本站总访问量次
自动映射
作者:leftover
字数统计:4.3k 字
阅读时长:28 分钟
字段映射
使用 @TableField注解对pojo类的属性映射到数据库的表字段
这里因为desc是mysql中的一个关键字,直接查询的话会报错,因此需要加上``
java
@TableField("`desc`")
private String desc;java
// 表示该字段不参与查询
@TableField(select = false)java
// 表示该字段在数据库中不存在
@TableField(exist = false)查询条件
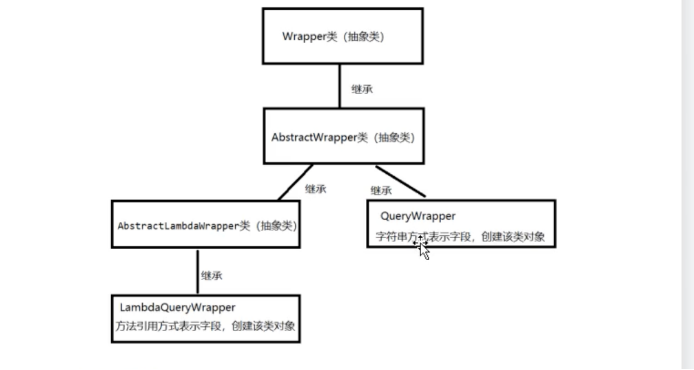
条件查询的基本使用
java
@Test
public void conditionalQuery() {
//QueryWrapper
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper = queryWrapper.eq("id", 1);
System.out.println(userMapper.selectOne(queryWrapper));
//LambdaQueryWrapper
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<User>().eq(User::getName, "Jack");
User user = userMapper.selectOne(lambdaQueryWrapper);
System.out.println(user);
}null的处理
java
String name = null;
// 这里当 name =null时,这个查询条件将不生效,即他会查询所有,若name!=null,则这个条件查询生效
LambdaQueryWrapper<User> lambdaQueryWrapper1 = new LambdaQueryWrapper<User>().eq(name != null, User::getName, name);
List<User> userList = userMapper.selectList(lambdaQueryWrapper1);
System.out.println(userList);多条件查询
java
HashMap<SFunction<User, ?>, Object> hashMap = new HashMap<>();
hashMap.put(User::getName, "Jack");
hashMap.put(User::getAge, null);
LambdaQueryWrapper<User> lambdaQueryWrapper2 = new LambdaQueryWrapper<>();
// 是否对null 做isNull对处理,若为false,则字段为null时,不会添加到查询条件中 ,若为true,则字段为null时,也会条添加到查询条件中
lambdaQueryWrapper2.allEq(hashMap, false);
List<User> userList1 = userMapper.selectList(lambdaQueryWrapper2);
System.out.println(userList1);常见的条件查询
eq:等于
ne:不等于
gt: >
ge:>=
le:<=
lt: <
between:在a和b之间(包含a,b)
notBetween:between的对立面
模糊查询
like
java
LambdaQueryWrapper<User> lambdaQueryWrapper4 = new LambdaQueryWrapper<>();
lambdaQueryWrapper4.like(User::getName, "J");
List<User> userList3 = userMapper.selectList(lambdaQueryWrapper4);
System.out.println(userList3);
// 对应的sql
//SELECT id,name,age,`desc` FROM user WHERE (name LIKE %J% )not like(like的对立面)
java
// 对应的sql
//SELECT id,name,age,`desc` FROM user WHERE (name NOT LIKE %J% )leftLike
sql
-- 对应的sql
SELECT id,name,age,`desc` FROM user WHERE (name LIKE %J )RightLike
sql
-- 对应的sql
SELECT id,name,age,`desc` FROM user WHERE (name LIKE J% )包含查询
in
java
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
ArrayList<Integer> arrayList = new ArrayList<>();
Collections.addAll(arrayList, 18, 19, 20);
lambdaQueryWrapper.in(User::getAge, arrayList);
userMapper.selectList(lambdaQueryWrapper);生成的sql
sql
==> Preparing: SELECT id,name,age,`desc` FROM user WHERE (age IN (?,?,?))
