本站总访问量次
DDL,DML,DCL,TCL
作者:leftover
字数统计:5.6k 字
阅读时长:31 分钟
DDL (Data Definition Language) : 数据库定义语言,用于定义数据库的三级结构,包括外模式、概念模式、内模式及其相互之间的映像,定义数据的完整性、安全控制等约束 。DDL不需要commit.
DML(Data Manipulation Language):数据库操纵语言,主要是增删改 等等
DQL(Data Query Language):数据库查询语言 ,主要是数据库的查询
DCL(Data Control Language):数据库控制语言 授权,角色控制等
TCL(Transaction Control Language)事务控制语言
例如:
SAVEPOINT 设置保存点 ROLLBACK 回滚 SET TRANSACTION
select语句
between and
sql
SELECT * FROM customers WHERE birth_date BETWEEN '1990/01/01'AND '2000/01/01'between运算符包含左右两边的边界值
not Between and
NOT BETWEEN 运算符用于选择不在指定范围内的值。与 BETWEEN 运算符相对,NOT BETWEEN 运算符排除了边界值,即选择那些在指定范围之外的值。
like 操作符
like操作符用于搜索字符串,类似正则表达式
%表示任意多个字符
_表示任意一个字符
sql
SELECT * FROM customers WHERE address LIKE '%trail%' or address LIKE '%avenue%';
SELECT * FROM customers WHERE phone LIKE '%9';REGEXP(正则表达式)
sql
SELECT * FROM customers WHERE first_name REGEXP 'elka|ambur';
SELECT * from customers WHERE last_name REGEXP 'ey$|on$'; //以ey 或者on结尾
SELECT * FROM customers WHERE last_name REGEXP '^my|se'; -- lastname 以my 开头,或者包含se
SELECT * FROM customers WHERE last_name REGEXP 'B[RU]';ISNULL(exp)
sql
SELECT * FROM orders WHERE NOT ISNULL(shipper_id); //所有已发货的订单order by
DESC:降序
ASC:升序(默认)
sql
SELECT * FROM order_items WHERE order_id =2 ORDER BY quantity*unit_price DESC;
-- 上面的优化
SELECT * ,quantity*unit_price AS total_price FROM order_items WHERE order_id =2 ORDER BY total_price DESC;limit , offset
limit语句一定要放在sql语句的末尾
limit语法格式: limit startIndex, num
limit 3,4 (从下标为3开始,显示4条记录)(初始下标为0)
offset 语句可以用来做分页
sql
SELECT * FROM customers ORDER BY points DESC LIMIT 3 ; -- 找到积分最高的三位顾客
SELECT * FROM customers ORDER BY points DESC LIMIT 3 OFFSET 5; -- offset 偏移量, 跳过前5条记录,选择3条记录也可以只使用limit做分页
sql
SELECT * FROM student LIMIT 2,3; # 下标为2开始显示3条记录连接
Inner Join
Join 默认为(Inner Join)
sql
SELECT * FROM order_items AS oi JOIN products AS p ON oi.product_id = p.product_id;
-- 跨数据库连接表,只需要在表名前面加上数据库名即可,例如 sql_inventory.products
SELECT * FROM order_items oi JOIN sql_inventory.products p on oi.product_id = p.product_id;Self Join
多表连接
sql
SELECT o.order_id,o.order_date,c.first_name,c.last_name,os.`name`
FROM orders o
JOIN customers c JOIN order_statuses os
on o.customer_id=c.customer_id AND o.`status`=os.order_status_id;
--另一种连接方式
SELECT
c.client_id,
p.invoice_id,
p.date,
p.amount,
pm.name as payment_method
FROM sql_invoicing.payments p
JOIN sql_invoicing.clients c
ON p.client_id = c.client_id
JOIN sql_invoicing.payment_methods pm
ON p.payment_method =pm.payment_method_id;复合连接条件
sql
SELECT *
FROM order_items oi
JOIN order_item_notes oin
-- 使用多个条件进行连接
ON oi.order_id =oin.order_Id and oi.product_id = oin.product_id;外连接
