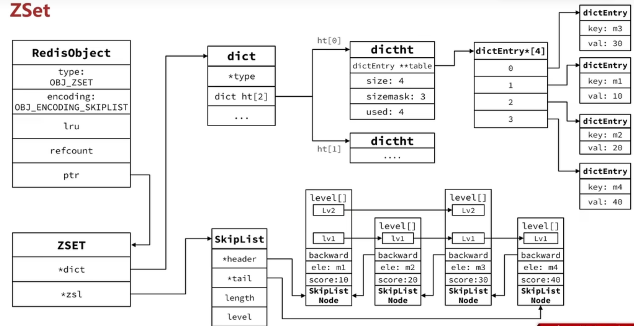
- zset 的特点
- 根据 score 排序
- member 唯一
- 可以根据 member 查询 score
- 在 7.x 之前,元素数量不多时,ht+skiplist 方案的优势不明显,而且更耗费内存。因此 zset 会采用ziplist 结构来节省内存;不过需要满足:
- 元素数量<=
zset-max-ziplist-entries,默认 128 - 每个元素都<=
zset-max-ziplist-value字节,默认 64B
- 元素数量<=
- 在 7.x 之后,元素数量不多时,ht+skiplist 方案的优势不明显,而且更耗费内存。因此 zset 会采用listpack 结构来节省内存;不过需要满足:
- 元素数量<=
zset-max-listpack-entries,默认 128 - 每个元素都<=
zset-max-listpack-value字节,默认 64B
- 元素数量<=
- 采用 ziplist 和 listpack 时,相邻的元素分别保存 key 、value
c
int zsetAdd(robj *zobj, double score, sds ele, int in_flags, int *out_flags, double *newscore) {
...
/* Update the sorted set according to its encoding. */
if (zobj->encoding == OBJ_ENCODING_LISTPACK) {
unsigned char *eptr;
//判断元素是否存在
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
//存在
...
return 1;
} else if (!xx) {
// 不存在
// 判断是否需要转化为skiplist+ht的模式
if (zzlLength(zobj->ptr)+1 > server.zset_max_listpack_entries ||
sdslen(ele) > server.zset_max_listpack_value ||
!lpSafeToAdd(zobj->ptr, sdslen(ele)))
{
// 转化为skiplsit+ht的方式
zsetConvertAndExpand(zobj, OBJ_ENCODING_SKIPLIST, zsetLength(zobj) + 1);
}
}
...
}c
robj *zsetTypeCreate(size_t size_hint, size_t val_len_hint) {
if (size_hint <= server.zset_max_listpack_entries &&
val_len_hint <= server.zset_max_listpack_value)
{
//创建为listpack
return createZsetListpackObject();
}
// 否则采用skiplist+ht
robj *zobj = createZsetObject();
zset *zs = zobj->ptr;
dictExpand(zs->dict, size_hint);
return zobj;
}c
robj *createZsetObject(void) {
zset *zs = zmalloc(sizeof(*zs));
robj *o;
// 创建ht
zs->dict = dictCreate(&zsetDictType);
// 创建skiplsit
zs->zsl = zslCreate();
o = createObject(OBJ_ZSET,zs);
o->encoding = OBJ_ENCODING_SKIPLIST;
return o;
}采用 ziplist 时的内存结构(7.x 之前)

采用 ht+skiplist 的内存结构(7.x 之前)
hash
7.x 之前,当数据量较小时,hash 结构会采用 ziplist 编码,以节省内存。ziplist 中相邻的两个 entry 分别保存 field 和 value
7.x 之后,当数据量较小时,hash 结构会采用 listpack 编码,以节省内存。listpack 中相邻的两个 entry 分别保存 field 和 value
数据量较大时,hash 结构会转为 ht 编码(dict),触发条件有 2 个:
- ziplist/listpack 的元素数量超过了
hash-max-ziplist-entries / hash-max-listpack-entries(默认 512) - ziplist/listpack 中任意 entry 的大小超过了
hash-max-ziplist-value / hash-max-listpack-value(默认 64B)
cvoid hashTypeTryConversion(robj *o, robj **argv, int start, int end) { int i; size_t sum = 0; if (o->encoding != OBJ_ENCODING_LISTPACK) return; size_t new_fields = (end - start + 1) / 2; // 超过了hash_max_listpack_entries, 转为ht if (new_fields > server.hash_max_listpack_entries) { hashTypeConvert(o, OBJ_ENCODING_HT); dictExpand(o->ptr, new_fields); return; } for (i = start; i <= end; i++) { if (!sdsEncodedObject(argv[i])) continue; size_t len = sdslen(argv[i]->ptr); // 任意元素超过了hash_max_listpack_value, 转为ht if (len > server.hash_max_listpack_value) { hashTypeConvert(o, OBJ_ENCODING_HT); return; } sum += len; } if (!lpSafeToAdd(o->ptr, sum)) hashTypeConvert(o, OBJ_ENCODING_HT); }- ziplist/listpack 的元素数量超过了
Redis 过期 Key 的处理
- Redis 数据库的结构
c
typedef struct redisDb {
// 储存所有的key,value
dict *dict; /* The keyspace for this DB */
// 只存储设置了过期时间的key,value,用来判断时间是否过期(dict中也会存储一份)
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
// 数据库id -- db0
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;Redis 中 TTL 记录方式:
通过
expiresdict 来记录每个 key 的过期时间,dict 的 value 就是过期的时间戳(ms)判断时间过期:通过当前时间的时间戳和对应过期时间的时间戳比较即可
过期 key 的删除策略:
- 惰性删除:每次查找 key 时判断是否过期,若过期则删除该 key
- 定期清理:定期抽样部分 key(20 个),判断是否过期,过期则删除
惰性删除
并不是在 TTL 到期后就立即删除,而是在访问一个 key 的时候,判断是否过期,如果过期了,则删除