==> Parameters: 18(Integer), 19(Integer), 20(Integer)notIn
in的对立面,用法类似
inSql
即in里面可以传入sql语句,会直接拼接到后面
java
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.inSql(User::getAge, "select age from user where age >19");
userMapper.selectList(lambdaQueryWrapper);sql
-- 生成的sql
SELECT id,name,age,`desc` FROM user WHERE (age IN (select age from user where age >19))groupBy 和Having
java
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper
.select("id,age,count(*) as num")
.groupBy("age")
.having("num>={0}", 2);
List<User> userList = userMapper.selectList(queryWrapper);
System.out.println(userList);orderBy
java
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
// 先对年龄升序 ,再对id降序
lambdaQueryWrapper
.orderBy(true, true, User::getAge)
.orderBy(true, false, User::getId);
List<User> userList = userMapper.selectList(lambdaQueryWrapper);
System.out.println(userList);
// 对年龄和id降序
LambdaQueryWrapper<User> lambdaQueryWrapper1 = new LambdaQueryWrapper<>();
lambdaQueryWrapper1.orderByDesc(User::getAge,User::getId);
System.out.println(userMapper.selectList(lambdaQueryWrapper1));func
lambdaQueryWrapper.func() 方法可以更加灵活地添加查询条件
java
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
String name = null;
lambdaQueryWrapper.func(userLambdaQueryWrapper -> {
if (name != null) {
userLambdaQueryWrapper.eq(User::getAge, 20);
} else {
userLambdaQueryWrapper.eq(User::getAge, 18);
}
});
System.out.println(userMapper.selectList(lambdaQueryWrapper));and
java
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
// 默认多个连接查询条件使用and连接
lambdaQueryWrapper.eq(User::getName, "Jack").gt(User::getAge, 18);
System.out.println(userMapper.selectList(lambdaQueryWrapper));嵌套and
java
LambdaQueryWrapper<User> lambdaQueryWrapper1 = new LambdaQueryWrapper<>();
lambdaQueryWrapper1
.eq(User::getName, "Jack")
.and(userLambdaQueryWrapper -> userLambdaQueryWrapper.gt(User::getAge, 18).lt(User::getAge, 26));
System.out.println(userMapper.selectList(lambdaQueryWrapper1));or
普通地使用or
java
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.gt(User::getAge, 18).or().lt(User::getAge, 28);
System.out.println(userMapper.selectList(lambdaQueryWrapper));嵌套使用or
java
LambdaQueryWrapper<User> lambdaQueryWrapper1 = new LambdaQueryWrapper<>();
lambdaQueryWrapper1
.gt(User::getAge, 18)
.or(userLambdaQueryWrapper -> userLambdaQueryWrapper.gt(User::getId, 2).le(User::getId, 5));
System.out.println(userMapper.selectList(lambdaQueryWrapper1));nested
nested方法的作用是将某一组条件进行括号包围,以形成嵌套的逻辑条件,可以实现类似于SQL中的括号逻辑。
java
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
//生成的sql : SELECT id,name,age,`desc` FROM user WHERE (name = ? OR (age > ? AND age < ?))
lambdaQueryWrapper
.eq(User::getName,"Jack")
.or()
.nested(userLambdaQueryWrapper -> userLambdaQueryWrapper.gt(User::getAge,18).lt(User::getAge,29));
System.out.println(userMapper.selectList(lambdaQueryWrapper));apply
可以让我们以字符串的形式自定义查询条件,会直接拼接到where中
java
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.apply("age>{0}",18);
System.out.println(userMapper.selectList(lambdaQueryWrapper));last
会直接将字符串拼接到sql的最末尾,有sql注入的风险,谨慎使用
java
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.last("limit 1,2");
System.out.println(userMapper.selectList(lambdaQueryWrapper));Exists
对于每个外部查询的每一行,都会执行一遍内部的查询看一下有没有结果返回,若内部结果有值,则外部查询的这一行的结果会被保留下来
java
// 拼接出的sql : SELECT id,name,age,`desc` FROM user WHERE (EXISTS (select id from user where age =188))