左外连接: 它返回左侧表的所有记录以及右侧表中匹配的记录,如果在右侧表中没有找到匹配的记录,则结果集中对应的右侧表字段将包含NULL。
右外连接:与左外连接类似
sql
-- 左外连接
SELECT p.product_id , p.`name` , oi.quantity FROM products p LEFT JOIN order_items oi on p.product_id = oi.product_id;自外连接
sql
SELECT
e.employee_id,
e.first_name ,
m.first_name AS manager
FROM employees e
LEFT JOIN employees m
ON e.reports_to =m.employee_id;USING 子句
USING子句可以用来替换连接时 ON 的连接条件 , 例如ON p.client_id =c.client_id ,连接条件中字段名称都一样,这种的可以使用USING子句代替,看起来更加简洁 ,USING(client_id)
sql
SELECT
p.date,
c.`name` AS client,
i.payment_total AS amount,
pm.`name` AS payment_method
FROM payments p
JOIN clients c
-- ON p.client_id =c.client_id
USING(client_id)
JOIN invoices i
-- ON p.invoice_id = i.invoice_id
USING(invoice_id)
JOIN payment_methods pm
ON p.payment_method = pm.payment_method_id自然连接
自然连接中,数据库根据两个表中相同的字段名进行连接。(⚠️自然连接有点危险,有时候会出现出乎意料的结果,不太建议使用)
sql
-- 自然连接
SELECT
o.order_id,
c.first_name
FROM orders o
NATURAL JOIN customers c;交叉连接(笛卡尔积)
sql
-- 交叉连接(笛卡尔积)
-- 隐式的写法(不推荐)
SELECT
sh.`name` AS shipper,
p.product_id AS product
FROM shippers sh ,products p
-- 也可以这样
-- 显式的写法
SELECT
sh.`name` AS shipper,
p.product_id AS product
FROM shippers sh
CROSS JOIN products p;Union
Union可以用来合并多个查询结果(⚠️合并的查询结果的列数要相等,且最终结果的列名以第一个查询的列名为准)
sql
SELECT
c.customer_id,
c.first_name,
c.points,
"Bronze" AS type
FROM customers c
WHERE c.points<2000
UNION
SELECT
c.customer_id,
c.first_name,
c.points,
"Silver" AS type
FROM customers c
WHERE c.points BETWEEN 2000 AND 3000
UNION
SELECT
c.customer_id,
c.first_name,
c.points,
"GOld" AS type
FROM customers c
WHERE c.points >3000
ORDER BY first_name;插入
插入多行
sql
-- 插入多行
INSERT INTO products VALUES(DEFAULT, "zwc1",70,34.233),(DEFAULT , "zwc2",99,33.118);插入分层行
sql
INSERT INTO orders(customer_id,order_date,`status`) VALUES(9,"2024-01-01",1);
-- LAST_INSERT_ID()是mysql中的内置的函数,可以获取上次插入的id
INSERT INTO order_items VALUES (LAST_INSERT_ID(),2,4,1.56)创建表复制
sql
CREATE TABLE invoices_archived AS
SELECT
i.invoice_id,
i.number,
c.`name` AS client,
i.invoice_total,
i.payment_total,
i.invoice_date,
i.due_date,
i.payment_date
FROM invoices i
JOIN clients c
USING (client_id)
WHERE NOT ISNULL(payment_date);更新多行
sql
UPDATE customers
SET points =points+50
WHERE birth_date < "1990-01-01";在update中使用子查询
sql
UPDATE orders
SET
comments = "金牌客户"
WHERE customer_id IN (
SELECT
customer_id
FROM customers
WHERE points>3000
);聚合函数
sum , count ,avg ,max ,min
group by 分组
having 可以在分组之后添加限定条件
with rollup(mysql特有的一个语法) ,用于聚合函数,可以统计这一列所有行的总和
sqlSELECT pm.`name` AS payment_method, SUM(p.amount) AS total FROM payments p JOIN payment_methods pm ON p.payment_method =pm.payment_method_id GROUP BY pm.`name` with ROLLUP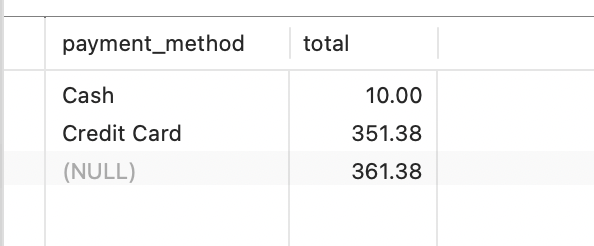