周期删除
由于惰性删除是在访问 key 的时候删除,所以如果 Redis 中很多 key 过期了,但是之后也没有访问,这时候它就会一直保留在 Redis 中,浪费内存空间,因此引入了周期删除。实际中是二者结合起来一起使用


Redis 内存淘汰策略
Redis 的 8 种内存淘汰策略

c
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;unsigned lru:LRU_BITS 字段(24bit)就是做内存淘汰的;
- LRU:则保存最近一次访问的时间戳(s)
- LFU:高 16 位记录最近一次访问的时间戳(min),低 8 位记录逻辑访问次数,

因此,通过这个算法,即保证了 hotkey 不容易被删除,也具有良好的时间局部性
LRU 的内存淘汰策略
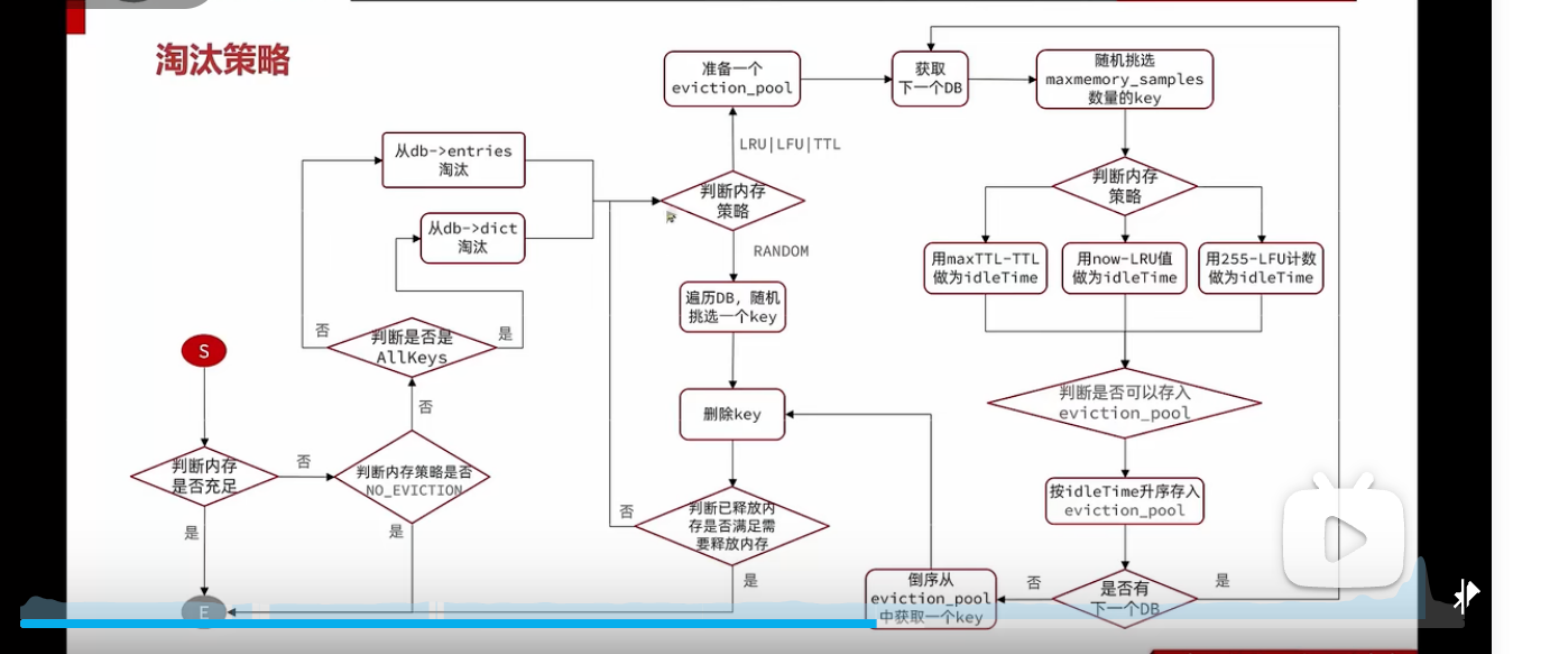
LRU 采用的是近似 LRU 的算法,跟常规的 LRU 算法还不太一样。他会准备一个准备淘汰的 key 的 pool(大小为 16),可以看作池中的数据根据访问时间排序(其实不是),访问时间小的优先淘汰。
每次会依次随机选取 5 个 key(maxmemory_samples配置,默认为 5),看 pool 是否满了,
满了,则判断当前的数据访问的时间是否比 pool 中最大的时间更小,
若是,移除 pool 中最大访问时间的 key,将新的 key 添加进来
若不是,则不添加进 pool
没满,直接放入 pool
内存淘汰的时候将 pool 中访问时间最小的 key 淘汰(将其删除)
LFU 内存淘汰策略
LFU 的内存淘汰策略和 LRU 类似,同样也是通过取样+evict_pool 的方式,只不过 LRU 是最近的访问根据时间来判断淘汰哪个 key,而 LFU 则根据lru字段的低 8 位的逻辑访问次数来判断淘汰哪个 key。(逻辑访问次数的计算参考上面的图片)
这里是为了理解,说的是通过
逻辑访问次数、lru最近访问时间来比较,其实最终都是转化为了 idle 来比较。LFU 策略的 idle=255-lfu 逻辑访问次数
LRU 策略的 idle=now-lru(当前时间戳-lru 的时间戳)
TTL 策略的 idle=maxTTL-TTL(maxTTL 为 long 的最大值)
淘汰策略的整个流程
文章作者:leftover
版权声明: 所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 leftover!