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.exists("select id from user where age =188");
System.out.println(userMapper.selectList(lambdaQueryWrapper));select (选择查询部分字段)
使用queryWrapper.select可以选择查询部分字段
java
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// 只查询了 id,age,count(*)
queryWrapper
.select("id,age,count(*) as num")
.groupBy("age")
.having("num>={0}", 2);
List<User> userList = userMapper.selectList(queryWrapper);
System.out.println(userList);主键生成策略
- Auto: 使用主键自增,需要数据库设置主键自增
java
@TableId(type = IdType.AUTO)
private Long id; Input: 用户需要自己设置主键(若没有传ID,且数据库没有设置自增,则会报错,若设置了自增,则会自增)
ASSIGN_ID: 使用雪花算法生成主键(若自己有id,则使用自己的,没有则使用雪花算法生成)
NONE: 跟随全局的主键生成策略(可以自己设置),默认为ASSIGN_ID。
⚠️若全局的主键生成策略为none,则默认行为为input
yml
# 配置全局的主键生成策略
mybatis-plus:
global-config:
db-config:
id-type: assign_id ASSIGN_UUID: 使用32位的UUID生成主键(主键类型需为字符串)


使用序列自定义主键生成
主键生成策略必须使用
INPUT类型,这意味着主键值需要由用户在插入数据时提供。MyBatis-Plus 支持在父类中定义@KeySequence注解,子类可以继承使用。MyBatis-Plus 内置支持多种数据库的主键生成策略,包括:
- DB2KeyGenerator
- H2KeyGenerator
- KingbaseKeyGenerator
- OracleKeyGenerator
- PostgreKeyGenerator
如果内置的主键生成策略不能满足需求,可以通过实现
IKeyGenerator接口来扩展自定义的主键生成策略。自定义主键生成策略
⚠️:由于mysql中不直接支持序列,因此我们可以创建表+ 函数来模拟序列
创建table,每一行代表一种生成策略
name: 名称
current_value:当前的值
offset:每次增长的值
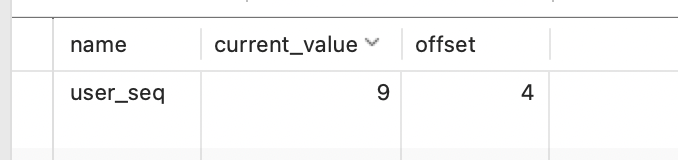
- 创建函数来生成下一个值(传入对应的name)
sqlCREATE DEFINER=`root`@`localhost` FUNCTION `nextval`(seq_name varchar(50)) RETURNS bigint READS SQL DATA DETERMINISTIC SQL SECURITY INVOKER BEGIN DECLARE next_value BIGINT; SELECT current_value + `offset` INTO next_value FROM sequence_table WHERE `name` = seq_name FOR UPDATE; -- 更新当前值 UPDATE sequence_table SET current_value = next_value WHERE name = seq_name; RETURN next_value; END代码中实现
IKeyGenerator接口创建自己的主键生成策略java// 自定义主键生成策略 public class MysqlKeyGenerator implements IKeyGenerator { @Override public String executeSql(String incrementerName) { // 传入对应的name,调用函数获取下一个值 return "select nextval('" + incrementerName + "')"; } @Override public DbType dbType() { return DbType.MYSQL; } } // 配置主键生成策略 @Configuration public class MybatisPlusConfig { @Bean public IKeyGenerator keyGenerator() { return new MysqlKeyGenerator(); } } // 使用KeySequence注解来指定主键生成策略,value就是传入的name @KeySequence(value = "user_seq", dbType = DbType.MYSQL) @TableName(value = "user") @Data public class User implements Serializable { // 必须为INPUT @TableId(type = IdType.INPUT) private Long id; private String name; }
自定义ID生成器
实现
IdentifierGenerator接口,并纳入spring容器管理java@Component public class CustomIdGenerator implements IdentifierGenerator { @Override public Long nextId(Object entity) { long id = (long) (100 + Math.random() * 10000); return id; } }实体类的
TableId注解中type需要指定为ASSIGN_ID(表示分配ID,若没有自己实现的自定义ID生成器,则使用默认的ID生成器:雪花算法生成)java@TableName(value = "user") @Data public class User implements Serializable { @TableId(type = IdType.ASSIGN_ID) private Long id; private String name; }
与KeyGenerator的差异
MyBatis-Plus的IdentifierGenerator主要用于生成数据库表的主键ID,而KeyGenerator是MyBatis框架中的一个接口,用于在执行SQL语句时生成键值,通常用于生成自增主键或者在执行INSERT语句后获取新生成的ID。
IdentifierGenerator更加专注于主键ID的生成,而KeyGenerator则更加通用,可以用于多种键值生成场景。在使用MyBatis-Plus时,通常推荐使用IdentifierGenerator来生成主键ID,因为它与MyBatis-Plus的集成更加紧密,提供了更多的便利性和功能。
分页
首先要配置分页插件
⚠️ 如果配置多个插件, 切记分页最后添加
java
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 如果配置多个插件, 切记分页最后添加
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
// 如果有多数据源可以不配具体类型, 否则都建议配上具体的 DbType
return interceptor;
}
}mp自带的方法分页
javaLambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>(); // 当前页, 每页的大小 IPage<User> userPage = new Page<>(1, 2); // 会将查询的结果自动保存到userPage中 userMapper.selectPage(userPage, lambdaQueryWrapper); System.out.println("当前页:" + userPage.getCurrent()); // 这里可以获取到要查询的记录 System.out.println("当前的记录:" + userPage.getRecords()); System.out.println("分页总数:" + userPage.getPages());对于自己写的mapper方法进行分页
java@Mapper public interface UserMapper extends BaseMapper<User> { // 这里的返回值一定要为IPage及其子类,如果不是IPage及其子类的话,不会讲结果设置到page的Records中 IPage<User> selectLists(IPage<User> userPage); }java// 具体使用起来没什么区别 Page<User> userPage1 = new Page<>(1, 3); userMapper.selectLists(userPage1); System.out.println(userPage1.getRecords());
如果返回类型是 IPage,则入参的 IPage 不能为 null。如果想临时不分页,可以在初始化 IPage 时 size 参数传入小于 0 的值。 如果返回类型是 List,则入参的 IPage 可以为 null,但需要手动设置入参的 IPage.setRecords(返回的 List)。 如果 XML 需要从 page 里取值,需要使用
page.属性获取。
ActiveRecord
⚠️适合一些小项目
使用方法:只需要让实体类继承Model即可
java
public class User extends Model<User> {
}之后可以创建实体类对象,通过实体类对象来进行一些简单的增删改查
java
@Test
public void testActiveRecord() {
User user = new User();
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<User>().gt(User::getAge, 19);
List<User> userList = user.selectList(queryWrapper);
System.out.println(userList);
user.setId(2L);
user.setName("zwc");
// 根据id来判断是插入还是新增,若id为null,或者id已经在表中存在,则更新,否则插入
System.out.println(user.insertOrUpdate());
}SimpleQuery
list
该方法返回一个list,使用实体类的某个属性做为值
java
@Test
public void testSimpleQuery1() {
List<String> list = SimpleQuery.list(
Wrappers.lambdaQuery(User.class),
User::getName,
user -> Optional.ofNullable(user.getName()).map(userName -> userName.toUpperCase()).ifPresentOrElse(user::setName, () -> user.setName("HHHH111")));
System.out.println(list);
}map
该方法返回一个map,实体类的一个值作key,另一个值作value
java
@Test
public void testSimpleQuery_Map() {
// id 为key ,name为value
Map<Long, String> map = SimpleQuery.map(
Wrappers.lambdaQuery(User.class),
User::getId,
User::getName,
user -> Optional.ofNullable(user.getName()).map(String::toUpperCase).ifPresentOrElse(user::setName, () -> user.setName("HHHH111"))
);
for (Map.Entry<Long, String> entry : map.entrySet()) {
System.out.println(String.format("%s:%s", entry.getKey(), entry.getValue()));
}
}keyMap
该方法返回一个map,实体类的一个值为key,实体类为value
java
@Test
public void testSimpleQuery_keyMap() {
Map<String, User> userMap = SimpleQuery.keyMap(
Wrappers.lambdaQuery(User.class),
User::getName,
user -> Optional.ofNullable(user.getName()).map(name -> name + "hhh").ifPresentOrElse(user::setName, () -> user.setName("hhh1"))
);
for (Map.Entry<String ,User> userEntry : userMap.entrySet()) {
System.out.println(String.format("%s:%s",userEntry.getKey(),userEntry.getValue()));
}
}group
该方法可以按照某个字段对数据进行分组,返回一个map,实体类的某个属性做为key,value取决于你函数中的收集器,若没有收集器,则默认为List
⚠️下面这个例子使用了一个收集器,返回的是list的数量,所以最终的map集合的value是Long类型
java
@Test
public void testSimpleQuery_Group() {
Map<String, Long> map = SimpleQuery.group(
Wrappers.lambdaQuery(User.class),
User::getName,
Collectors.counting()
);
for (Map.Entry<String, Long> entry : map.entrySet()) {
System.out.println(String.format("%s有%d个", entry.getKey(), entry.getValue()));
}
}其他
SimpleQuery.listGroupBy();
SimpleQuery.list2List();
SimpleQuery.list2Map()
这几个方法和上面的类似,只是上面的方法中数据是数据库中查询出来的,而这里的数据是传入的list
逻辑删除
- 插入:逻辑删除字段的值不受限制。
- 查找:自动添加条件,过滤掉标记为已删除的记录。
- 更新:防止更新已删除的记录。
- 删除:将删除操作转换为更新操作,标记记录为已删除。
在实体类中配置逻辑删除字段
java@TableLogic(value = "0", delval = "1") private Integer deleted;全局配置逻辑删除字段