子查询
IN 运算符
sqlSELECT client_id FROM clients WHERE client_id NOT IN ( SELECT DISTINCT client_id FROM invoices )ALL 关键字
ALL关键字表示全部都满足才返回true
ALL 关键字总是可以和MAX函数相互替换
sqlSELECT * FROM invoices WHERE invoice_total > ( SELECT MAX(invoice_total) FROM invoices WHERE client_id =3 ) -- 等价于 SELECT * FROM invoices WHERE invoice_total > ALL( SELECT invoice_total FROM invoices WHERE client_id =3 )ANY/SOME:是任意一个 ,表示有任何一个满足就返回true
相关子查询
即子查询中使用到了外部查询的相关的值,如下
sqlSELECT * FROM employees e WHERE salary > ( SELECT AVG(salary) FROM employees ee WHERE e.office_id = ee.office_id )EXISTS
一般情况下Exists运算符和IN运算符可以相互转化,but当数据量很大的时候,EXISTS比IN更加地高效
如下:
使用EXISTS:对于下面的查询(这里使用了NOT),当子查询中如果
没有相关的结果时,那么这条记录将会被输出出来 使用IN:对于下面的查询,首先会查询出子查询的结果,然后外部的查询再根据IN操作符进行比较,⚠️当子查询的返回的表很大时,这时候效率比较低
sql-- 使用EXISTS SELECT * FROM products p WHERE NOT EXISTS ( SELECT * FROM order_items oi WHERE oi.product_id = p.product_id ) -- 使用IN SELECT * FROM products p WHERE p.product_id NOT IN ( SELECT product_id FROM order_items )
常见的工具函数
数值函数
abs,pow,floor,ceiling,rand() 随机生成0-1的浮点数,ROUND(1.2334343,2)四舍五入保留2位小数
字符串函数
length ,trim ,ltrim,rtirm,lower,upper,
left(“dahffaf”,4) 返回最前面4个字符
right(“dahffaf”,4) 返回最后面4个字符
substring(“hhfhhafh”,3,6) 从第三个字符开始,截取6个字符
locate(“afd”,“hgjhajgh”),查询子串在主串的位置(第一个参数为子串)(不区分大小写),若不存在,则返回0
replace("zwchjj","zwc","xixi"), 字符串替换(区分大小写)
CONCAT(str1,str2,...) , 连接多个字符串
日期函数
- NOW() 返回当前的系统时间(包含年月日时分秒)
- CURDATE()返回当前的日期(只包含年月日)
- CURTIME()返回当前的时间(只包含时分秒)
- MONTHNAME() 返回当前月份的名称,例如June
- DAYNAME(NOW()) 返回当前日期的名称,例如Monday
- EXTRACT(unit FROM date) 提取某个时间的某个单位,例如获取当前时间是第几月
EXTRACT(MONTH FROM NOW()),获取当前时间是哪一年:EXTRACT(YEAR FROM NOW())
时间格式化
- DATE_FORMAT(date,format) 格式化日期(年月日),例如
DATE_FORMAT(NOW(),"%Y-%m-%d")- 2024-06-05 - TIME_FORMAT(time,format) 格式化时间(时分秒),例如
TIME_FORMAT(NOW(),'%H:%i:%s %p')- 17:24:37 PM
计算时间和日期
计算日期
- DATE_ADD(date,INTERVAL expr unit) , 例如
DATE_ADD(NOW(), INTERVAL 1 DAY)在当前时间+1 天 - DATE_SUB(date,INTERVAL expr unit) , 例如
DATE_SUB(NOW(), INTERVAL 1 DAY)在当前时间 -1 天
计算时间
- TIMESTAMPADD(unit,interval,datetime_expr) ,加上多少时间,例如
TIMESTAMPADD(HOUR,1,CURTIME())当前时间+1hour
时间比较
TIMESTAMPDIFF(unit,datetime_expr1,datetime_expr2) ,比较两个时间相差多少天/秒/分。。。 例如下面,比较两个时间相差多少秒,后面-前面
sqlselect TIMESTAMPDIFF(SECOND,NOW(), DATE_ADD(NOW(),INTERVAL 1 DAY))与之相关的还有:
DATEDIFF(expr1,expr2) TIMEDIFF(expr1,expr2)
IFNULL 和 COALESCE 函数
COALESCE 是比IFNULL更加强大的函数,IFNULL可以完成的,COALESCE也可以
COALESCE 函数会返回括号中第一个不为null的值
sql
SELECT
CONCAT(first_name," ", last_name),
COALESCE(phone,state,"Unknow")
FROM customers- IFNULL 函数会判断当前值是否为null,若为null,则返回第二个值
sql
SELECT
CONCAT(first_name," ", last_name),
IFNULL(phone,"Unknow")
FROM customersIF 函数