ymlmybatis-plus: global-config: db-config: logic-delete-field: deleted logic-not-delete-value: 0 logic-delete-value: 1
枚举类型映射
该注解用于标记枚举类中的字段,指定在数据库中存储的枚举值。当实体类中的某个字段是枚举类型时,使用@EnumValue注解可以告诉MyBatis-Plus在数据库中存储枚举值的哪个属性。
对于mp自动注入的方法,或者自己在xml中写的sql,都生效
java
public enum Gender {
MAN(0), WOMAN(1);
@EnumValue
private Integer key;
Gender(Integer key) {
this.key = key;
}
}java
@Test
public void testEnum() {
// 正常正常转化为枚举
List<User> userList = userMapper.selectList(Wrappers.lambdaQuery());
System.out.println(userList);
User user = new User();
user.setName("zwc11");
user.setGender(Gender.WOMAN);
// 可以正常将枚举转化为数据库中对应的值
userMapper.insert(user);
}类型处理器
mp中默认提供了
Fastjson2TypeHandler、FastjsonTypeHandler、GsonTypeHandler、JacksonTypeHandler这几种类型处理器来处理json数据第一种方式,使用注解配置(只针对mp注入的方法生效)
首先设置
@TableName中的autoResultMap = true在对应字段上设置类型处理器
@TableField(typeHandler = JacksonTypeHandler.class)
java
@TableName(value = "user", autoResultMap = true)
@Data
public class User extends Model<User> implements Serializable {
@TableId(type = IdType.AUTO)
private Long id;
// 上面的tableName注解中一定要设置autoResultMap=true
// 再在对应字段上指定类型处理器
@TableField(typeHandler = JacksonTypeHandler.class)
private Map<String, String> contact;
private static final long serialVersionUID = 1L;
}第二种方式,在xml中配置(针对自己写的sql生效)(可以在mapper中重写mp注入的方法)
xml<resultMap id="BaseResultMap" type="leftover.study_mybatis_plus.pojo.User"> <id property="id" column="id" jdbcType="BIGINT"/> <result property="name" column="name" jdbcType="VARCHAR"/> <result property="age" column="age" jdbcType="INTEGER"/> <result property="email" column="email" jdbcType="VARCHAR"/> <result property="contact" column="contact" jdbcType="VARCHAR" typeHandler="com.baomidou.mybatisplus.extension.handlers.JacksonTypeHandler" /> <!--再设置一下对应的resultMap即可 --> <select id="selects" resultMap="BaseResultMap"> select * from user </select>
自动填充字段
MyBatis-Plus 提供了一个便捷的自动填充功能,用于在插入或更新数据时自动填充某些字段,如创建时间、更新时间等
自动填充只需要实现MetaObjectHandler即可
java
@Slf4j
@Component
public class TimeAutoFillHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
log.info("正在自动填充{}类的createTime和updateTime字段", metaObject.getOriginalObject().getClass().getSimpleName());
//填充createTime和updateTime字段
strictInsertFill(metaObject, "createTime", LocalDateTime.class, LocalDateTime.now(ZoneId.of("UTC")));
strictInsertFill(metaObject, "updateTime", LocalDateTime.class, LocalDateTime.now(ZoneId.of("UTC")));
}
@Override
public void updateFill(MetaObject metaObject) {
log.info("正在自动填充{}类的updateTime字段", metaObject.getOriginalObject().getClass().getSimpleName());
//填充updateTime字段
strictUpdateFill(metaObject, "updateTime", LocalDateTime.class, LocalDateTime.now(ZoneId.of("UTC")));
}
}之后在pojo类的对应的字段上面指定对应的自动填充策略即可
java
@TableName(value = "user")
@Data
public class User extends Model<User> implements Serializable {
@TableId(type = IdType.AUTO)
private Long id;
//指定自动填充的策略
@TableField(fill = FieldFill.INSERT)
private LocalDateTime createTime;
//指定自动填充的策略
@TableField(fill = FieldFill.INSERT_UPDATE)
private LocalDateTime updateTime;
}防止全表更新
添加BlockAttackInnerInterceptor拦截器即可
java
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
//防止全表更新和删除的拦截器
interceptor.addInnerInterceptor(new BlockAttackInnerInterceptor());
// 如果配置多个插件, 切记分页最后添加
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
// 如果有多数据源可以不配具体类型, 否则都建议配上具体的 DbType
return interceptor;
}
}乐观锁插件
我们平常正常的更新逻辑:查询出对应的数据,调用setter更新某个字段的数据,使用update语句更新数据.
在高并发的场景下,我们可以使用乐观锁来保证数据的一致性
原理:当我们先使用了查询,再update时;第一步查询出了版本号,update的时候会将版本号作为条件拼接到update语句的后面,若数据库中的版本号和你查询到的版本号不一致,则不会更新数据
- ⚠️我们可以在数据库中添加一个version字段 ,并使用
@Version注解标注
java
@TableName(value = "user")
@Data
public class User extends Model<User> implements Serializable {
@TableId(type = IdType.AUTO)
private Long id;
private String name;
@TableField(fill = FieldFill.INSERT)
private LocalDateTime createTime;
@TableField(fill = FieldFill.INSERT_UPDATE)
private LocalDateTime updateTime;
@Version
private Integer version;
}- 添加乐观锁的插件
java
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 乐观锁插件
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
// 如果配置多个插件, 切记分页最后添加
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
// 如果有多数据源可以不配具体类型, 否则都建议配上具体的 DbType
return interceptor;
}
}3.Test
java
@Test
public void testLeGuanSuo() {
LambdaUpdateWrapper<User> wrapper = new LambdaUpdateWrapper<>();
wrapper.eq(User::getId, 4);
User user1 = userMapper.selectOne(wrapper);
new Thread(new Runnable() {
@Override
public void run() {
User user = userMapper.selectOne(wrapper);
user.setName("qqqq");
userMapper.update(user, wrapper);
}
}).run();
user1.setName("uuu");
userMapper.update(user1, wrapper);
}SQL分析打印
可以在控制台打印输出每个sql的执行时间,便于我们分析sql的性能
⚠️该插件可能会带来性能损耗,不建议在生产环境中使用。
详见https://baomidou.com/guides/p6spy/
- 引入依赖
xml
<dependency>
<groupId>com.github.gavlyukovskiy</groupId>
<artifactId>p6spy-spring-boot-starter</artifactId>
<version>1.9.1</version>
</dependency>修改驱动类和连接数据库的url
yml# url: jdbc:mysql://localhost:3306/study_mybatis_plus?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true url: jdbc:p6spy:mysql://localhost:3306/study_mybatis_plus?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true # driver-class-name: com.mysql.cj.jdbc.Driver driver-class-name: com.p6spy.engine.spy.P6SpyDriver配置文件
properties# spy.properties modulelist=com.baomidou.mybatisplus.extension.p6spy.MybatisPlusLogFactory,com.p6spy.engine.outage.P6OutageFactory # 自定义日志打印 logMessageFormat=com.baomidou.mybatisplus.extension.p6spy.P6SpyLogger #日志输出到控制台 appender=com.baomidou.mybatisplus.extension.p6spy.StdoutLogger # 使用日志系统记录 sql #appender=com.p6spy.engine.spy.appender.Slf4JLogger # 设置 p6spy driver 代理 deregisterdrivers=true # 取消JDBC URL前缀 useprefix=true # 配置记录 Log 例外,可去掉的结果集有error,info,batch,debug,statement,commit,rollback,result,resultset. excludecategories=info,debug,result,commit,resultset # 日期格式 dateformat=yyyy-MM-dd HH:mm:ss # 实际驱动可多个 #driverlist=org.h2.Driver # 是否开启慢SQL记录 outagedetection=true # 慢SQL记录标准 2 秒 outagedetectioninterval=2
多数据源
- 导入对应的依赖
xml
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot3-starter</artifactId>
<version>4.2.0</version>
</dependency>在yml中配置对应的数据源配置
ymlspring: datasource: dynamic: aop: enabled: true # 默认使用master数据源 primary: master #严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源 strict: false datasource: # 定义master数据源 master: url: jdbc:p6spy:mysql://localhost:3306/study_mybatis_plus?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true username: root password: zwc666666 driver-class-name: com.p6spy.engine.spy.P6SpyDriver # 定义salve数据源 salve: url: jdbc:mysql://localhost:3306/study_mybatis_plus1?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true username: root password: zwc666666 driver-class-name: com.mysql.cj.jdbc.Driver在代码中使用
@DS注解指定数据源,若不指定则使用默认的数据源。⚠️该注解可以使用在方法和类上,若同时存在,则遵循就近原则(方法上的生效)
java
@DS("salve")
User selectByIdByDs();流式查询
在 MyBatis 中,通过 ResultHandler 接口实现结果集的流式查询可以有效地处理大数据量的查询(一条一条地处理数据),避免一次性加载全部结果到内存中,从而降低内存消耗和提高查询性能
- 自己写的sql实现流式查询
java
@Mapper
public interface UserMapper extends BaseMapper<User> {
void selectAll(ResultHandler<User> handler);
}java
@Test
public void test流式查询() {
// 自己写的sql使用流式查询
userMapper.selectAll(resultContext -> {
User user = resultContext.getResultObject();
System.out.println(user);
});
}mybatis-plus注入的方法使用流式查询