IF(expr1,expr2,expr3) ,若第一个表达式为true,则返回第二个表达式的值,否则返回第三个表达式的值
sql
SELECT
p.product_id,
p.`name`,
COUNT(*) AS `orders`,
IF(
(COUNT(*)>1),
"Many Times",
"Once") AS frequency
FROM products p
JOIN order_items oi
USING(product_id)
GROUP BY product_idCase 运算符
如下:从上往下判断,符合某个条件就会返回对应的值
sql
SELECT
CONCAT(first_name," ",last_name),
points,
CASE
WHEN points >3000 THEN "Gold"
WHEN points BETWEEN 2000 AND 3000 THEN "Silver"
ELSE
"Bronze"
END AS category
FROM customers
ORDER BY points DESC视图
创建视图
sql
CREATE VIEW clients_balance AS
SELECT client_id, `name` , SUM(i.invoice_total-i.payment_total) AS balance
FROM clients c
JOIN invoices i USING(client_id)
GROUP BY client_id,`name`
ORDER BY balance DESC更改或者删除视图
创建或者更改视图(若无该视图则会创建,若存在则替换)
sqlCREATE OR REPLACE VIEW clients_balance AS SELECT client_id, `name` , SUM(i.invoice_total-i.payment_total) AS balance FROM clients c JOIN invoices i USING(client_id) GROUP BY client_id,`name` ORDER BY balance ASC删除视图
sqlDROP VIEW clients_balance
可更新视图
可更新视图:即我们可以在视图上执行update, insert(只能插入完整的一行,若缺了某些列则不行),delete语句
当我们创建视图的sql语句中没有使用
distinct、任何聚合函数、group by、having、union这些语句,则我们的视图称为可更新视图。在可更新视图上执行insert,update,delete语句,对应的表也会更新
WITH CHECK OPTION
当视图定义了某些过滤条件时,WITH CHECK OPTION 强制要求所有通过该视图进行的插入和更新操作都符合这些条件。它有效地阻止了违反视图定义的修改,并确保视图中的数据始终符合视图的条件。
WITH CHECK OPTION的类型
WITH CHECK OPTION:确保所有对视图的操作都符合视图的定义条件。WITH LOCAL CHECK OPTION:检查条件只应用于当前视图。WITH CASCADED CHECK OPTION:检查条件应用于当前视图和它的所有基础视图。这是默认行为。
作用
它主要用于:
数据一致性:防止通过视图插入或更新的数据与视图的条件不符。
操作控制:确保视图上的操作符合业务逻辑。
存储过程
创建存储过程
sql
CREATE PROCEDURE `get_invoices_with_balance`()
BEGIN
SELECT * FROM invoices_balance WHERE balance >0;
END删除存储过程
sql
DROP PROCEDURE IF EXISTS get_invoices_with_balance带参数的存储过程
sql
CREATE PROCEDURE get_invoices_by_client(
clientId int
)
BEGIN
SELECT *
FROM invoices i
WHERE i.client_id = clientId;
END;默认参数的存储过程
sql
CREATE or REPLACE PROCEDURE get_payments(
client_id INT,
payment_method_id TINYINT
)
BEGIN
SELECT *
FROM payments p
-- 使用IFNULL函数,如何第一个参数为null,则会使用第二个参数(可以达到设置默认参数的作用)
WHERE p.client_id = IFNULL(client_id,p.client_id)
AND p.payment_method_id = IFNULL(payment_method_id,p.payment_method_id);
END;对存储过程传入的参数进行检验
sql
CREATE PROCEDURE `update_invoices`(IN invoice_id int, IN payment_total decimal(9,2), IN payment_date date)
BEGIN
-- 使用if语句对传入的参数进行检验
IF payment_total < 0 THEN
SIGNAL SQLSTATE "22003";
END IF;
UPDATE invoices i SET
i.payment_total =payment_total,
i.payment_date = payment_date
WHERE i.invoice_id = invoice_id;
END输出参数
sql
CREATE PROCEDURE invoices_count_and_amount(
OUT invoices_count INT,
OUT amount DECIMAL(9,2)
)
BEGIN
SELECT count(*),sum(invoice_total)
# 将结果保存到输出参数中
INTO invoices_count,amount
FROM invoices;