java@Test public void test流式查询() { // mybatis-plus注入的方法使用流式查询 userMapper.selectList(Wrappers.emptyWrapper(), resultContext -> { User user = resultContext.getResultObject(); System.out.println(user); }); }
批量操作
批量插入
- java
ArrayList<User> users = new ArrayList<>(); for (int i = 0; i < 10; i++) { User user = new User(); user.setName("zwc000" + i); users.add(user); } MybatisBatch<User> batch = new MybatisBatch<User>(sqlSessionFactory, users); MybatisBatch.Method<User> method = new MybatisBatch.Method<User>(UserMapper.class); batch.execute(method.insert()); - 使用自定义方法插入
java
ArrayList<User> users = new ArrayList<>();
for (int i = 0; i < 10; i++) {
User user = new User();
user.setName("zwc" + i);
users.add(user);
}
MybatisBatch<User> batch = new MybatisBatch<User>(sqlSessionFactory, users);
MybatisBatch.Method<User> method = new MybatisBatch.Method<User>(UserMapper.class);
batch.execute(method.get("insertUser"));批量删除
java
@Test
public void 批量删除() {
List<Long> ids = new ArrayList<>();
for (Long i = 2357L; i <= 2366L; i++) {
ids.add(i);
}
MybatisBatch<Long> batch = new MybatisBatch<>(sqlSessionFactory, ids);
MybatisBatch.Method<Object> method = new MybatisBatch.Method<>(UserMapper.class);
batch.execute(method.deleteById());
}批量插入或者更新
java
@Test
public void 批量更新或者插入() {
ArrayList<User> users = new ArrayList<>();
for (int i = 0; i < 10; i++) {
User user = new User();
user.setName("zwc001110" + i);
user.setId(2373L + i);
users.add(user);
}
MybatisBatch<User> batch = new MybatisBatch<User>(sqlSessionFactory, users);
MybatisBatch.Method<User> method = new MybatisBatch.Method<User>(UserMapper.class);
batch.saveOrUpdate(
method.insert(), // 插入的方法
// 判断是否为insert
(batchSqlSession, user) -> {
User user1 = userMapper.selectById(user.getId());
return user1 == null;
},
method.updateById());// 更新的方法
}多租户
隔离方案
多租户在数据隔离存储方案上,一般有三种实施方案:
- 独立数据库
- 共享数据库、独立Schema
- 共享数据库、共享Schema、共享表
每种方案的优缺点
独立数据库
每个租户使用独立的数据库,这种方案类似于传统的部署,其区别在于多租户的实现是将每个租户的数据库都统一管理起来。这种一租户一数据库的方案优缺点都很明显:
优点
- 数据隔离性好,安全级别高;
- 数据库表不需要额外的字段来区分租户;
- 需求扩展独立性好,不影响其他租户的使用;
- 出现故障时,恢复数据简单。
缺点
- 增加了数据库的安装数量和安装成本;
- 支持租户的数量有限;
- 跨租户统计数据较困难;
- 新增租户需要重启服务。
应用场景
适用于定价高,安全级别要求高的租户。例如,银行、医院等对数据隔离性有严格要求的租户。这些租户的特点是租户较少,数据规模大,数据隔离性强。
共享数据库、独立Schema
每个租户共享同一个数据库,但使用的是不同的Schema。像Oracle和PgSql都支持一个数据库下多个Schema。
优点
- 数据隔离性较好。为每个租户提供了一定程度上的逻辑隔离;
- 相较于独立数据库方案,可以支持的租户数量更多;
- 安装成本相对较低。
缺点
- 跨租户统计数据较困难;
- 各个租户的数据库sql需要带上Schema名称。
应用场景
适用于数据规模中等,租户数量中等的项目。
共享数据库、共享Schema、共享表
每个租户共享同一个数据库,同一个Schema,甚至是同一张表。每个表里都有一个tenant_id字段用来区分表里的记录是来自于哪一个租户。这种多租户方案是三个方案里隔离级别最低但是共享程度最高的一个。
优点
- 安装成本最低;
- 支持的租户数量最多;
- 添加租户不需要重启服务;
- 跨租户统计较容易。
缺点
- 安全性最差,隔离级别最低;
- 维护成本最高。其成本体现在表设计需要额外字段,sql代码需要额外查询条件,故障后数据恢复需要额外操作;
- 每个租户的数据量规模不宜较大。
应用场景
适用于低成本,租户数量多,租户数据量小,对安全性和隔离级别要求低的产品。例如一些To C的产品
使用mp的多租户插件实现第三种多租户方式
- 添加springmvc拦截器,判断请求头中有没有
tenantId,没有则报错返回400,有则将其设置到TenantContext中
java
public class TenantContext {
private static final ThreadLocal<String> currentTenant = new InheritableThreadLocal<>();
public static String getCurrentTenant() {
return currentTenant.get();
}
public static void setCurrentTenant(String tenantId) {
currentTenant.set(tenantId);
}
public static void clear() {
currentTenant.remove();
}
}
@Configuration
public class SpringMvcConfig implements WebMvcConfigurer {
// 添加springmvc的拦截器
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new TenantInterceptor()).addPathPatterns("/**");
}
}
//springmvc的拦截器
public class TenantInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String tenantId = request.getHeader("tenantId");
if (tenantId == null) {
response.sendError(HttpStatus.BAD_REQUEST.value(),"tenantId 不存在");
}
TenantContext.setCurrentTenant(tenantId);
return true;
}
}- 配置mp中的多租户插件
java
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 多租户的插件
interceptor.addInnerInterceptor(new TenantLineInnerInterceptor(new CustomTenantHandler()));
// 如果配置多个插件, 切记分页最后添加