END;变量
用户/会话级别的变量(在整个会话都生效)
使用
set定义,变量需要以@开头,使用的时候也要加上@sqlSET @invoices_count=0; SET @amount=0; SELECT @invoices_count,@amount;局部变量(只在存储过程或者函数中生效)
sql
BEGIN
-- 声明局部变量
DECLARE total DECIMAL(9,2) DEFAULT 0;
-- 使用set为局部变量赋值
SET total =1;
SELECT SUM(payment_total)
INTO total
FROM invoices i
WHERE i.client_id =client_id;
RETURN IFNULL(total,0);
END函数
函数与存储过程的区别
函数只能有一个返回值,存储过程可以有多个
sql
CREATE DEFINER=`root`@`localhost`
-- 函数名和入参
FUNCTION `getPaymentTotal`(client_id int)
-- 返回值类型
RETURNS decimal(9,2)
-- 函数具有的选项
READS SQL DATA
BEGIN
DECLARE total DECIMAL(9,2) DEFAULT 0;
SELECT SUM(payment_total)
INTO total
FROM invoices i
WHERE i.client_id =client_id;
RETURN IFNULL(total,0);
END指定函数或者存储过程sql的使用情况(优化sql)
具有的选项:
- DETERMINISTIC : 即函数具有确定性,每一次给相同的值,返回的结果都相同
- READS SQL DATA : 函数有读取sql的语句(即有查询语句)
- MODIFIES SQL DATA : 函数有修改sql数据(即函数里面会运行
增删改的sql) - NO SQL : 即函数中不包含sql语句
- CONTAINS SQL:表示函数中包含sql语句
SQL安全性
在 SQL 中,尤其是涉及存储过程、函数和视图的安全性配置时,INVOKER 和 DEFINER 角色控制了这些数据库对象在执行时的权限和上下文
- INVOKER : 以调用者的权限执行sql(谁调用这个函数,则执行函数中的sql时,使用的是调用者的权限)
(推荐) - DEFINER : 以定义者的权限执行sql(例如:谁定义的这个函数,当时候任何人执行这个函数都是使用定义者的权限)
sql
CREATE DEFINER=`root`@`localhost`
-- 函数名和入参
FUNCTION `getPaymentTotal`(client_id int)
-- 返回值类型
RETURNS decimal(9,2)
-- 执行sql的使用情况
READS SQL DATA
-- sql安全性
SQL SECURITY INVOKER
BEGIN
DECLARE total DECIMAL(9,2) DEFAULT 0;
SELECT SUM(payment_total)
INTO total
FROM invoices i
WHERE i.client_id =client_id;
RETURN IFNULL(total,0);
END触发器
创建触发器
sql
CREATE TRIGGER `payment_after_delete`
-- 触发时机
AFTER DELETE
-- 针对哪个表
ON `payments`
-- 对每一个修改的行都应用这个触发器
FOR EACH ROW
BEGIN
UPDATE invoices
SET payment_total =payment_total - OLD.amount
WHERE invoice_id = OLD.invoice_id;
END;删除触发器
sql
DROP TRIGGER IF EXISTS `payment_after_delete`;使用触发器进行审计
对每一个表建一个审计表
sql
DROP TABLE IF EXISTS `payments_audit`;
CREATE TABLE `payments_audit` (
`client_id` int NOT NULL,
`date` date DEFAULT NULL,
`amount` decimal(9,2) DEFAULT NULL,
`action_type` varchar(50) DEFAULT NULL,
`action_date` datetime NOT NULL,
PRIMARY KEY (`client_id`,`action_date`)
)触发器:
sql
BEGIN
UPDATE invoices
SET payment_total =payment_total - OLD.amount
WHERE invoice_id = OLD.invoice_id;
INSERT INTO payments_audit VALUES(OLD.client_id,OLD.date,OLD.amount,'Delete',NOW());
ENDEvent(事件)
创建event
sql
CREATE EVENT minutely_delete_payments_audit_rows
ON SCHEDULE
-- 每分钟触发一次
EVERY '1' MINUTE
DO
-- 执行sql
DELETE FROM payments_audit
WHERE date < DATE_SUB(NOW(),INTERVAL 1 YEAR);事务
开始事务
sql
START TRANSACTION;
UPDATE payments
SET amount=amount +10
WHERE payment_id =1;
COMMIT; -- ROLLBACK三大读问题
- 脏读:事务B开启了执行了update操作,but没有提交,此时事务A读取了事务B没有提交的数据。若此时这个未提交的数据rollback,则事务A读取的数据就是无效数据,即脏读。
- 不可重复读:事务A两次读操作,在两次读操作之间,事务B对某条记录进行了修改并提交。那么第二条读操作读取的同一个数据项的数据与第一条读操作不一样。即两个读操作在读取同一条记录时,数据项中的值发生了变化。
- 幻读:有事务A和B,事务B对某条记录进行了更改,but没有提交。此时事务A想读取这条记录,那么它读取的是事务B更新之前的数据,若此时事务B commit,那么此时事务A读取的数据就和数据库中的数据不一样了,即幻读。
四种隔离级别
读未提交(READ_UNCOMMITTED) :一个事务可以读取另一个事务未提交的数据。
读提交(READ_COMMITTED):一个事务职能读取已经提交的其他事务的数据
可重复读(REPEATABLE_READ):在同一个事务中多次读取同一数据,结果都是一致的
序列化(SERIALIZABLE):最高隔离级别,确保每个事务都完全不受其他事务的影响。它通过对事务进行序列化执行来避免脏读、不可重复读和幻读问题(即加锁,保证事务的串行执行),但是会降低并发性能。(数据在执行事务期间被别的事务修改了,那么事务会暂停,等待别的事务执行完成,获取最新的数据)
数据类型
字符串类型
- Char(x) : 固定长度
- varchar(x): 最大长度为 65535个字符(约为64kb)
- mediumtext: 最大长度为16mb
- longtext:最大长度4gb
- tinytext:最大长度255B
- text:最大长度64kb
数字类型
- tinyint: 1bit [-128,127]
- unsigned tinyint: [0,255]
- smallint: 2bit
- mediumint: 3bit
- int: 4bit
- bigint: 8bit
浮点数/定点数
decimal(p,s): delimal(9,2) = > 1234567.89
下面3个和decimal一样,别名罢了
dec
numeric
fixed
float: 4bit
double: 8bit
boolean
使用tinyint(1) 来定义boolean类型
插入
直接使用true/false插入就行,mysql会自动转为tinyint
sql
UPDATE products SET isPost = FALSE
WHERE product_id =2枚举类型
enum
⚠️ 不推荐使用枚举类型,推荐单独建一个表
二进制类型

Json
定义为json类型,我们可以单独读取json中的字段,单独设置json中的字段,单独移除json中的字段,单独修改json中的字段(若为varchar则不行)
单独读取某个字段


单独删除某个字段

单独新增/更新某个字段
下图更新了weight字段,新增age字段

索引
创建索引
为customers表的points列创建索引
sql
CREATE INDEX idx_points ON customers(points)分析sql语句的执行效率
前面加上EXPLAIN(用来分析sql的执行效率)
sql
EXPLAIN SELECT customer_id FROM customers WHERE points >1000查看某个表所有的索引
sql
-- 为某个表重新生成关于这个表的统计信息
ANALYZE TABLE customers
-- 展示这个表所有的索引
SHOW INDEX in customers前缀索引
前缀索引是一种特殊的索引,它只包含字符串字段(例如VARCHAR, TEXT)中值的前几个字符,而不是整个字符串。使用前缀索引可以在一些情况下减少索引所占的空间,从而提高索引创建和维护的效率,尤其是对于非常长的字符串字段。
sql
-- 创建前缀索引
CREATE INDEX idx_firstname ON customers(first_name(6))可以使用下面的方法来逐步确定前缀索引的长度
sql
SELECT
COUNT(*),
COUNT(DISTINCT LEFT(first_name,1)),
COUNT(DISTINCT LEFT(first_name,6)),
COUNT(DISTINCT LEFT(first_name,10))
FROM customers全文索引
全文索引一般用于全局搜索,例如搜索博客的文章
sql
-- 这里我们为title和body创建全文索引
CREATE FULLTEXT INDEX idx_title_body ON posts(title,body)全文搜索一般有2种模式: 一种为自然语言默认(默认),另一种为boolean模式
自然语言模式
sql
-- 默认按相关度从大到小排序
-- 这里搜索包含react或者redux的文章
SELECT *,MATCH(title,body) AGAINST ('react redux')FROM posts
WHERE MATCH(title,body) AGAINST ('react redux');boolean 模式
搜索的文章中一定要包含有Form关键字
sql
SELECT *,MATCH(title,body) AGAINST ('react redux +Form' IN boolean MODE )FROM posts
WHERE MATCH(title,body) AGAINST ('react redux +Form' IN boolean MODE);搜索的文章中包含redux,但是不包含recat
sql
SELECT *,MATCH(title,body) AGAINST ('-react redux' IN boolean MODE )FROM posts
WHERE MATCH(title,body) AGAINST ('-react redux' IN boolean MODE);在‘’中使用“”包裹,可以精确查询出包含某句话的博客,如下:查询出包含Handling a form的博客
sql
SELECT *,MATCH(title,body) AGAINST ('"Handling a form"' IN boolean MODE)FROM posts