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
// 如果有多数据源可以不配具体类型, 否则都建议配上具体的 DbType
return interceptor;
}
class CustomTenantHandler implements TenantLineHandler {
// 获取tenantId
@Override
public Expression getTenantId() {
return new StringValue(TenantContext.getCurrentTenant());
}
// 配置TenantId在数据库中的列名是啥,默认为tenant_id
@Override
public String getTenantIdColumn() {
return TenantLineHandler.super.getTenantIdColumn();
}
// 配置哪些表不需要使用这个多租户插件
@Override
public boolean ignoreTable(String tableName) {
return TenantLineHandler.super.ignoreTable(tableName);
}
// 忽略插入租户字段逻辑(默认即可)
@Override
public boolean ignoreInsert(List<Column> columns, String tenantIdColumn) {
return TenantLineHandler.super.ignoreInsert(columns, tenantIdColumn);
}
}
}- 进行查询,更新,删除的时候都会在where后面添加tenant_id的逻辑(有点类似逻辑删除一样)
数据权限管理插件
DataPermissionInterceptor 是 MyBatis-Plus 提供的一个插件,用于实现数据权限控制。它通过拦截执行的 SQL 语句,并动态拼接权限相关的 SQL 片段,来实现对用户数据访问的控制。
java
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
// 数据权限管理插件
interceptor.addInnerInterceptor(new DataPermissionInterceptor(new CustomDataPermissionHandler()));
// 如果配置多个插件, 切记分页最后添加
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
// 如果有多数据源可以不配具体类型, 否则都建议配上具体的 DbType
return interceptor;
}
// 数据权限处理器
class CustomDataPermissionHandler implements MultiDataPermissionHandler {
@Override
public Expression getSqlSegment(Table table, Expression where, String mappedStatementId) {
try {
Expression expression = CCJSqlParserUtil.parseCondExpression("role='admin'");
return expression;
} catch (JSQLParserException e) {
throw new RuntimeException(e);
}
}
}
}动态表名插件
在数据库应用程序开发中,我们有时需要根据不同的条件查询不同的表。MyBatis-Plus 提供了一个动态表名插件 DynamicTableNameInnerInterceptor,它允许我们在运行时动态地改变 SQL 语句中的表名,这对于处理分表逻辑非常有用。
下面的实现了随机选择user1或者user2表进行crud
java
@Configuration
public class MybatisPlusConfig {
private static final Logger log = LoggerFactory.getLogger(MybatisPlusConfig.class);
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 动态表名插件
interceptor.addInnerInterceptor(new DynamicTableNameInnerInterceptor(new CustomTableNameHandler()));
// 如果配置多个插件, 切记分页最后添加
// 如果有多数据源可以不配具体类型, 否则都建议配上具体的 DbType
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
class CustomTableNameHandler implements TableNameHandler {
@Override
public String dynamicTableName(String sql, String tableName) {
int num = (int) (Math.random() * 9);
log.info("数字为{}", num);
String flag;
if (num > 5) {
flag = "1";
} else {
flag = "2";
}
return tableName + flag;
}
}
}数据变动记录插件
在数据库操作中,记录数据变动和控制操作的安全性是非常重要的。MyBatis-Plus 提供了一个数据变动记录插件 DataChangeRecorderInnerInterceptor,它不仅能够自动记录操作日志,还支持安全阈值控制,例如限制批量更新或插入的数量。
java
@Configuration
public class MybatisPlusConfig {
private static final Logger log = LoggerFactory.getLogger(MybatisPlusConfig.class);
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 数据变动记录插件
DataChangeRecorderInnerInterceptor dataChangeRecorderInnerInterceptor = new CustomDataChangeRecorderInnerInterceptor();
// 限制批量更新/插入最多1000条
dataChangeRecorderInnerInterceptor.setBatchUpdateLimit(1000);
interceptor.addInnerInterceptor(dataChangeRecorderInnerInterceptor);
// 如果配置多个插件, 切记分页最后添加
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
// 如果有多数据源可以不配具体类型, 否则都建议配上具体的 DbType
return interceptor;
}
// 数据变动记录插件默认是在控制台打印数据变动记录信息,可以重写dealOperationResult方法,将对应的日志保存到数据库
class CustomDataChangeRecorderInnerInterceptor extends DataChangeRecorderInnerInterceptor {
@Override
protected void dealOperationResult(OperationResult operationResult) {
System.out.println("customDealOperationResult" + operationResult);
}
}
}非法SQL拦截插件
- 拦截SQL类型场景:插件能够识别并拦截特定类型的SQL语句,如全表更新、删除等高风险操作。
- 强制使用索引:确保在执行查询时使用索引,以提高性能并避免全表扫描。
- 全表更新操作检查:防止未经授权的全表更新或删除操作,减少数据丢失风险。
not、or、子查询检查:对包含not、or关键字或子查询的SQL语句进行额外检查,以防止逻辑错误或性能问题。
java
interceptor.addInnerInterceptor(new IllegalSQLInnerInterceptor());文章作者:leftover
版权声明: 所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 leftover!