WHERE MATCH(title,body) AGAINST ('"Handling a form"' IN boolean MODE);联合索引
- 复合索引:同时为多个列创建索引
sql
-- 为state和points创建索引
CREATE INDEX idx_state_points ON customers(state,points)联合索引创建时列的顺序:
频繁使用的列放在前面
将筛选性最高的列(即唯一值最多的列)放在索引的前面。(high cardinality)
联合索引的命中规则:
完全匹配查询
索引的列为state,points ,查询条件中也有state和points
匹配最左前缀
查询的时候首先判断索引的第一列有没有在查询条件中,在则命中索引,接着往后面匹配(匹配的越多,则命中的越多)
若索引的第一列没有在查询条件中,则不会进行后续的匹配,直接索引没命中(因此第一列很关键)
如果查询中的第有个条件是范围查询(如使用
>,<,BETWEEN,!=),则该索引仅对该列有效,对于索引中该列后面的列则无效。例如,在INDEX(idx_a_b) ON table_name(column_a, column_b)中,WHERE column_a > value1 AND column_b = value2只对column_a利用索引,而对column_b的筛选则不通过索引。
sql-- 命中了索引,因为查询条件中有state SELECT * FROM customers USE INDEX (idx_state_points) WHERE first_name LIKE 'A%' and state ='CA' -- 没有命中索引,因为查询条件中没state SELECT * FROM customers USE INDEX (idx_state_points) WHERE first_name LIKE 'A%' and points >1000索引失效的情况
- 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
- 尽量不使用or,可以改为union,这样可以提高索引的命中率
- 尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致或者查询列少于索引列)),减少select *
索引排序
使用orderBy的时候尽量使用索引的字段排序,且要保证顺序与复合索引一致
我们排序时不要序、降序混用,不然某些字段不会走索引,保证orderBy里面只有升序或者只有降序
sqlEXPLAIN SELECT points,state FROM customers ORDER BY state DESC ,points DESC
聚簇索引和非聚簇索引
聚簇索引:简单理解就是将数据和索引放到了一起,找到了索引索引即找到了数据(每个表只有一个聚簇索引)
mysql的Innodb是如何设置聚簇索引的:
- 若表中有主键,则会将主键设置为聚簇索引
- 若没有主键,则会选择第一个唯一的非空索引代替 ,即
Unique Index, 且所有列的约束条件都为NOT NULL - 若上述都不满足,则
InnoDB会创建一个隐藏的row_id列,并使用这个列生成一个名为GEN_CLUST_INDEX的索引
非聚簇索引:也叫二级索引(即我们自己创建的索引), 在Innodb中,二级索引的每个记录都包含
创建索引时的那些列的数据以及主键的值对于聚簇索引,其非叶子节点上存储的是索引值,而叶子节点上存储的是整行记录。
对于非聚簇索引,其非叶子节点上存储的是索引值,而叶子节点上存储的是主键的值以及索引值。
聚簇索引和非聚簇索引的查询的区别,以及什么是回表:
若使用聚簇索引进行查询,由于其叶子结点上存储的是整行记录,所以我们可以很快地找到对应的数据
使用非聚簇索引进行查询时,由于其叶子结点存储的是主键值以及索引值,所以我们可以通过非聚簇索引找到对应的主键值,再使用主键值根据聚簇索引找到对应的行记录(这个过程就称为回表)
https://dev.mysql.com/doc/refman/8.0/en/innodb-index-types.html
https://juejin.cn/post/7372084329080635402?searchId=20240617010148F51FC6907BD41CE5A258#heading-1
覆盖索引
- "覆盖索引"(Covering Index)是一种特别的索引,它可以直接满足查询需求而无需访问数据表中的行。如果一个查询可以仅通过访问索引中的数据来获取其需要的所有列,那么这个索引就被称为覆盖索引。(因此我们不要使用*,
尽量保证只使用索引中的列,这意味着查询可以直接从索引中获取所有需要的数据,而无需访问表中的行) - 原因:和上述的非聚簇索引的查询数据的过程有关,因为非聚簇索引的叶子结点存储的是主键和索引值,正常情况下需要根据查找到的主键再根据聚簇索引找到对应的记录,但是如果我们select语句中的所有列都是索引中的列,那么此时就可以直接从非聚簇索引的叶子结点取出对应的值,而无需进行回表
优点:
- 可以减少回表的次数
- 回表可能会导致很多随机IO,因此也可以减少随机IO的次数
B+树索引和hash索引
B+树索引
非叶子结点存储索引值,叶子结点存储索引的数据和主键值(非聚簇索引)或者存储索引值和整行数据(聚簇索引)
由于B+树是有序的,因此B+树索引支持范围查询(>,=,>=,<=,between,**like(不以%开头) **),优化器可以使用B+树索引来加速OrderBy
可以查找以某个前缀开头的数据。
对于查找、插入和删除操作,其时间复杂度为
O(log n)。
hash索引
- 以K,V的形式存储数据,根据索引字段生成对应的hash值和指针,指针指向对应的链表(数据),使用拉链法解决冲突
- 不支持范围查询,只支持等值查询(== ,!= ,in)、不支持排序、和前缀匹配
- 由于hash是无序的,所以优化器不能够使用 hash 索引来加速 ORDER BY 操作
- 如果字段存在很多重复值的时候,会出现大量的哈希冲突,效率会降低(因此hash索引不能用在重复值比较多的字段上)
- hash索引也不支持多列联合索引的最左匹配原则
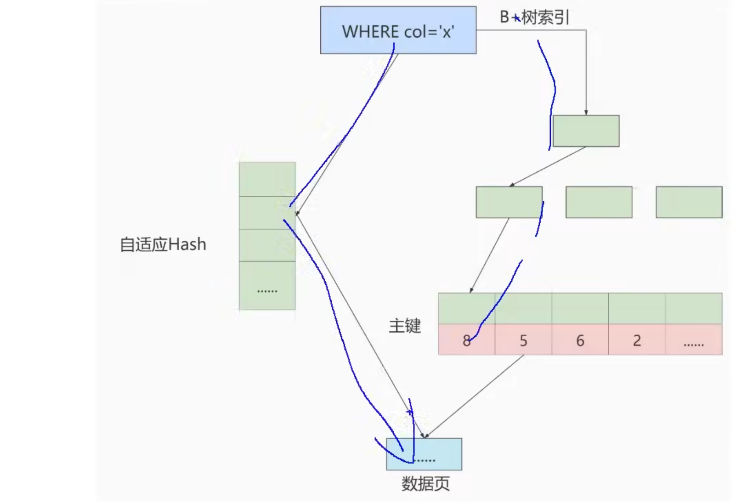
自适应hash索引
- Innodb不支持显式创建hash索引,只能显式创建B+树索引,但是Innodb引擎会持续监控表和索引的访问模式,当系统检测到某些页的访问频繁且模式稳定时,它会考虑创建自适应哈希索引。(例如:频繁的等值查询),则Innodb会自动建立自适应hash索引
在后续查询中,InnoDB 首先尝试使用哈希索引来查找数据。如果哈希表中存在对应的键,则可以直接访问数据页,跳过 B+ 树的遍历过程。这显著提高了查询性能。
- 命中哈希表: 如果键值存在于哈希表中,直接使用哈希索引访问数据页。
- 未命中哈希表: 如果键值不在哈希表中,仍然使用常规的
B+树索引访问数据。
InnoDB也会动态调整和删除自适应哈希索引。如果数据访问模式改变,或者哈希索引的命中率下降,它会自动删除这些无效的哈希索引。
- 访问模式改变: 如果数据访问模式发生变化,使得哈希索引不再有效,
InnoDB会自动移除这些索引。 - 内存限制: 在内存紧张时,
InnoDB也会移除一些不常用的哈希索引。
https://dev.mysql.com/doc/refman/8.0/en/index-btree-hash.html
索引下推(ICP,Index Condition Pushdown)
- 索引下推就是指在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数来提高查询效率。
- 使用下面的sql查询(对points和state字段创建了索引
idx_points_state)
sql
EXPLAIN
SELECT points,state,phone
FROM customers
force INDEX(idx_points_state)
WHERE points = 1000 and state like'%a' and first_name like '%b'对于这段查询中,points会走索引,state由于是以%开头,不会走索引。
- 不使用索引下推:因此mysql会根据索引找到points=1000的叶子结点,再根据叶子结点中的主键,再回表,判断这个数据项是否满足idx_points_state且
first_name like '%b',满足则保留,否则丢弃;再重复上述的过程,直到没有points=1000的叶子结点了
这里思考一个问题,由于我们是针对points和state字段建立的索引,所以我们找到points=10000的叶子结点(包含索引的值和主键值),那么这里既然包含了索引的值,说明此时我们可以知道points=10000的数据项中的state的值,因此我们可以先根据叶子结点中的state的值判断满足是否满足state like‘%A’,若不满足则丢弃,,若满足则回表找到对应的数据项,再判断是否满足first_name like '%b',满足则保留下来,不满足则丢弃。(这里可以看出来对于state字段的判断提前了,在回表之前进行了判断,这样可以很明显减少回表的次数)
- 使用索引下推:mysql先根据points=1000找到叶子结点,再根据叶子结点中的state的值进行判断是否满足
state like‘%A’,若满足则回表,不满足则找下一个points=1000的叶子结点。根据主键回表之后找到对应的数据项,判断是否满足first_name like '%b',满足则保留下来,否则丢弃
- 如果还不明白,建议读一下所给的参考文献的文章
https://dev.mysql.com/doc/refman/8.0/en/index-condition-pushdown-optimization.html
https://juejin.cn/post/7164973560660754469?searchId=202406171603387C2BD6EB68EB3637CA54
https://juejin.cn/post/7005794550862053412?searchId=202406171603387C2BD6EB68EB3637CA54
用户管理
创建用户
sql
-- 限定主机名/域名/ip ,密码1234
CREATE USER jhon@localhost IDENTIFIED BY '1234'
-- 不限定主机名等等,都可以连
CREATE USER tom IDENTIFIED BY '1234'
-- 可以从leftover.cn或者子域名连接mysql
CREATE user zwc@'%.leftover.cn' IDENTIFIED BY '1234'查询user
sql
SELECT * FROM mysql.`user`删除用户
sql
DROP USER jhon@localhost修改用户密码
sql
SET PASSWORD FOR zwc@'%.leftover.cn' = '123456'权限管理
mysql的所有权限https://dev.mysql.com/doc/refman/8.4/en/privileges-provided.html
添加权限
sql
-- 为zwc 用户添加 对数据库sql_store的所有表 增删改查的权限
GRANT SELECT ,INSERT ,DELETE ,UPDATE ON sql_store.* TO zwc@'%.leftover.cn'查询权限
sql
-- 查询用户zwc的权限
SHOW GRANTS FOR zwc@'%.leftover.cn'
-- 查询自己的权限
SHOW GRANTS删除权限
sql
-- 删除用户zwc的对所有数据所有表的show view的权限
GRANT SHOW VIEW ON *.* TO zwc@'%.leftover.cn'窗口函数
文章作者:leftover
版权声明: 所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 leftover!